[TOC]
Backgroud
ViT drawbacks
-
显存占用
= 模型参数+FeatureMap参数 $\times$ 系数 (3, 因为FM是BP参数和优化器参数的上界)
-
模型中的参数 (卷积层, $\mathrm{fc}$ 层等)
-
模型每一层的输出 (Feature Map)
-
BP时的参数
-
优化器中的一些参数
-
-
表示方法
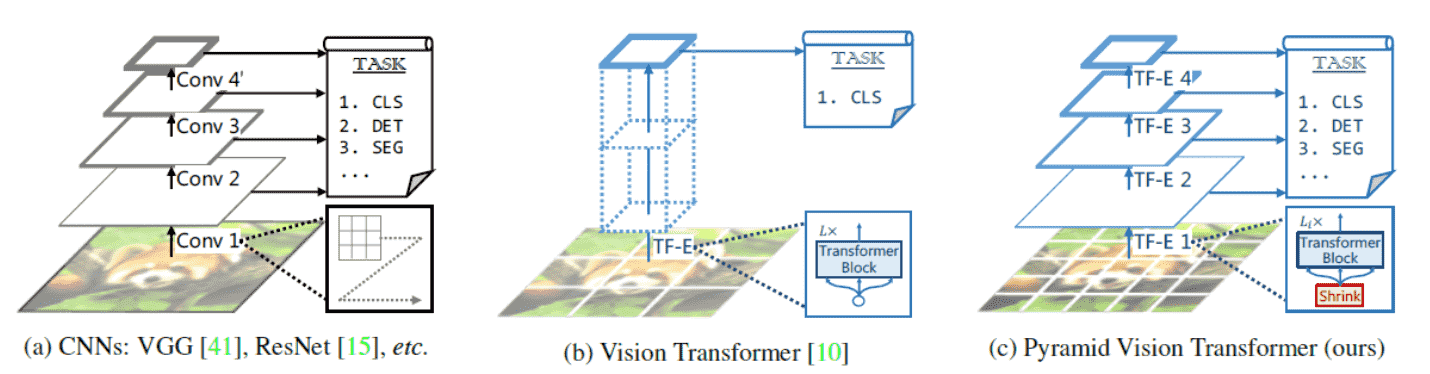
直筒型表示的缺点:
1)ViT中feature map的分辨率和patch size有关,最佳patch size和图片本身有关
2)在大多数下游任务中,高分辨 feature map(pixel level)是必备的
-
难以在下游任务应用(ViT FRCNN)
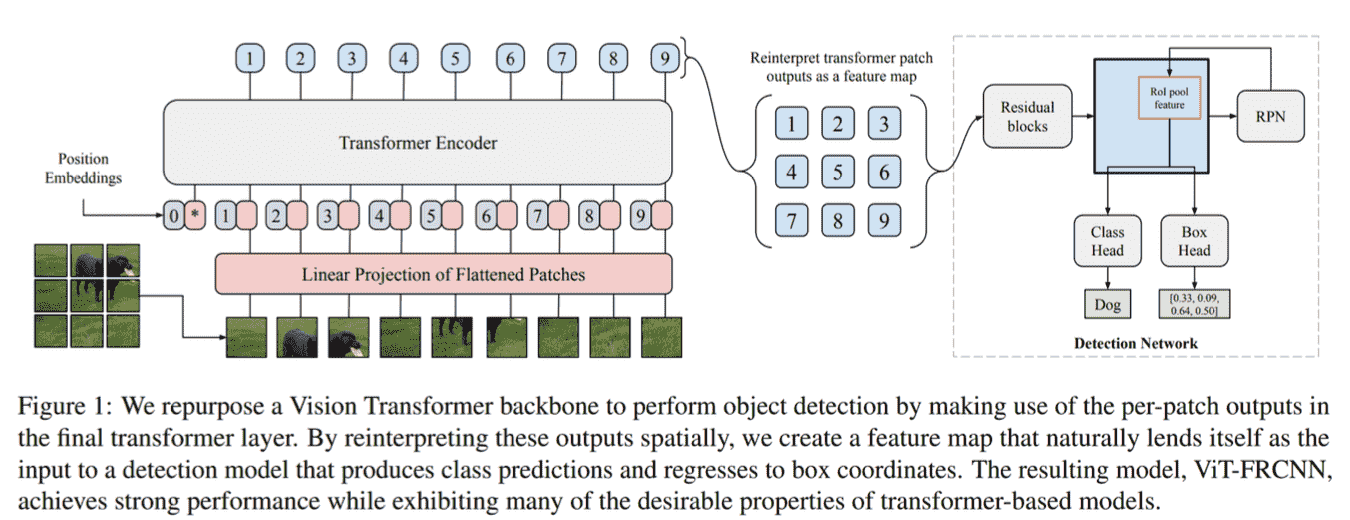
- 名词解释: https://zhuanlan.zhihu.com/p/348800083
- 预训练解释 : https://zhuanlan.zhihu.com/p/49271699
Pyramid
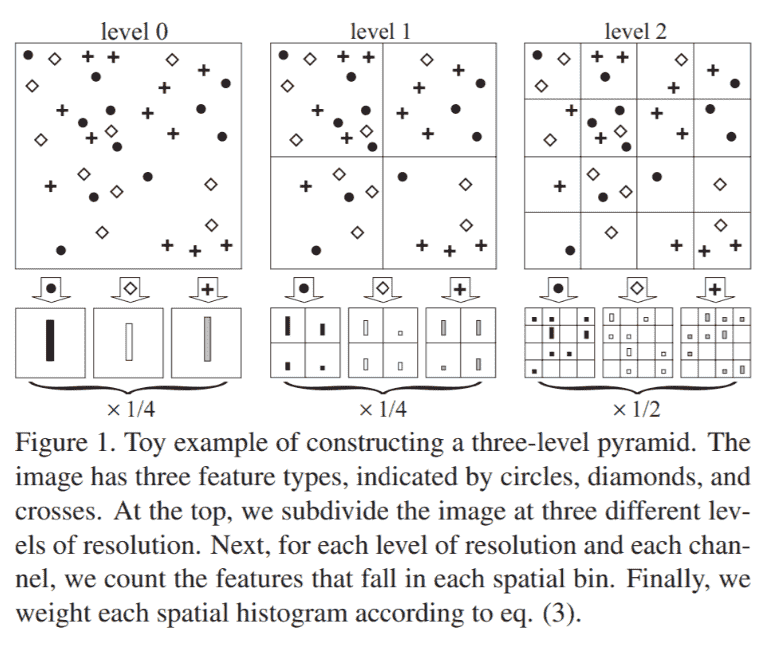
Spatial Pyramid Matching
-
简单的把图片分成大小不同的块
-
然后统计每个块中feature出现的次数
-
拼起来就是图像的表示
Spatial Pyramid Pooling

- 把Feature Map分成大小不同的块
- 然后对每个块内执行Max Pooling
- 拼起来就是图像的表示
Feature Pyramid Network (FPN)
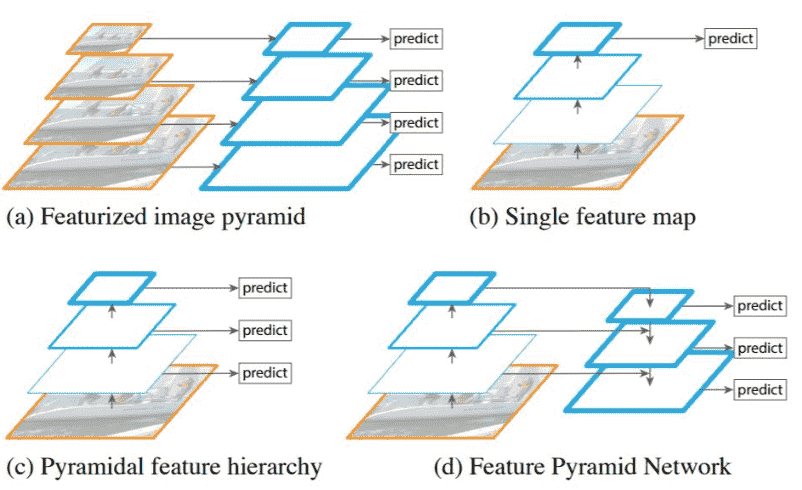
- (a) 输入大小不同的image获取金字塔
- (b) CNN最普遍的用法
- (c) 直接把中间输出拿出构建金字塔
- (d) FPN 先下采样再上采样
FPN是下游任务中的标准neck
ViT 使用 FPN 的 dilemma
- q、k数量和patch的大小相关
- Patch越多,q、k越多,Multi-head attention 计算越慢,显存占用越高
- Patch越大,feature map分辨率越低,下游任务效果变差
分析:
-
计算开销:需要进行 pair $(q, k)$ 的相似度计算 所以时间复杂度是 $O\left(n^{\wedge} 2\right)$
-
显存开销:
- $\mathrm{Q}, \mathrm{K}, \mathrm{V}$ 的生成 $O(n)$
- Attention Map的维护 $O\left(n^{\wedge} 2\right)$
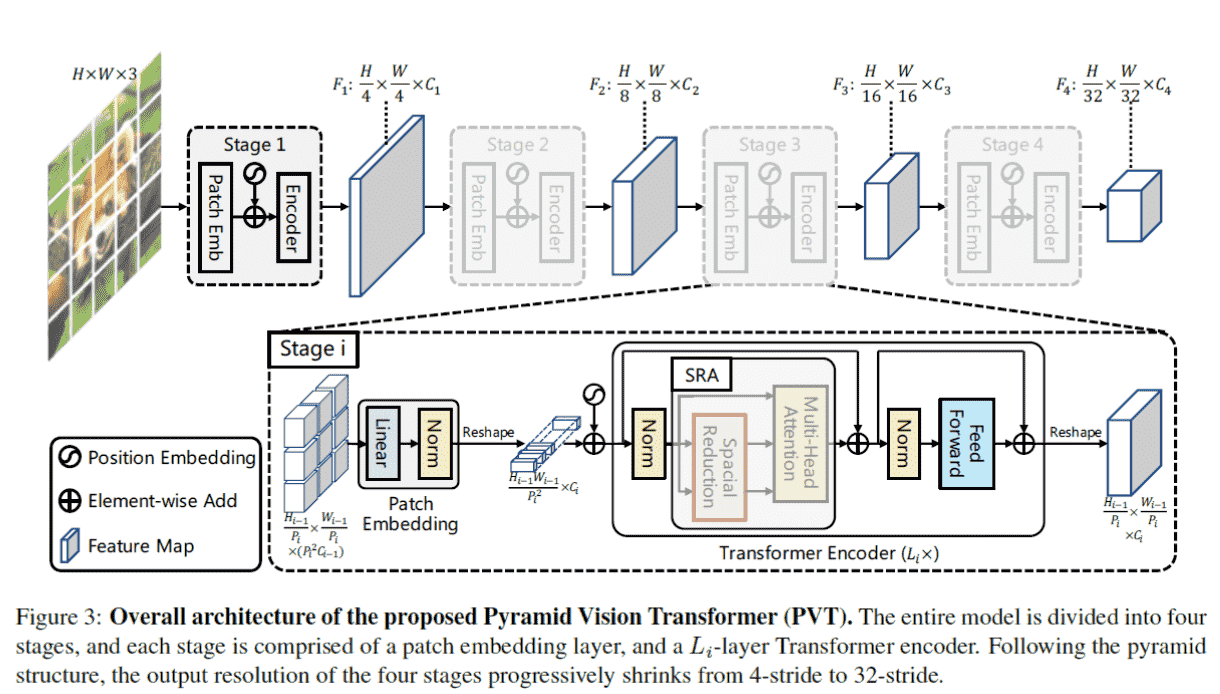
PVT
Structure
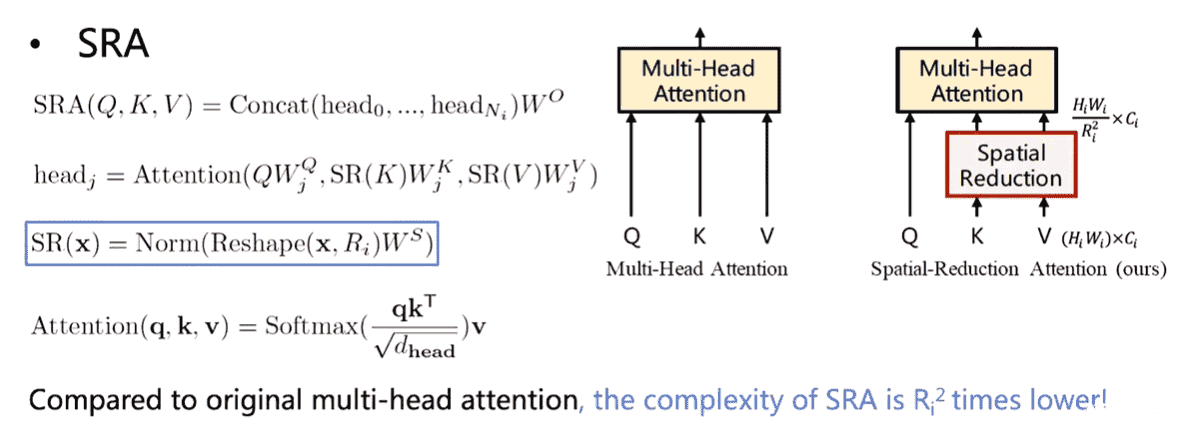
Spatial Reduction Attention(SRA)
目标:减少K,V的维度以减少计算开销
实际操作中就是用了一个卷积降了一下k,v 的size。可以理解为将R个点聚合成一个,然后attention的时候Q和聚合成的点的K和V算。
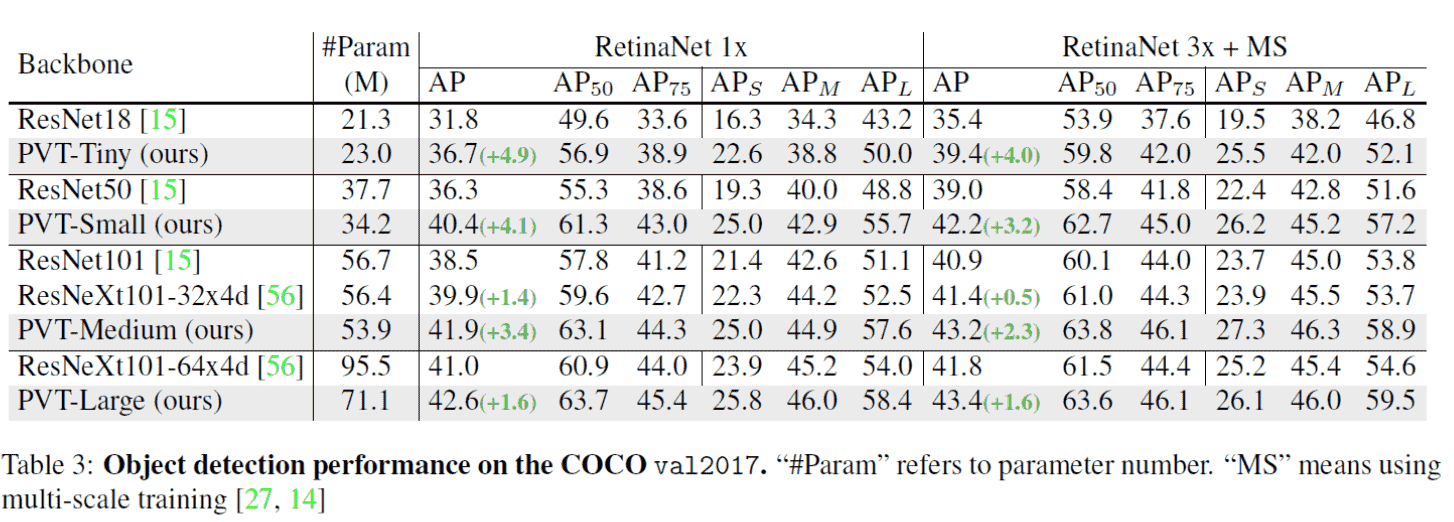
Experiments
在原文中对 Image Classification、Object Detection、Semantic Segmentation中进行了测试,这是OD的结果:
Ablation Studies
- Network 是 Deeper 好还是 Wider 好? Deeper
- PVT 的 latency 比传统 R50+ Retina net 高
在PVT上的的工作
-
PVT v2
-
SegFormer