A Guidebook for C++1X
语言可用性强化
类型推导
- auto
for (auto it = magicFoo.vec.begin(); it != magicFoo.vec.end(); ++it) {
std::cout << *it << ", "; // 迭代器使用auto
}
auto i = 5; // i 被推导为 int
auto arr = new auto(10); // arr 被推导为 int *
注意: auto 不能用于函数传参,因此下面的做法是无法通过编译的(主要是以为保留重载)
int add(auto x, auto y);
2.6.auto.cpp:16:9: error: 'auto' not allowed in function prototype
int add(auto x, auto y) {
^~~~
注意: auto 还不能用于推导数组类型
auto auto_arr2[10] = {arr}; // 错误, 无法推导数组元素类型
2.6.auto.cpp:30:19: error: 'auto_arr2' declared as array of 'auto'
auto auto_arr2[10] = {arr};
- decltype
类似 typeof
decltype(表达式)
std::is_same<T, U> 用于判断 T 和 U 这两个类型是否相等
// 判断 变量 x, y, z 是否是同一类型。
int main() {
auto x = 1;
auto y = 2;
decltype(x+y) z; //声明一个x+y同类型的变量z
if (std::is_same<decltype(x), int>::value)
std::cout << "type x == int" << std::endl;
if (std::is_same<decltype(x), float>::value)
std::cout << "type x == float" << std::endl;
if (std::is_same<decltype(x), decltype(z)>::value)
std::cout << "type z == type x" << std::endl;
return 0;
}
- 尾返回类型推导
以下函数定义了返回x+y类型的值
template<typename T, typename U>
auto add2(T x, U y) -> decltype(x+y){
return x + y;
}
#include <iostream>
template<typename T, typename U>
auto add2(T x, U y) -> decltype(x+y){
return x + y;
}
template<typename T, typename U>
auto add3(T x, U y){
return x + y;
}
int main(){
// after c++11
auto w = add2<int, double>(1, 2.0);
if (std::is_same<decltype(w), double>::value) {
std::cout << "w is double: ";
}
std::cout << w << std::endl;
// after c++14
auto q = add3<double, int>(1.0, 2);
if (std::is_same<decltype(q), double>::value) {
std::cout << "q is double: ";
}
std::cout << q << std::endl;
}
std::initializer_list 统一初始化
vector<int> a {1,2,3,4};
int arr[3] {1,2,3};
class c = {1,2,3}
#include <initializer_list>
#include <iostream>
#include <vector>
class MagicFoo {
public:
std::vector<int> vec;
MagicFoo(std::initializer_list<int> list) {
for (std::initializer_list<int>::iterator it = list.begin();
it != list.end(); ++it)
vec.push_back(*it);
}
// 列表初始化也可以作为普通函数参数
void foo(std::initializer_list<int> list) {
for (std::initializer_list<int>::iterator it = list.begin(); it != list.end(); ++it) vec.push_back(*it);
}
};
int main() {
// after C++11
MagicFoo magicFoo = {1, 2, 3, 4, 5};
std::cout << "magicFoo: ";
for (std::vector<int>::iterator it = magicFoo.vec.begin(); it != magicFoo.vec.end(); ++it) std::cout << *it << std::endl;
}
结构化绑定(允许多返回值)
#include <iostream>
#include <tuple>
std::tuple<int, double, std::string> f() {
return std::make_tuple(1, 2.3, "456");
}
int main() {
auto [x, y, z] = f();
std::cout << x << ", " << y << ", " << z << std::endl;
return 0;
}
区间for迭代
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> vec = {1, 2, 3, 4};
for (auto element : vec)
std::cout << element << std::endl; // read only
for (auto &element : vec) {
element += 1; // writeable
}
}
using 取代 typedef
typedef int MyInt;
using MyInt = int;
using TrueDarkMagic = MagicType<int, int>;
int main() {
TrueDarkMagic<bool> you;
}
默认模版参数
template<typename T = int, typename U = int>
auto add(T x, U y) -> decltype(x+y) {
return x+y;
}
// Call add function
auto ret = add(1,3);
变长参数表、模版
template<typename... Ts> class Magic;
class Magic<int,
std::vector<int>,
std::map<std::string,
std::vector<int>>> darkMagic;
template<typename... Ts>
void magic(Ts... args) {
std::cout << sizeof...(args) << std::endl;
}
解包
- 计算参数表长
template<typename... Ts>
void magic(Ts... args) {
std::cout << sizeof...(args) << std::endl;
}
- 递归模版函数
#include <iostream> template<typename T0> void printf1(T0 value) { std::cout << value << std::endl; } template<typename T, typename... Ts> void printf1(T value, Ts... args) { std::cout << value << std::endl; printf1(args...); } int main() { printf1(1, 2, "123", 1.1); return 0; } - 变参模版展开 c++17
template<typename T0, typename... T> void printf2(T0 t0, T... t) { std::cout << t0 << std::endl; if constexpr (sizeof...(t) > 0) printf2(t...); } - 初始化列表展开
template<typename T, typename... Ts> auto printf3(T value, Ts... args) { std::cout << value << std::endl; (void) std::initializer_list<T>{([&args] { std::cout << args << std::endl; }(), value)...}; }
折叠表达式
- 计算和
#include <iostream> template<typename ... T> auto sum(T ... t) { return (t + ...); } int main() { std::cout << sum(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) << std::endl; } - 计算均值
#include <iostream> template<typename ... T> auto average(T ... t) { return (t + ... ) / sizeof...(t); } int main() { std::cout << average(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) << std::endl; }
非类型模版参数&其自动推导
- 非类型模版参数 ```c++ template <typename T, int BufSize> class buffer_t { public: T& alloc(); void free(T& item); private: T data[BufSize]; }
buffer_t<int, 100> buf; // 100 作为模板参数
- 自动推导
```c++
template <auto value> void foo() {
std::cout << value << std::endl;
return;
}
int main() {
foo<10>(); // value 被推导为 int 类型
}
构造
委托构造
#include <iostream>
class Base {
public:
int value1;
int value2;
Base() {
value1 = 1;
}
Base(int value) : Base() { // 委托 Base() 构造函数
value2 = value;
}
};
int main() {
Base b(2);
std::cout << b.value1 << std::endl;
std::cout << b.value2 << std::endl;
}
继承构造
#include <iostream>
class Base {
public:
int value1;
int value2;
Base() {
value1 = 1;
}
Base(int value) : Base() { // 委托 Base() 构造函数
value2 = value;
}
};
class Subclass : public Base {
public:
using Base::Base; // 继承构造
};
int main() {
Subclass s(3);
std::cout << s.value1 << std::endl;
std::cout << s.value2 << std::endl;
}
运行时强化
lambda表达式
Lambda 表达式,实际上就是提供了一个类似匿名函数的特性,而匿名函数则是在需要一个函数,但是又不想费力去命名一个函数的情况下去使用的。这样的场景其实有很多很多,所以匿名函数几乎是现代编程语言的标配。
基本语法:
[捕获列表](参数列表) mutable(可选) 异常属性 -> 返回类型 {
// 函数体
}
捕获
所谓捕获列表,其实可以理解为参数的一种类型,Lambda 表达式内部函数体在默认情况下是不能够使用函数体外部的变量的,这时候捕获列表可以起到传递外部数据的作用。
- [] 空捕获列表
- [name1, name2, …] 捕获一系列变量
- [&] 引用捕获, 让编译器自行推导引用列表
- [=] 值捕获, 让编译器自行推导值捕获列表
- 表达式捕获 上面提到的值捕获、引用捕获都是已经在外层作用域声明的变量,因此这些捕获方式捕获的均为左值,而不能捕获右值。
C++14 给与了我们方便,允许捕获的成员用任意的表达式进行初始化,这就允许了右值的捕获,被声明的捕获变量类型会根据表达式进行判断,判断方式与使用 auto 本质上是相同的
#include <iostream>
#include <utility>
int main() {
auto important = std::make_unique<int>(1);
auto add = [v1 = 1, v2 = std::move(important)](int x, int y) -> int {
return x+y+v1+(*v2);
};
std::cout << add(3,4) << std::endl;
return 0;
}
特例:
与参数传值类似,值捕获的前提是变量可以拷贝,不同之处则在于,被捕获的变量在 Lambda 表达式被创建时拷贝,而非调用时才拷贝
void lambda_value_capture() { int value = 1; auto copy_value = [value] { return value; }; value = 100; auto stored_value = copy_value(); std::cout << "stored_value = " << stored_value << std::endl; // 这时, stored_value == 1, 而 value == 100. // 因为 copy_value 在创建时就保存了一份 value 的拷贝 }与引用传参类似,引用捕获保存的是引用,值会发生变化。
void lambda_reference_capture() { int value = 1; auto copy_value = [&value] { return value; }; value = 100; auto stored_value = copy_value(); std::cout << "stored_value = " << stored_value << std::endl; // 这时, stored_value == 100, value == 100. // 因为 copy_value 保存的是引用 }
- 泛型 Lambda
auto类型在c++14中可以变成参数类型
auto add = [](auto x, auto y) {
return x+y;
};
add(1, 2);
add(1.1, 2.2);
函数对象包装器 std::function
C++11 std::function 是一种通用、多态的函数封装,它的实例可以对任何可以调用的目标实体进行存储、复制和调用操作,它也是对 C++ 中现有的可调用实体的一种类型安全的包裹(相对来说,函数指针的调用不是类型安全的),换句话说,就是函数的容器。
#include <functional>
#include <iostream>
int foo(int para) {
return para;
}
int main() {
// std::function 包装了一个返回值为 int, 参数为 int 的函数
std::function<int(int)> func = foo;
// function<返回类型列表(参数类型列表)>
int important = 10;
std::function<int(int)> func2 = [&](int value) -> int {
return 1+value+important;
};
std::cout << func(10) << std::endl;
std::cout << func2(10) << std::endl;
return 0;
}
std::function<double(int, int)> func = [](int a, int b) -> double {
// 在这里编写函数体
return a * b * 0.5;
};
std::bind & std::placeholder
std::bind 则是用来绑定函数调用的参数的,它解决的需求是我们有时候可能并不一定能够一次性获得调用某个函数的全部参数,通过这个函数,我们可以将部分调用参数提前绑定到函数身上成为一个新的对象,然后在参数齐全后,完成调用。
#include <iostream>
#include <functional>
int foo(int a, int b, int c) {
return a+b+c;
}
int main() {
// 将参数1,2绑定到函数 foo 上,但是使用 std::placeholders::_1 来对第一个参数进行占位
auto bindFoo = std::bind(foo, std::placeholders::_1, 1,2);
// 这时调用 bindFoo 时,只需要提供第一个参数即可
bindFoo(1);
std::cout << bindFoo(1) << std::endl;
return 0;
}
#include <iostream>
#include <functional>
int foo(int a, int b, int c) {
return a+b+c;
}
int main() {
// 将参数1,2绑定到函数 foo 上,但是使用 std::placeholders::_1 来对第一个参数进行占位
auto bindFoo = std::bind(foo, std::placeholders::_1, std::placeholders::_2,2);
// 这时调用 bindFoo 时,只需要提供第一个参数即可
bindFoo(2,4);
std::cout << bindFoo(3,4) << std::endl;
return 0;
}
右值引用
右值引用是 C++11 引入的与 Lambda 表达式齐名的重要特性之一。它的引入解决了 C++ 中大量的历史遗留问题,消除了诸如 std::vector、std::string 之类的额外开销,也才使得函数对象容器 std::function 成为了可能。
左值(lvalue, left value),顾名思义就是赋值符号左边的值。准确来说,左值是表达式(不一定是赋值表达式)后依然存在的持久对象。可以取地址。
右值(rvalue, right value),右边的值,是指表达式结束后就不再存在的临时对象。不可以取地址。在C++11标准中具体分为:
-
纯右值(prvalue, pure rvalue)
纯粹的右值,要么是纯粹的字面量,例如
10,true;要么是求值结果相当于字面量或匿名临时对象,例如1+2。非引用返回的临时变量、运算表达式产生的临时变量、原始字面量、Lambda 表达式都属于纯右值。注意: 字符串字面量只有在类中才是右值,当其位于普通函数中是左值。
-
将亡值(xvalue, expiring value)
临时的值能够被识别、同时又能够被移动。
右值引用语法
T && t = xxx
// 其中 T 是类型。右值引用的声明让这个临时值的生命周期得以延长、只要变量还活着,那么将亡值将继续存活。
// 一个声明的右值引用其实是一个左值,所以t是左值。
左值转右值
std::move()
// C++11标准,这个方法将左值参数无条件的转换为右值,有了它我们就能够方便的获得一个右值临时对象
- eg.
#include <iostream>
#include <string>
void reference(std::string& str) {
std::cout << "左值" << std::endl;
}
void reference(std::string&& str) {
std::cout << "右值" << std::endl;
}
int main()
{
std::string lv1 = "string,"; // lv1 是一个左值
// std::string&& r1 = lv1; // 非法, 右值引用不能引用左值
std::string&& rv1 = std::move(lv1); // 合法, std::move可以将左值转移为右值
std::cout << rv1 << std::endl; // string,
const std::string& lv2 = lv1 + lv1; // 合法, 常量左值引用能够延长临时变量的生命周期
// lv2 += "Test"; // 非法, 常量引用无法被修改
std::cout << lv2 << std::endl; // string,string,
std::string&& rv2 = lv1 + lv2; // 合法, 右值引用延长临时对象生命周期
rv2 += "Test"; // 合法, 非常量引用能够修改临时变量
std::cout << rv2 << std::endl; // string,string,string,Test
reference(rv2); // 输出左值
return 0;
}
移动语义
『移动』和『拷贝』:
传统 C++ 通过拷贝构造函数和赋值操作符为类对象设计了拷贝/复制的概念,但为了实现对资源的移动操作,调用者必须使用先复制、再析构的方式,否则就需要自己实现移动对象的接口。试想,搬家的时候是把家里的东西直接搬到新家去,而不是将所有东西复制一份(重买)再放到新家、再把原来的东西全部扔掉(销毁),这是非常反人类的一件事情。
- eg.
#include <iostream>
class A {
public:
int *pointer;
A():pointer(new int(1)) {
std::cout << "构造" << pointer << std::endl;
}
A(A& a):pointer(new int(*a.pointer)) {
std::cout << "拷贝" << pointer << std::endl;
} // 无意义的对象拷贝
A(A&& a):pointer(a.pointer) {
a.pointer = nullptr;
std::cout << "移动" << pointer << std::endl;
}
~A(){
std::cout << "析构" << pointer << std::endl;
delete pointer;
}
};
// 防止编译器优化
A return_rvalue(bool test) {
A a,b;
if(test) return a; // 等价于 static_cast<A&&>(a);
else return b; // 等价于 static_cast<A&&>(b);
}
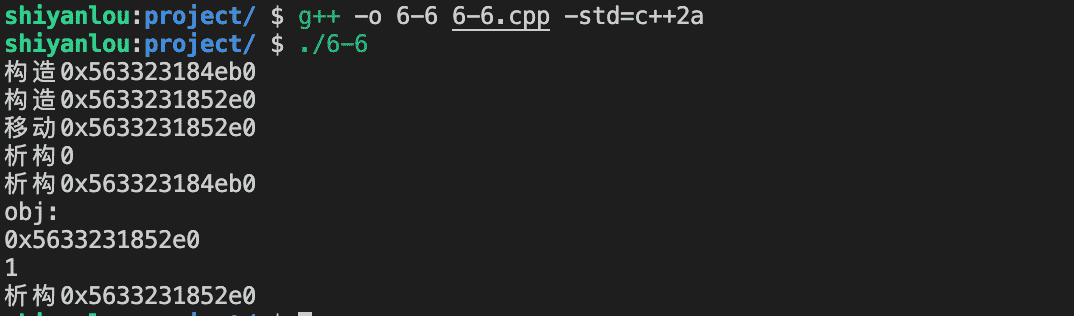
int main() {
A obj = return_rvalue(false);
std::cout << "obj:" << std::endl;
std::cout << obj.pointer << std::endl;
std::cout << *obj.pointer << std::endl;
return 0;
}
1) 在
return_rvalue内部,先后构造了a,b两个A的实例,所以第一第二行为构造a,b是调用的构造函数。 2) 由于传入的值为false,实例b作为函数返回值,被移动到obj中,第三行调用b的移动构造函数。 3) 函数return_rvalue执行完毕,按照逆序析构的原则,先析构b, 再析构a,由于b已经被移动,此时它的pointer为nullptr(将亡值的指针被设置为nullptr,防止了这块内存区域被销毁),所以析构打印对应的值为0,即第四、五行分别是b和a的析构。 4) 接着是打印obj对应的信息。 5) 最后一行是在整个程序结束前,隐式地调用了obj的析构函数,因为之前b的pointer被移动赋值给了obj,所以对obj析构的pointer为之前b构造时的pointer。
- eg2:
#include <iostream> // std::cout
#include <utility> // std::move
#include <vector> // std::vector
#include <string> // std::string
int main() {
std::string str = "Hello world.";
std::vector<std::string> v;
// 将使用 push_back(const T&), 即产生拷贝行为
v.push_back(str);
// 将输出 "str: Hello world."
std::cout << "str: " << str << std::endl;
// 将使用 push_back(const T&&), 不会出现拷贝行为
// 而整个字符串会被移动到 vector 中,所以有时候 std::move 会用来减少拷贝出现的开销
// 这步操作后, str 中的值会变为空
v.push_back(std::move(str));
// 将输出 "str: "
std::cout << "str: " << str << std::endl;
return 0;
}
完美转发std::forward & 引用坍缩规则
一个声明的右值引用其实是一个左值。进行参数转发(传递)要保持值的类型需要用完美转发。
- 引用坍缩规则
| 函数形参类型 | 实参参数类型 | 推导后函数形参类型 |
|---|---|---|
| T& | 左引用 | T& |
| T& | 右引用 | T& |
| T&& | 左引用 | T& |
| T&& | 右引用 | T&& |
#include <iostream>
void reference(int& v) {
std::cout << "左值" << std::endl;
}
void reference(int&& v) {
std::cout << "右值" << std::endl;
}
template <typename T>
void pass(T&& v) {
std::cout << "普通传参:";
reference(v); // 始终调用 reference(int&)
}
int main() {
std::cout << "传递右值:" << std::endl;
pass(1); // 1是右值, 但输出是左值,因为右值引用v是一个左值(除非用完美转发保持类型)
std::cout << "传递左值:" << std::endl;
int l = 1;
pass(l); // l 是左值, 输出左值
return 0;
}
// 在这个例子中,两次输出都为左值。pass(l)能调用就是因为引用坍缩规则
- 完美转发
#include <iostream>
#include <utility>
void reference(int& v) {
std::cout << "左值引用" << std::endl;
}
void reference(int&& v) {
std::cout << "右值引用" << std::endl;
}
template <typename T>
void pass(T&& v) {
std::cout << " 普通传参: ";
reference(v);
std::cout << " std::move 传参: ";
reference(std::move(v));
std::cout << " std::forward 传参: ";
reference(std::forward<T>(v));
std::cout << "static_cast<T&&> 传参: ";
reference(static_cast<T&&>(v));
}
int main() {
std::cout << "传递右值:" << std::endl;
pass(1);
std::cout << "传递左值:" << std::endl;
int v = 1;
pass(v);
return 0;
}
/////////////////
传递右值:
普通传参: 左值引用
std::move 传参: 右值引用
std::forward 传参: 右值引用
static_cast<T&&> 传参: 右值引用
传递左值:
普通传参: 左值引用
std::move 传参: 右值引用
std::forward 传参: 左值引用
static_cast<T&&> 传参: 左值引用
从现象上来看,std::forward<T>(v) 和 static_cast<T&&>(v) 是完全一样的。
为什么在使用循环语句的过程中,auto&& 是最安全的方式?因为当 auto 被推导为不同的左右引用时,与 && 的坍缩组合是完美转发。
std::forward实现原理
template<typename _Tp>
constexpr _Tp&& forward(typename std::remove_reference<_Tp>::type& __t) noexcept
{ return static_cast<_Tp&&>(__t); }
template<typename _Tp>
constexpr _Tp&& forward(typename std::remove_reference<_Tp>::type&& __t) noexcept
{
static_assert(!std::is_lvalue_reference<_Tp>::value, "template argument"
" substituting _Tp is an lvalue reference type");
return static_cast<_Tp&&>(__t);
}
一个lambda函数的应用例子:
更新map中的value为hash(key)
#include <iostream>
#include <map>
#include <string>
#include <functional>
template <typename Key, typename Value, typename F>
void update(std::map<Key, Value>& m, F foo) {
for (auto&& [key, value] : m)m[key]=foo(key);
}
int main() {
std::map<std::string, long long int> m {
{"a", 1},
{"b", 2},
{"c", 3}
};
update(m, [](std::string key) -> long long int {
return std::hash<std::string>{}(key);
});
for (auto&& [key, value] : m)
std::cout << key << ":" << value << std::endl;
return 0;
}