[TOC]
如何在下游任务中使用 Trans ?
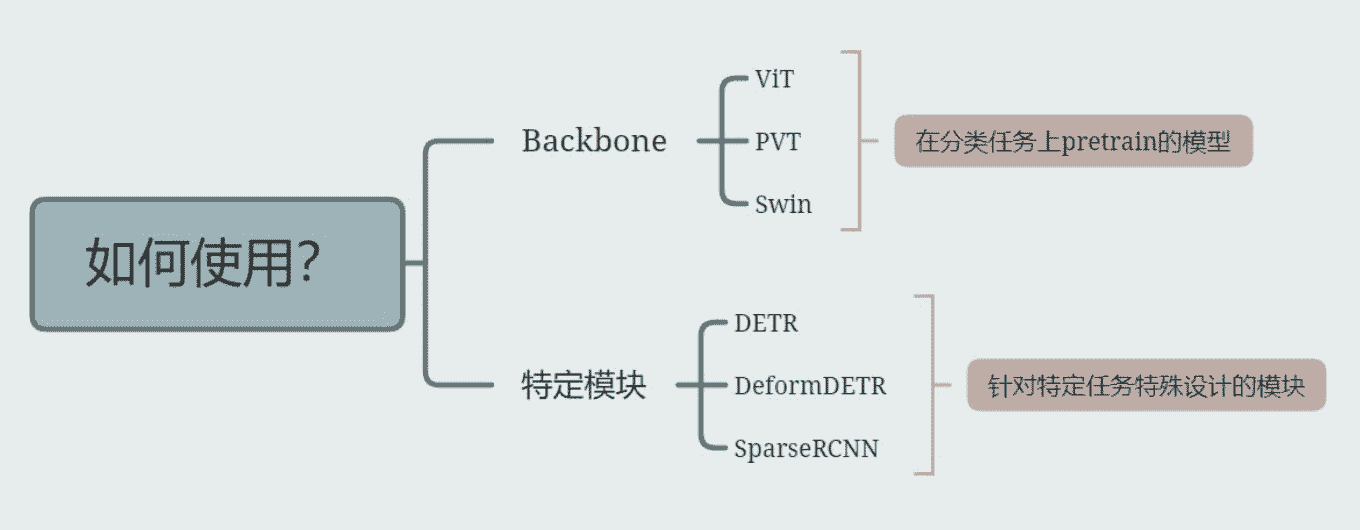
- 在代码中用swin 替换原本的r50
- 下载训练好的权重
- load权重开始训练
Backgroud
- ViT效果很好,但是特别吃数据
- 为什么这么吃数据? -> 根本原因Inductive bias
- RNN假设数据有前后关系,因此做出了时序依赖的设计
- CNN假设数据有空间上的上下左右关系,因此做出了conv kernel这种设计
- 但Transformer没有对数据做出任何假设,所以需要更多的数据来归纳出这些依赖关系
- 解决办法 ?
- 加数据,如果不能加更多的数据集,那么就加更多的数据增强
- 蒸馏,学一下convnet的结果
- 为什么这么吃数据? -> 根本原因Inductive bias
研究意义
- 给出了一套标准的VIT训练流程,不依赖JFT,也不会要太长的训练时间
- 这种特性让他成为了很多后续任务的baseline model
DeiT
方法
- 加数据
- 如果不能加更多的数据集,那么就加更多的数据增强
- 数据增强增加后,超参要进行相应的调节
- 知识蒸馏
Data-Augmentation
直接抄表
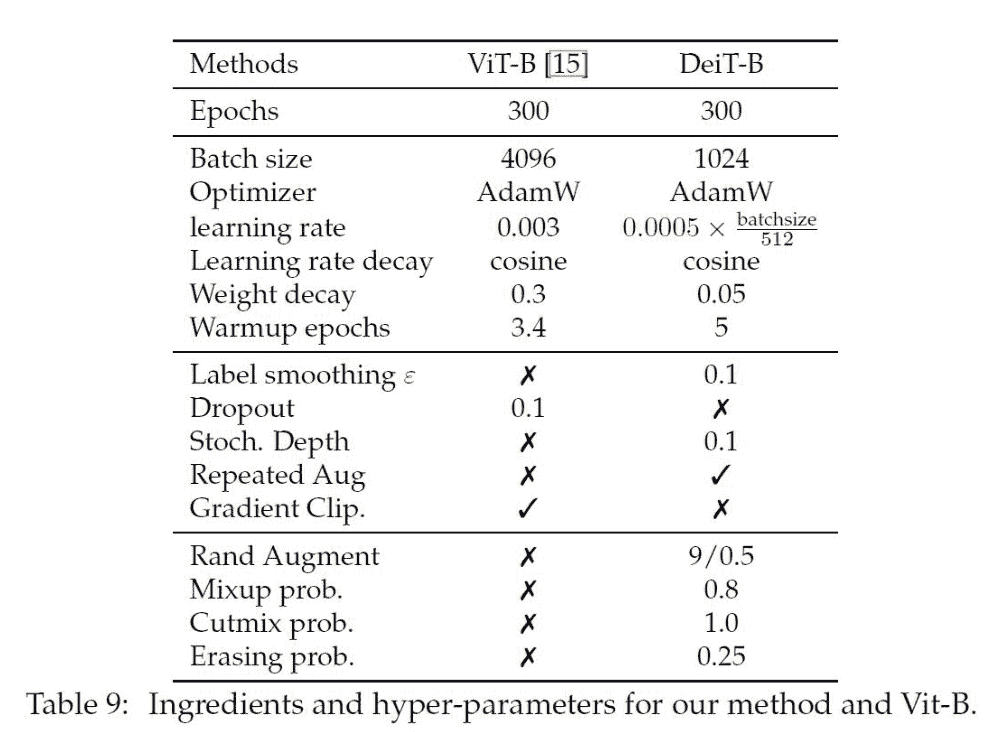
- Rand Augment:搜索一种增广方式。对于输入图像,Rand Augment首先随机选择一个强度值,该值表示在一次数据增强中应该应用的增强操作数量。然后,从预定义的一组数据增强操作中,随机选择强度值次数的增强操作,并按照随机顺序将这些操作应用于输入图像。常用的数据增强操作包括旋转、裁剪、缩放、颜色抖动等。
- Mixup Prob:Mixup是一种数据增强方法,其基本思想是将两张不同的图像混合在一起,生成一张新的图像作为训练样本。具体地,对于输入图像x和对应的标签y,从训练集中随机选择另一张图像x’和对应的标签y’,然后按照一定的比例将x和x’进行线性混合,生成新的输入图像x_mixup,同时将y和y’按照相同的比例混合,生成新的标签y_mixup。Mixup Prob指的是Mixup方法中x’被选中作为混合图像的概率。
- Cutmix Prob:与Mixup类似,Cutmix也是一种数据增强方法。与Mixup不同的是,Cutmix是将一个矩形区域从一张图像中剪切下来,然后将其贴到另一张图像中,生成一张新的图像作为训练样本。具体地,对于输入图像x和对应的标签y,从训练集中随机选择另一张图像x’和对应的标签y’,然后在x和x’中随机选取一个矩形区域,并将该区域从x中剪切下来,贴到x’的对应位置上,生成新的输入图像x_cutmix,同时将y和y’按照相应的比例混合,生成新的标签y_cutmix。Cutmix Prob指的是Cutmix方法中选取剪切区域的概率。
- Erasing Prob:Erasing是一种简单有效的数据增强方法,其基本思想是在输入图像中随机选取一个矩形区域,并将该区域的像素值设置为0,相当于将该区域擦除掉。具体地,对于输入图像x和对应的标签y,从x中随机选取一个矩形区域,并将该区域的像素值设置为0,生成新的输入图像x_erasing。Erasing Prob指的是Erasing方法中选取擦除区域的概率。
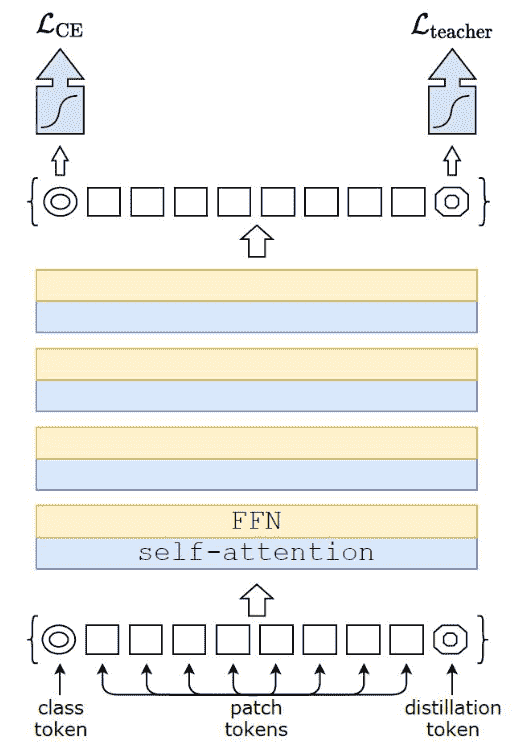
Distillation
idea:想从Conv里面学inductive bias
- 本质是额外增加了一个Label
- 除了图像原本的Label还有一个Teacher模型的Label
- Soft distillation指的是用这个loss:
- Hard distillation用的是这个loss:
为什么 pretain 要用分类
-
Backbone部分越强,那么下游任务也会越强
-
模型在分类任务上表现越好,我们就认为,他做Backbone越好
-
图像分类的问题包含以下两个问题:
- 如何把同一类别的物体映射到同一个簇中 (Backbone)
- 如何画线去分开这些类别(MLP Head)
其中问题1,特别重要,这部分也叫特征提取;下游任务用的时候也只会load这部分参数。
- 但是backbone用分类也有一定问题:
因为把分类是在找一个类别的共性 但有些任务需要一个图片的个性,比如重建等
所以:解决方案是MAE