[TOC]
Transformer in CV
Transformer的优势:
- 并行计算
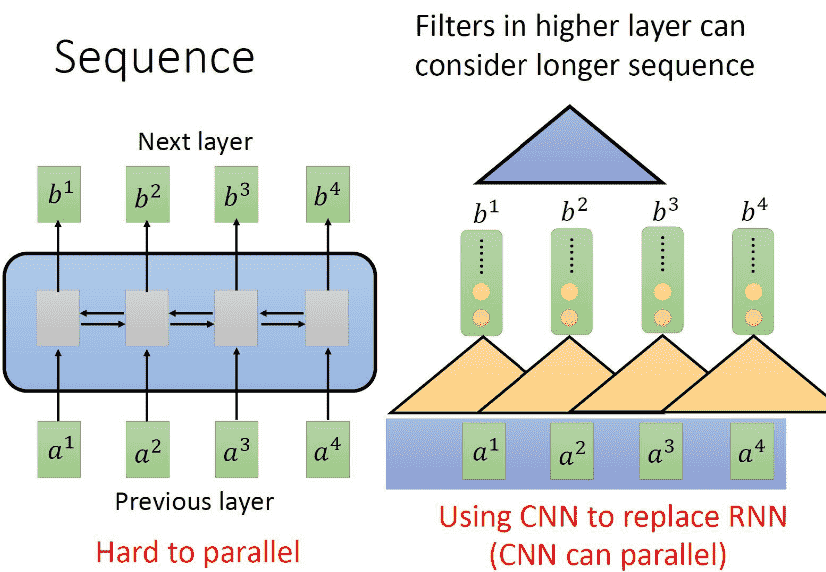
- 全局视野
- 灵活的堆叠
ViT的研究价值
- 展示了在计算机视觉中使用纯Transformer结构的可能
图片—〉transformer—〉 结果
图片—〉backbone(CNN) —〉transformer—〉 结果
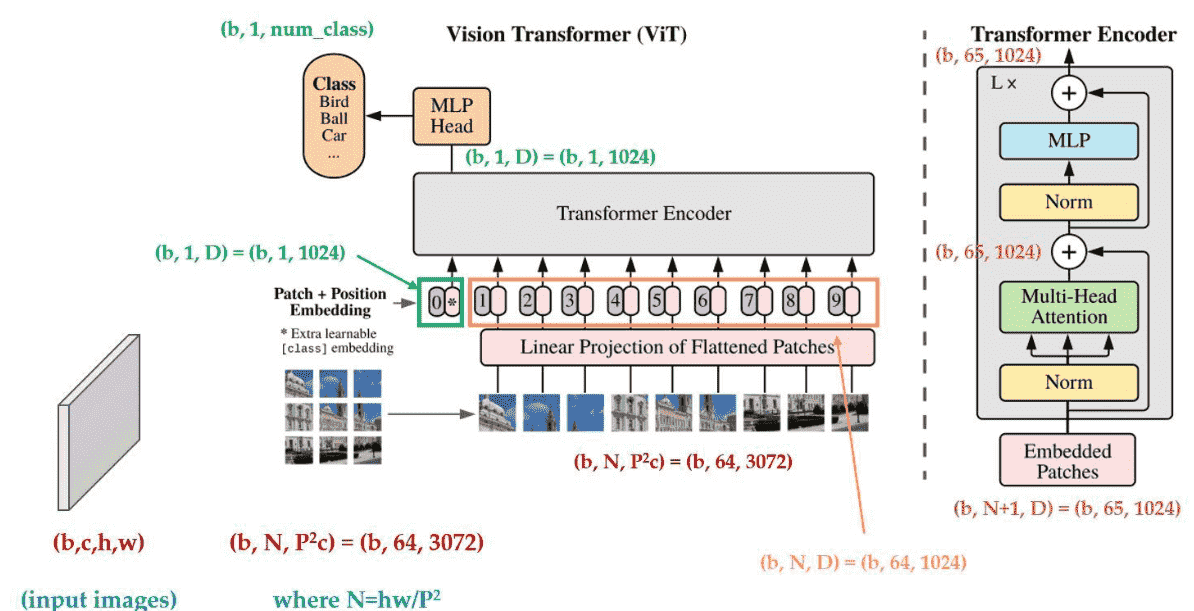
ViT Network Dataflow
Dataflow
Self-Attention
本质上是一种自相似性的计算
早期的 Attention mechanism:
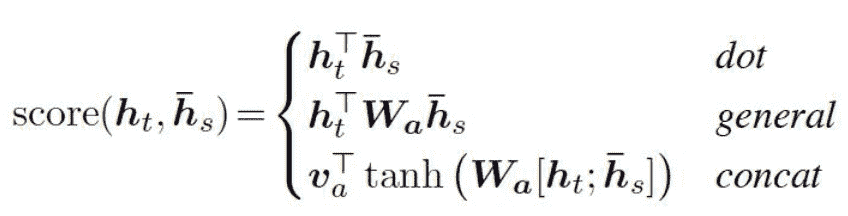
Transformer中的Self Attention这样计算:
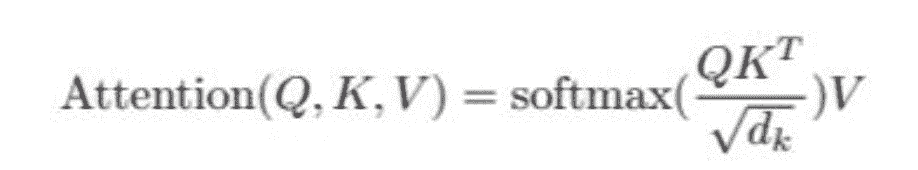
Q、K、V 是从输入向量(矩阵)线性变换得到的三个向量(矩阵);在代码层面,我们可能只是使用一次矩阵乘,然后切分成三个矩阵:
Query: 查询, 询问;相当于你在淘宝搜索 “游戏机”
Key: 键值,关键词 ;相当于在后端数据库中“游戏机”
Value: 价值,数值;相当于商品页面的“选项”
所以Q(K^T)相当于计算搜索词与数据库的匹配度,Q(K^T)V相当于输出搜索结果
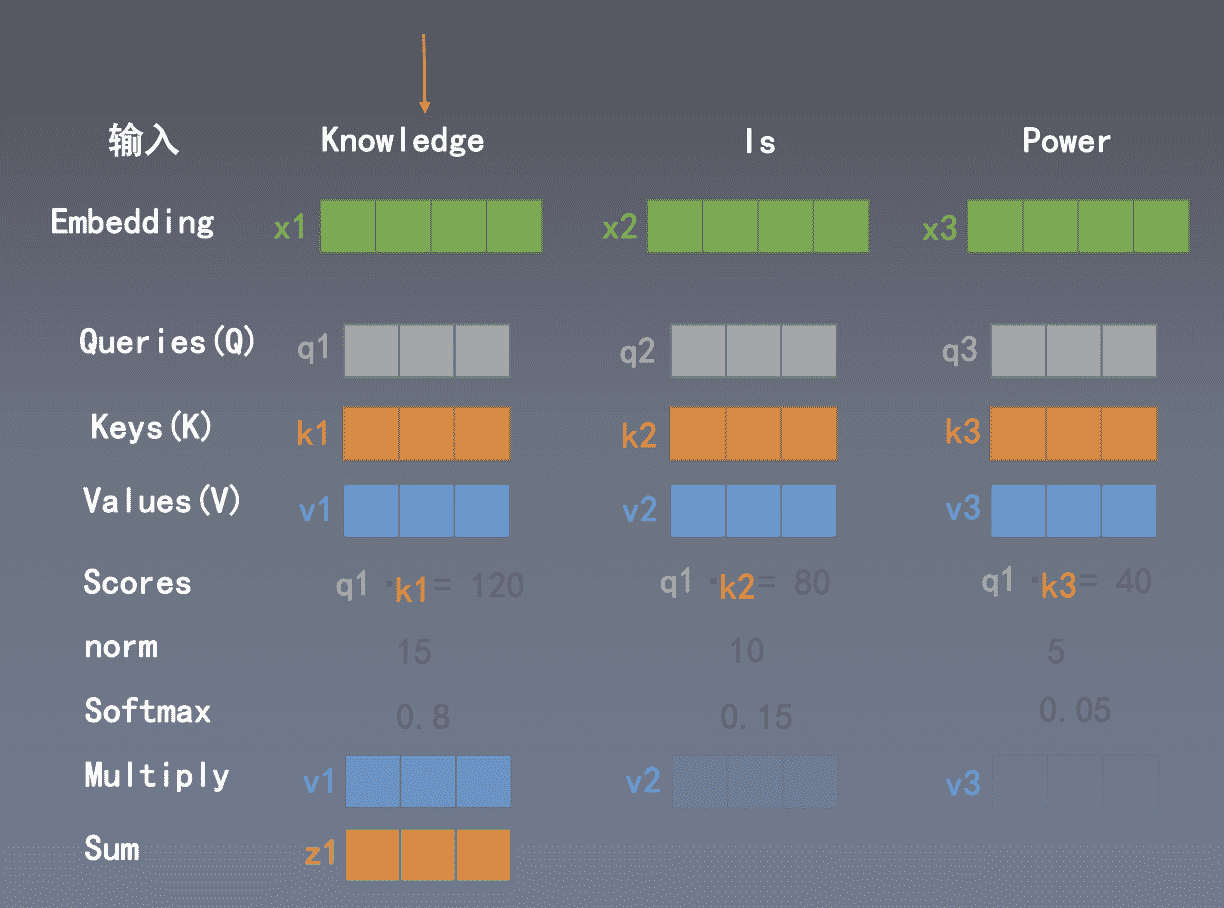
这里的 Z1=V1+V2+V3 结果就是词语在句子背景下的词义
- 这里的向量乘可以通过矩阵乘法并行
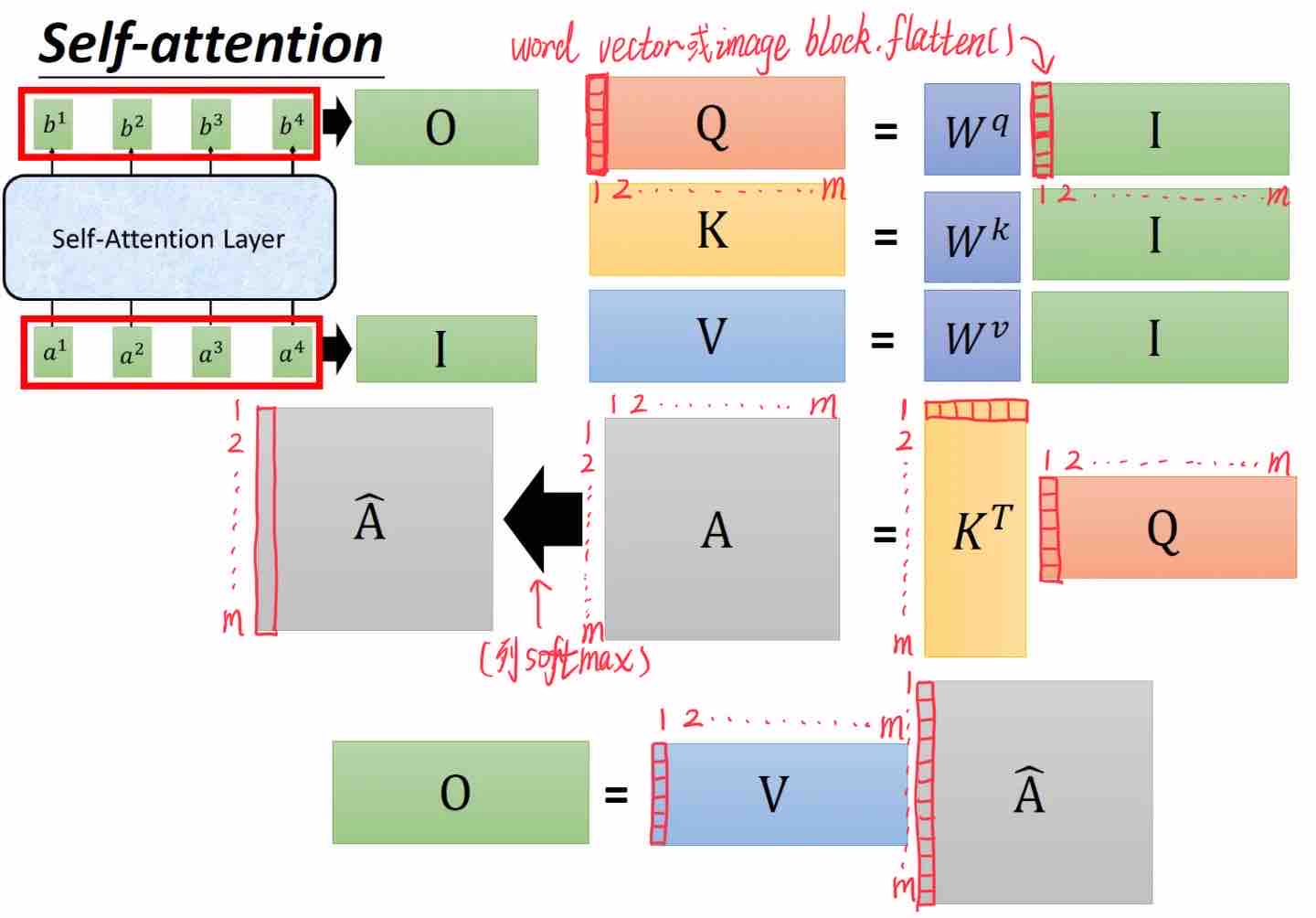
这个图里的乘法转置过
Multi-Head
本质上就是有多个Wq,Wk,Wv, 上述操作重复多次,结果concat一起,再过一次linear使得结果与输入维度一致。
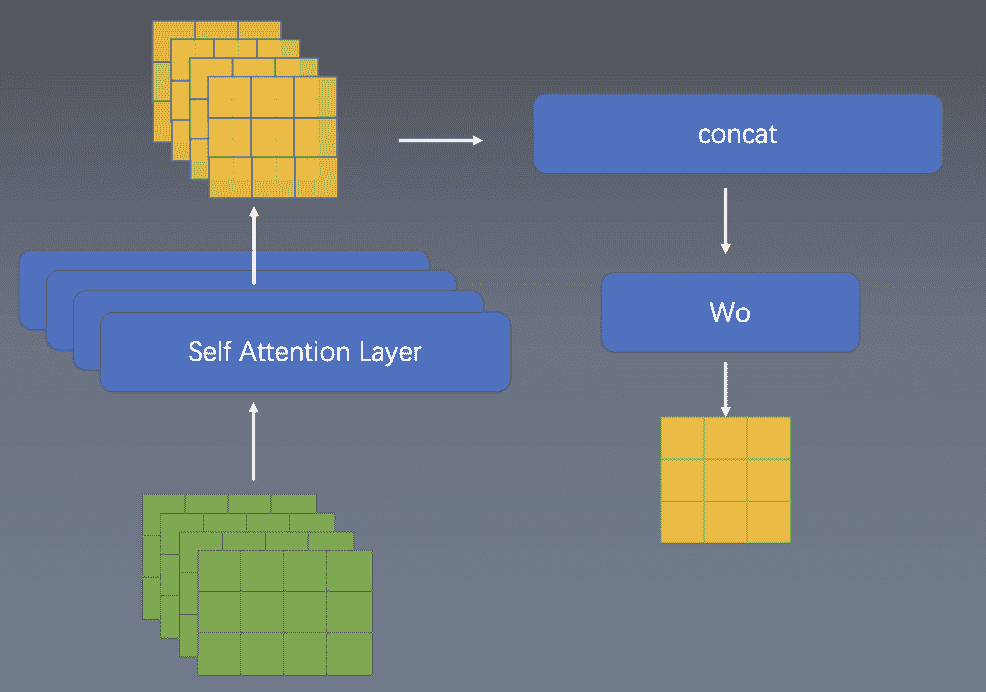
Multi-Head使得模型可以使用多种注意力:短注意力、长注意力等
Details
为什么会有 Patch 0?
从NLP角度看,Patch 0 是一个句子的起始符,NLP认为 输出的 Cls Token 可以用在句子级语义判断上(比如句子分类问题);
从CV角度上看,ViT 需要一个整合信息的向量,如果只有原始输出的9个向量,用哪个向量来分类都不好,全用计算量又很大(也可以,就是求均值),所以加一个可学习的 vector 也就是patch 0来整合信息。
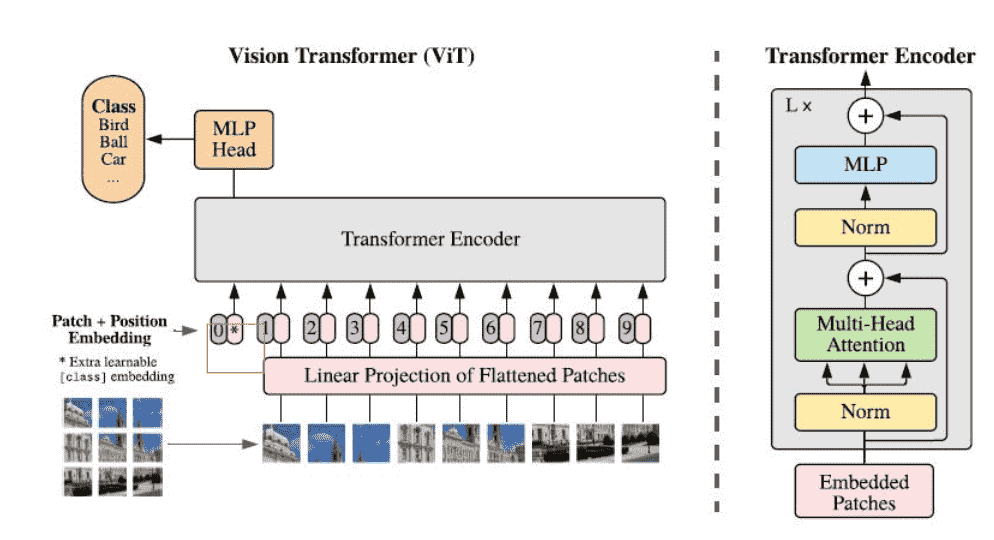
Positional encoding
Motivation:图像切分重排后失去了位置信息,并且Transformer的内部运算是空间信息无关的,所以需要把位置信息编码重新传进网络
Solution:ViT使用了一个可学习的vector来编码,编码vector和patch vector直接相加组成输入
- 相加是一种特殊的 concat:
$W(I+P)=WI+W P$
$[W_1, W_2][I, P]=W_1 I+W_2 P$
$\mathrm{W} 1=\mathrm{W} 2$ 时,两式一致; 其实也有为了简化计算的原因
为什么scale取sqrt(d_k)?
https://github.com/BAI-Yeqi/Statistical-Properties-of-Dot-Product/blob/master/proof.pdf