[TOC]
Backgroud
论文梳理
- O(Objective):
- Token应该多大?
- Token太多怎么办?
- K(Key Method):
- 金字塔结构(解决 “ Token应该多大?”)
- Local attention(解决 “Token太多怎么办?”)
- W-MSA
- SW-MSA
- R(Result):
- Shifted window
- Relative position bias
SRA 的问题
- 复杂度仍然是 O(n^2),只是限制了常数项
- Q与K的感受野不一致
CV和NLP的本质区别
ViT出现后,出现了很多Transformer运用到CV各个任务上的Paper 但作为这两个任务有一些根本上的不同,导致一些任务中Transformer不那么好用。
SwinTrans 原文给出了两点不同,一个是Token的大小,一个是Token的数量,这两点分别对应表示方法和显存占用两个问题。
- 表示方法
- Token为最小的处理单元
- 在NLP中有很多符合直觉的Token定义,比如说单词,或者说中文中几个字组成的词。
- 但在CV中,Token应该多大呢? 这依赖于目标物体的复杂程度(不同类别)和图像视角(同一类别)。而且有些类别不规则,难以切分为patch。
- 显存占用
- Token指的是模型运行中最小的处理单元。
- NLP中的Token一般指的是一个单词,Token的数量就是一段文字中单词的数量,一般不会特别多。
- 比如微博内容,140字;比如高考作文,一般不会超过1200。
- CV中的Token指的是一个Patch,Token的数量就是Patch的数量,下游任务中一般会很多。比如224输入,4倍下采样的情况下,Token数量为56x56, 3000多个。
-
CV中使用MHA的dilemma
-
Patch小 -> Token数量多 -> MHA复杂度高 -> 资源不足
- Patch大 -> Token数量少 -> 分辨率低 -> 下游任务性能差
- 性能 or 速度,this is a question
-
研究意义
这是第一篇被大家广泛接受的在下游任务中使用纯Transformer结构的方式
后续有非常多的工作都在Swin Transformer的基础上做的
Swin Transformer
Abstract
- 本文提出一种可以适用于多种任务的 backbone->swin transformer
- Transformer迁移到CV中有两点挑战->物体尺度不一,图像分辨率大。
- 为了解决尺度不一的问题,Swin Transformer使用了分层的结构 (Pyramid)
- 为了能够在高分辨率上运行,Swin Transformer限制了attention的计算范围。
- Swin Transformer在多种任务上取得了非常好的性能。
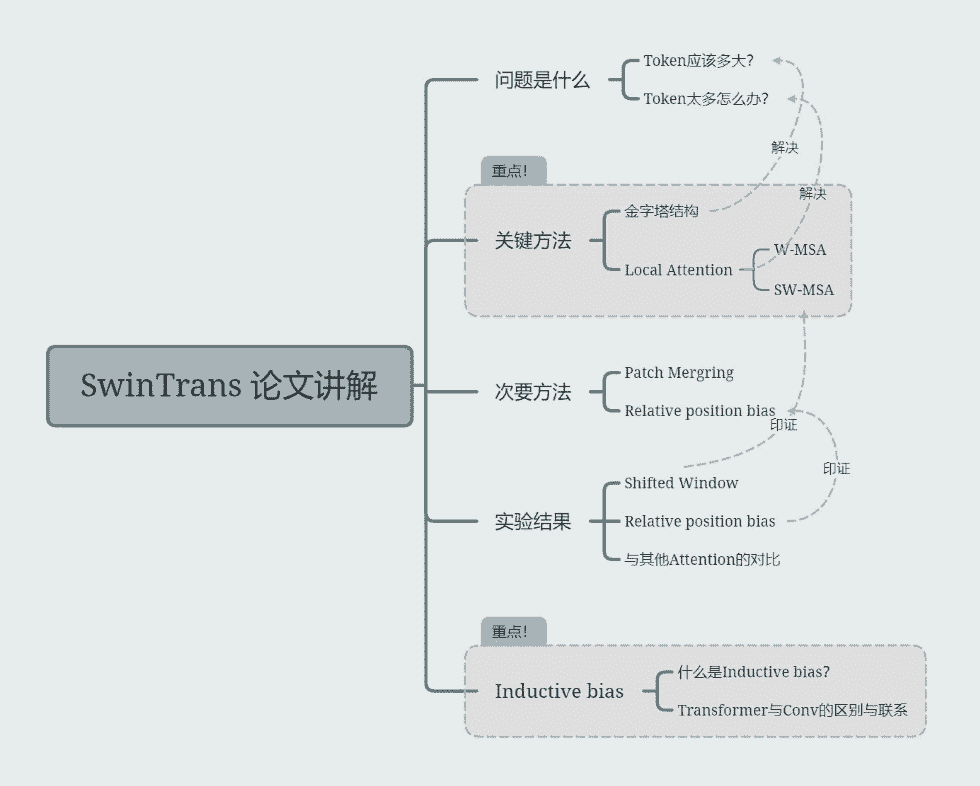
Structure
- Patch Partition
把每 4x4 个 pixel 在channel方向重排
- Patch Merging
把每 2x2 个 pixel 在channel方向重排后过一个linear使得channel变化服从 C -> 4C -> 2C

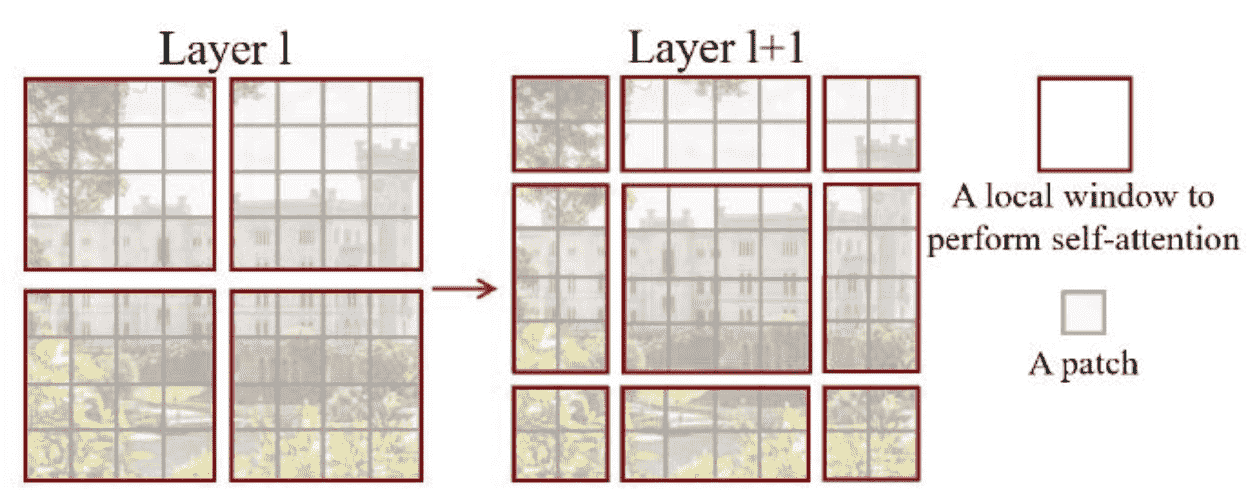
W-MSA(Window-Multiscale Self Attention)
-
降低复杂度?方式就是Q只与固定数量的K做计算
-
哪些K?空间位置上接近的那些K,所以就使用window

https://arxiv.org/pdf/2106.04554.pdf
SW-MSA(Shifted Window-Multiscale Self Attention)
motivation: W-MSA 硬性的限制会丢失全局信息,限制模型能力,因此需要一个跨 Window的操作,增强window间的交互。

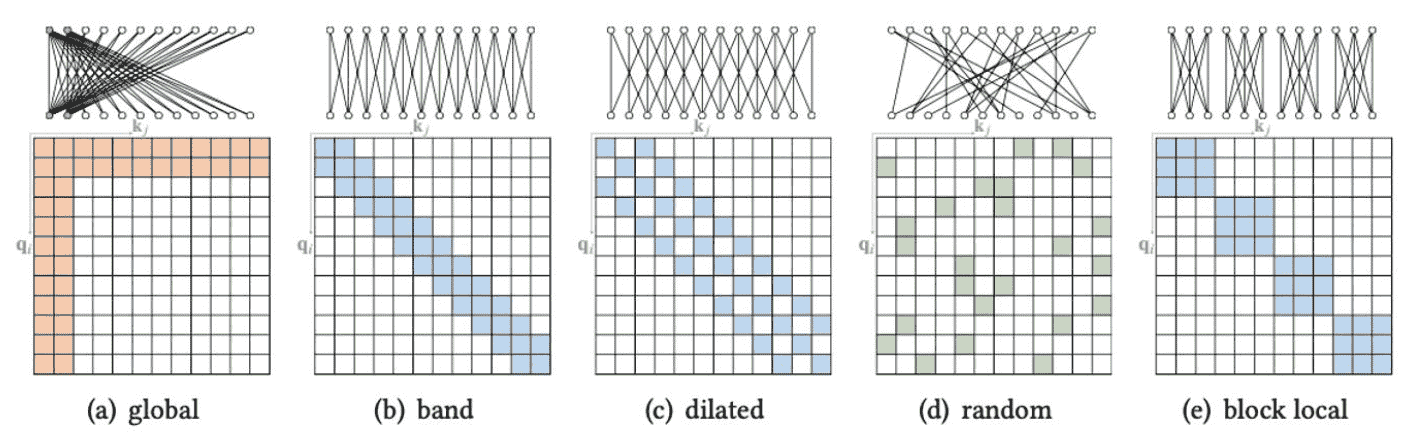
SW-MSA 加速
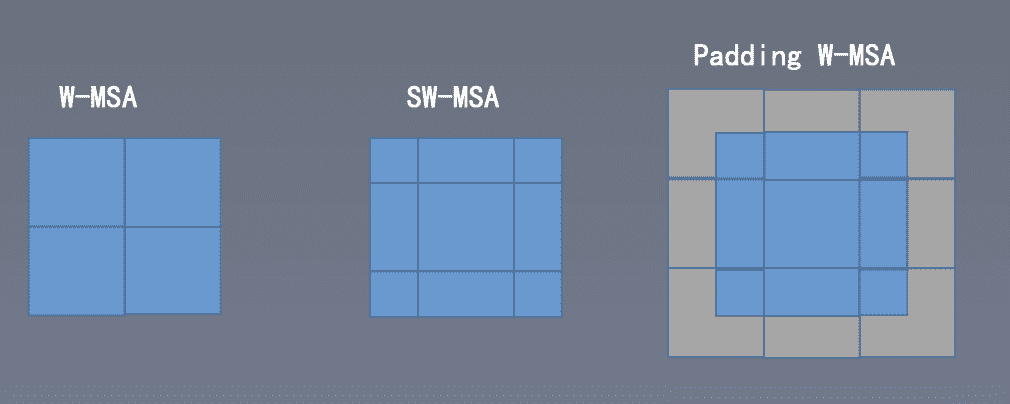
naive
可以通过padding的方式将window的尺寸变一样,在mask掉其他值, 可以直接调用W-MSA,但是计算量增长
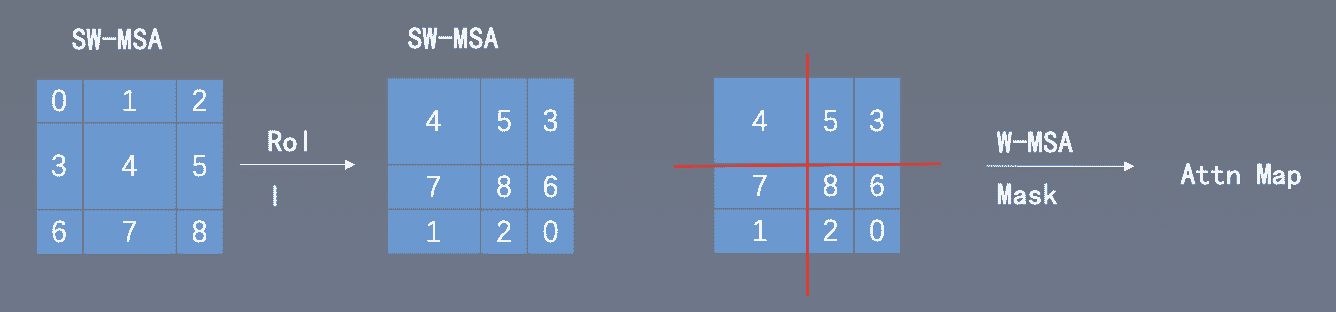
cyclic-shift
可以通过roll的方式将切碎的小window从左上角挪动到右下角,拼一起, 计算时候把不同window间的值mask掉,计算完成后再roll回来。

相对位置编码
相对与绝对
- 绝对:对于每个位置生成一个固定的位置编码
- 相对:以不同位置为原点,其他位置的编码是不一样的
实现:维护一个Tabel,根据相对位置的偏移量,从Tabel中取编码值。
注意:相对和绝对位置编码对不同任务适应性不同,需要去尝试
CNN vs Trans
尽管 CNN 和 Trans 看起来很像:
- 操作都在window内
- 都是金字塔结构
- 都是Pretrain-Fine Turn的Pipeline
- 甚至可以用Conv2d写一个Trans出来
但他们在处理图像时候的逻辑是完全不一样的, CNN有很强的Inductive Bias,Trans没有
Inductive Bias
-
直译为归纳偏置
-
归纳->总结,也就是从现存的例子中找到一些比较通用的规则
-
偏置->选择偏好。
-
整理在一起可以理解为:在面对一些特定问题的时候,我们认为模型应该会有哪些特点会比较容
易work,因此而做出的一系列对模型的人为限制。
-
比如图像处理中,每个位置的信息与周围的信息相关,因此设计出conv。
-
比如NLP中,认为输出的结果与单词的先后顺序相关,因此设计出RNN。
-
Inductive Bias (归纳偏置) 是导致 trans 训练慢点根本原因。在密集预测任务中,鼓励Inductive Bias是十分重要的。
CNNs的假设及性质
- Pixel只与周围Pixel相关->局部连接->Conv固定大小
- 空间平移不变性 -> 权重共享
就可以解释:
-
为什么常见的conv都是奇数大小的?
- 为什么深层的Feature Map难以理解?
- 为什么从ImageNet迁移到肿瘤分类仍然有不错的性能?
CNN中的kernel
在图像处理fitter中,利用边缘滤波器可以提取边缘特征;
而CNN中自动学习的kernel就能提取图片的某些特定特征;越深层的feature越抽象,越全局;

空间平移不变性
对于不同位置的kernel应该一致,因为物体的平移不影响识别

ViT的假设及性质
-
Patch内信息建模->MLP
-
Patch间信息建模->MHA
这之中的限定相对Conv就要小 Inductive bias 就小

ViT的feature map即使是在深层也可以看出全局信息(是什么物体)
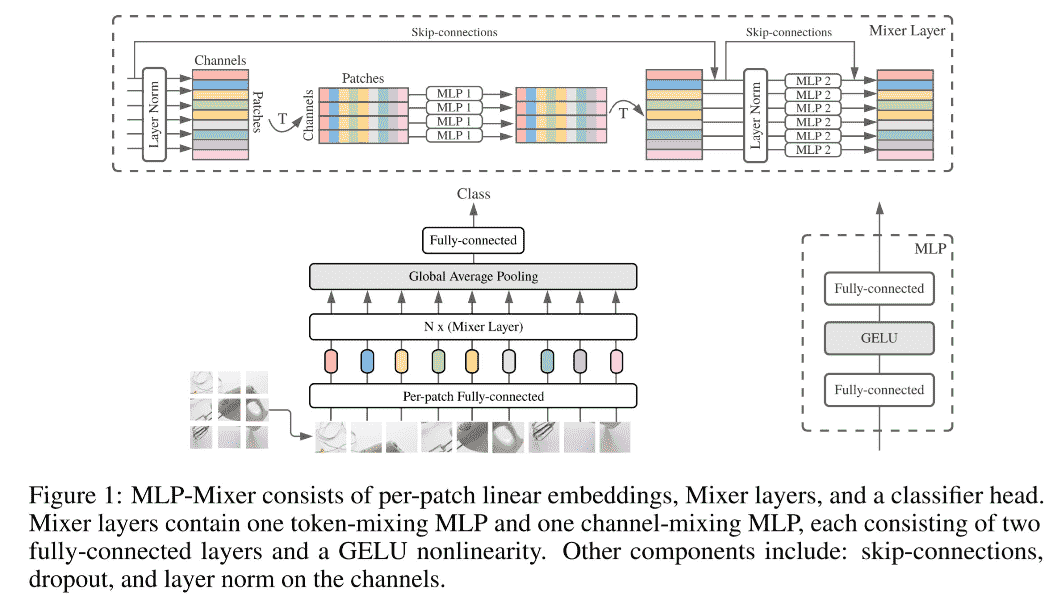
MLP mixer
- Patch内信息建模->MLP
- Patch间信息建模->MLP
Experiments
Image Classification: 设置上follow DeiT
- Inputsize:224x224
-
Batch size : 128
- Learning Rate : 0.001
- Total Epoch : 300
- LR Schedule : cosine
- Resource : 8 V100 GPUs
Ablation Studies
Shifted Window
- 带shifted window会有更好的效果,尤其是在复杂下游任务中
相对位置编码:
- no pos. 无位置编码
- abs. pos. ViT的位置编码
- abs + rel. pos. 两种编码相加
- app. 不除根号dk
但是相对位置编码效果最好
不同的self attention方法
- 使用了performer