[TOC]
Abs
首先,on-device inference是好的:
- preserving user data privacy
- avoiding network roundtrips
但是,LLM太大了 => stresses both latency and memory, creating a tension between the two key resources of a mobile device (这说明不是装不下,而是存在一个trade off):
- 一个app的memory footprint增大几倍,在内存回收之前只能利用少数inferences
- 加载IO长达几秒,IO和计算的偏差造成无法利用pipeline去hide IO
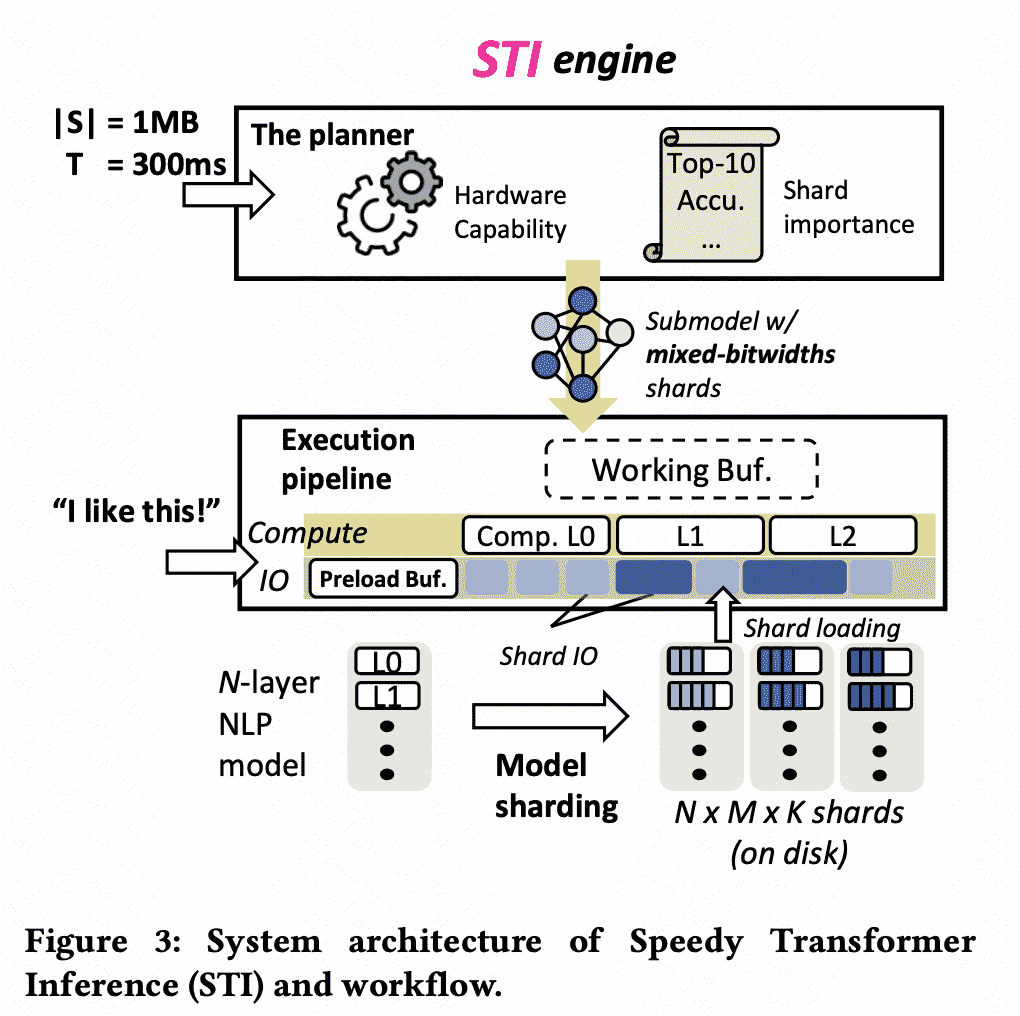
Idea:maximizing IO/compute resource utilization on the most important parts of a model => reconcile 内存/延迟 tensions
Solution:
- model sharding(模型按重要性分片)
- elastic pipeline planning with a preload buffer
Intro
先前有的方法就是(1)Hold in memory(2)Load on demand。前者消耗内存大,会被OS kill;后者IO延迟过大;
主流解决方法是IO-load/compute组成的流水线,但是不行,因为在NLP model(LLM)里面compute intensity太低(其实就是需要load的大但是计算少),所以有pipeline bubbles
还有一个在challenge中review的方法,model compression;但是这个方法(1)会造成精度损失(2)本质上并没有解决bubbles(3)需要re-training
这些方法都有以下几个drawbacks:
- memory-preload和IO-compute不协同
- model的parameter importance不透明
解决方法:
- resource-elastic shards:储存不同精度shards
- Preload shards for warming up pipeline:有个buffer存头部layers
- A joint planner for memory:根据目标latency调度shards

Method
Exp
Setup
这里有一个关于satisfying response time的研究1
Related Work
边缘异构设备pipeline2
Reference
-
Xiantao Chen, Moli Zhou, Renzhen Wang, Yalin Pan, Jiaqi Mi, Hui Tong, and Daisong Guan. 2019. Evaluating Response Delay of Multimodal Interface in Smart Device. In Design, User Experience, and Usability. Practice and Case Studies - 8th International Conference, DUXU 2019, Held as Part of the 21st HCI International Conference, HCII 2019, Orlando, FL, USA, July 26-31, 2019, Proceedings, Part IV (Lecture Notes in Computer Science, Vol. 11586), Aaron Marcus and Wentao Wang (Eds.).Springer,408–419. https://doi.org/10.1007/978-3-030-23535-2_30 ↩
-
Yang Hu, Connor Imes, Xuanang Zhao, Souvik Kundu, Peter A. Beerel, Stephen P. Crago, and John Paul Walters. 2021. Pipeline Parallelism for Inference on Het- erogeneous Edge Computing. CoRR abs/2110.14895 (2021). arXiv:2110.14895 https://arxiv.org/abs/2110.14895 ↩