[TOC]
Background
- Transformer从NLP到CV的迁移过程中,既然模型统一了,那么训练方法是否可以统一?
NLP中的训练方法: 输入一个句子,盖住其中的几个词,然后要模型预测出盖住的词
这样训练与分类任务的区别:
- 这是一个无需Label的任务,意味着不需要标数据
- 这是一个重建任务,意味着需要更多的信息
非常自然的能够想到CV中可以这样训练: 输入一个图像,盖住其中的几个patch,然后要模型预测出盖住的 patch
为什么之前没人这么做? 因为结构不一样,Conv默认图像空间连续,如果mask掉一部分图像会破坏这个假设
- MAE的结果

Masked AutoEncoder
AutoEncoder
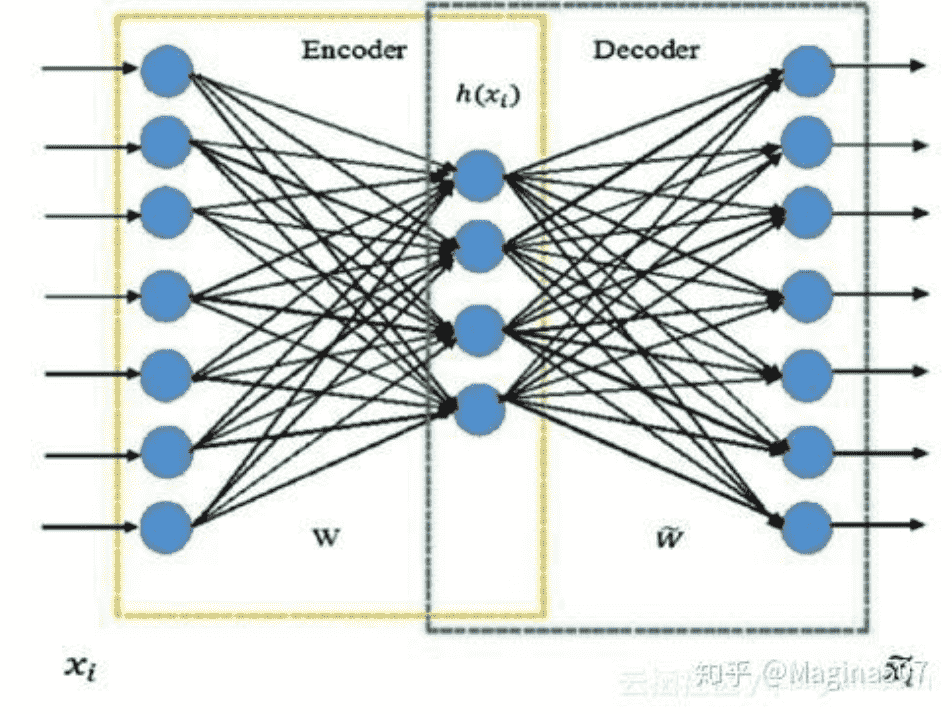
本质是学习一个隐藏层的压缩表示
Architecture of MAE
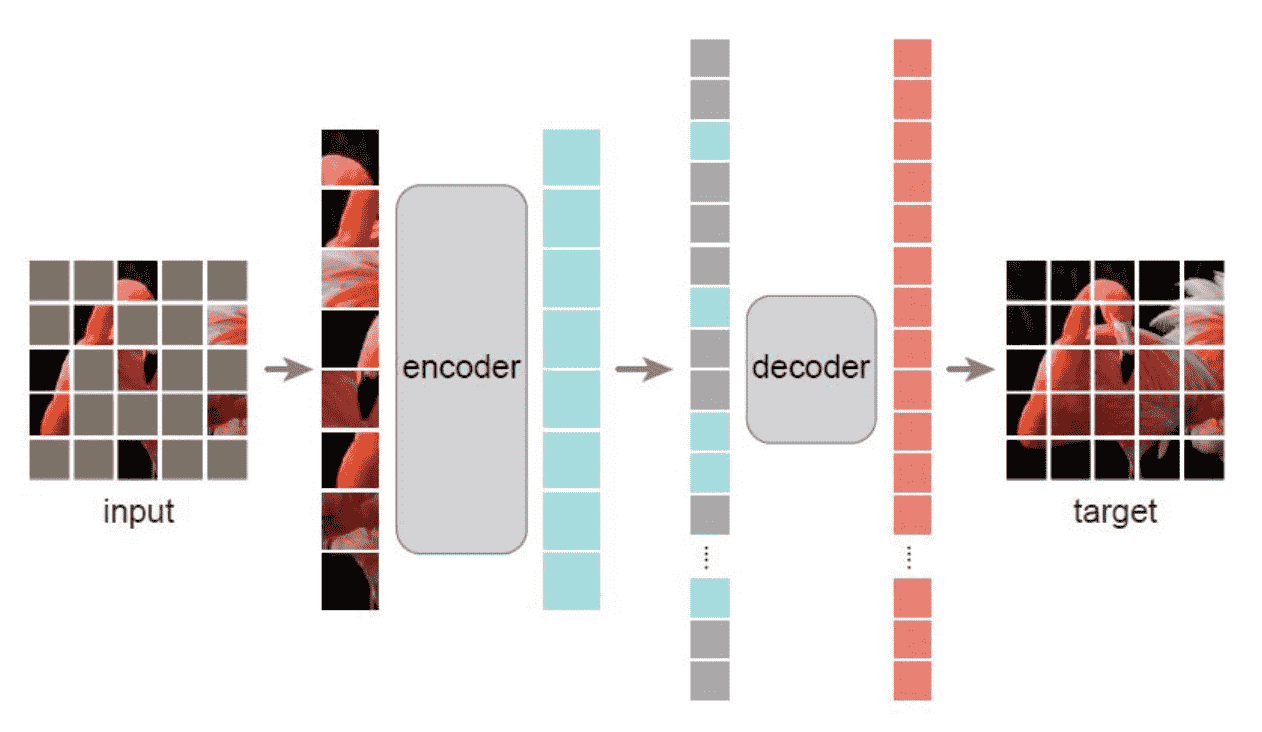
- 目标是获得一个Encoder,加decoder是为了训练能够成立
非对称设计
这里指的是Encoder部分和Decoder部分不对称 其中Encoder可以很大,原因有2
- 两者负责的任务不同,encoder负责特征提取,decoder负责重建。
- 输入不同,只有visible token会进入encoder,计算量小,就可以用大结构
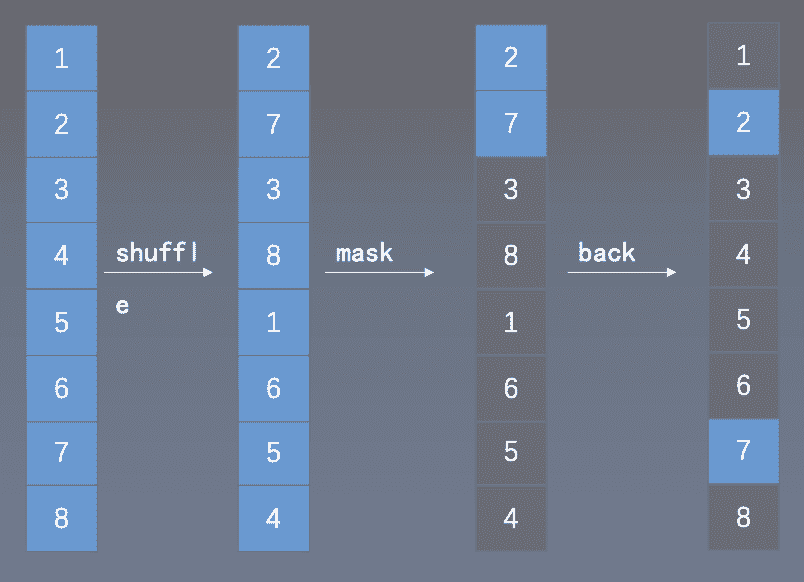
Mask的高效实现
Experiment
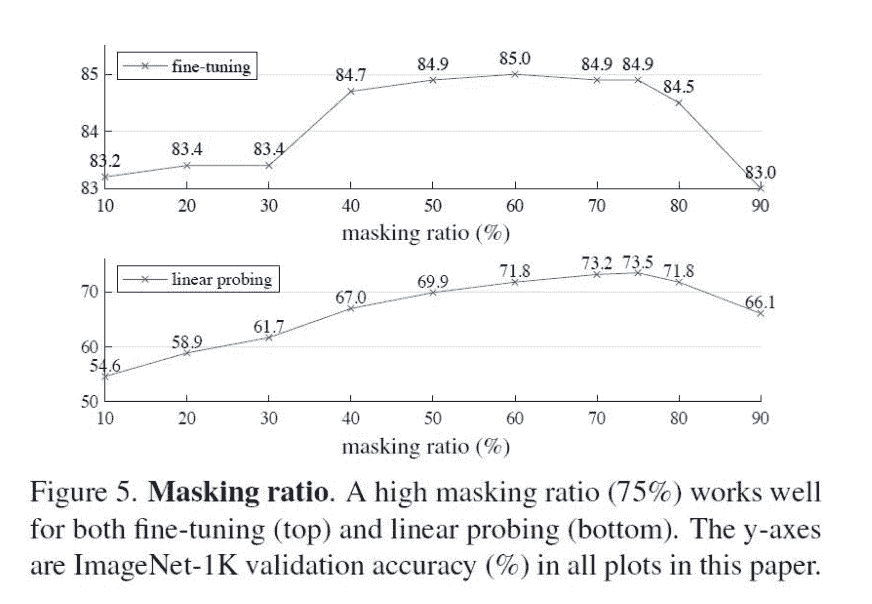
- fine-tuning:整体网络均要训练
- linear probing:接head做分类