[TOC]
Transformer在DET中的应用
transformer 的使用分两类:
-
Backbone
- ViT
- PVT
- Swin
-
Task specific module
发现现存方案的缺点、使用trans解决这些问题
- DETR
- Deformable DETR
- Sparse R-CNN
transformer的训练分两类:
- 分类任务
- ViT
- DeiT
- 重建任务
- MAE
- simMIM
共同目的:获得更好的表征
Background
目前的目标检测方法,无论是单阶段的还是两阶段的,无论是Anchor Based还是Anchor Free的,他们都无一例外的需要使用后处理方法->NMS来过滤掉冗余的预测框
这是因为目前的方法全都基于Dense Prediction,在原理上,这种操作方式不符合人类识别物体的方式。在实践中,这会导致目标检测中会有一系列的手工设计痕迹。
DETR的研究意义
-
深刻的揭露了现存目标检测算法的弊端
-
展示了Transformer在CV领域中的优势
摘要核心
-
本文将目标检测视作一个set prediction问题。
-
我们的方法简化了目标检测pipeline->无需anchor以及NMS这种手工结构。
手工结构:
-
正负样本匹配策略:
结构类似,匹配策略不同
- FCOS
- RetinaNet
- ATSS
-
后处理方案(NMS):
不同的参数会获得不同结果
- NMS方案
- luo阈值
- score阈值
-
-
方法名为DETR,包含一个set based loss和一个Transformer结构。
-
新模型原理上很简洁,而且无需特殊库的支持。
-
DETR的性能不错。
传统目标检测缺点
目标检测 = Localization + Classification
RCNN系列 = 预定位 + Crop + 分类
RCNN 存在的问题是,硬件要支持RoiAlign,否则会很慢
Yolo本质上也是遵从定位+分类的,虽然不是两阶段
FCOS: 一种Anchor Free的方法,但是他更直接,Feature Map上每个点预测结果
Dense prediction
所有的这些方法都可以统称为: Dense Prediction
-
不知道物体在哪里,所以先预定位,然后逐个分类。 只是在两阶段中,是将位置信息显式的标出来,然后逐个proposal分类+微调;而在单阶段中,位置信息是通过Feature Map上的相对位置关系得到,然后逐pixel分类+微调
-
这种思路下的目标检测总是需要后处理(NMS),因为总会有多个proposal对应同一个instance 或者多个pixel对应同一instance,这些多出来的框就需要处理掉。
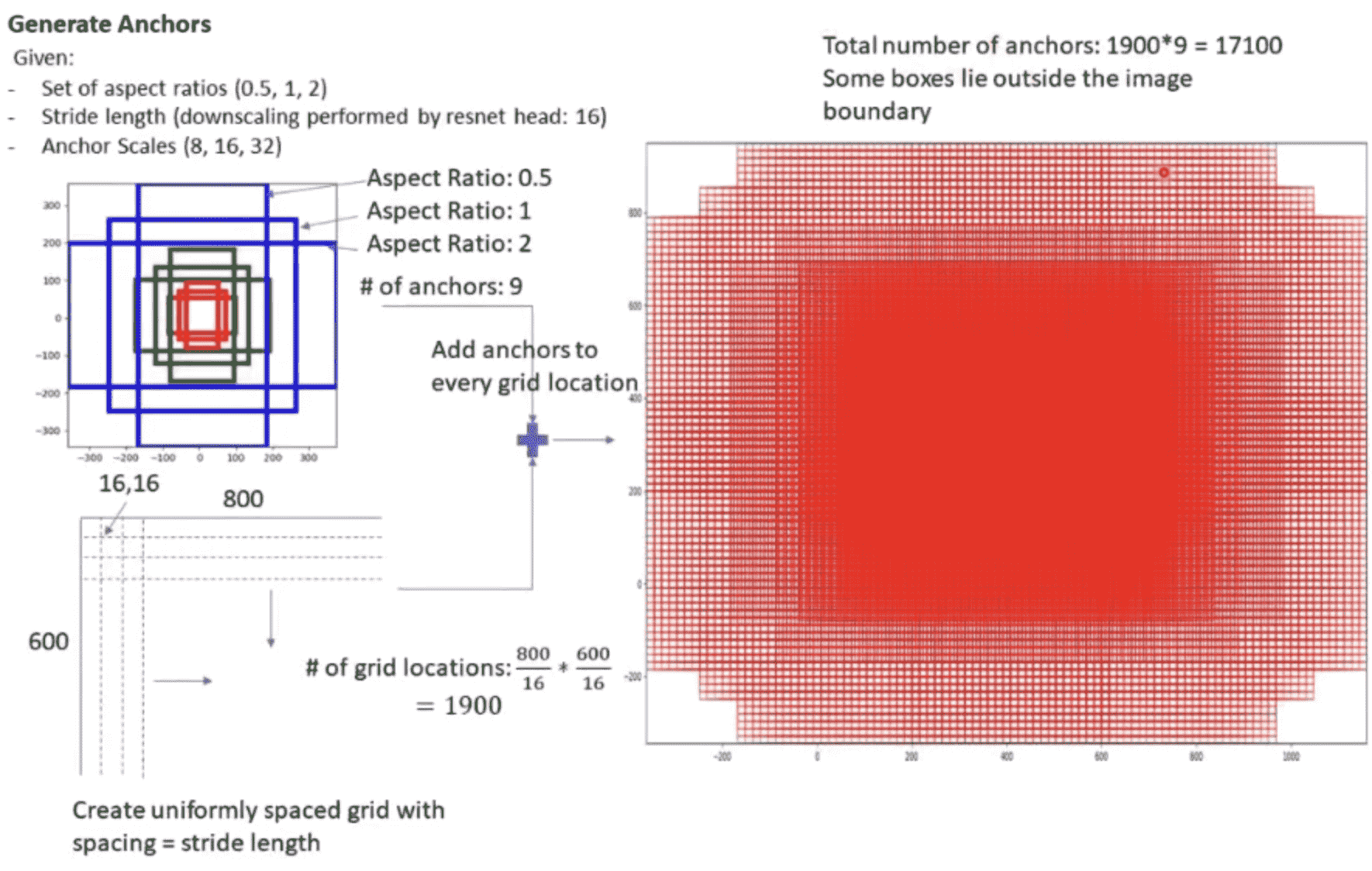
NMS
NMS有以下两个假设:
- 如果两个框离的很近,那么两个框很有可能属于同一instance
- 在属于同一instance的框中,分类得分越高的,定位质量越高(inference里面没有GT)
counterexample:
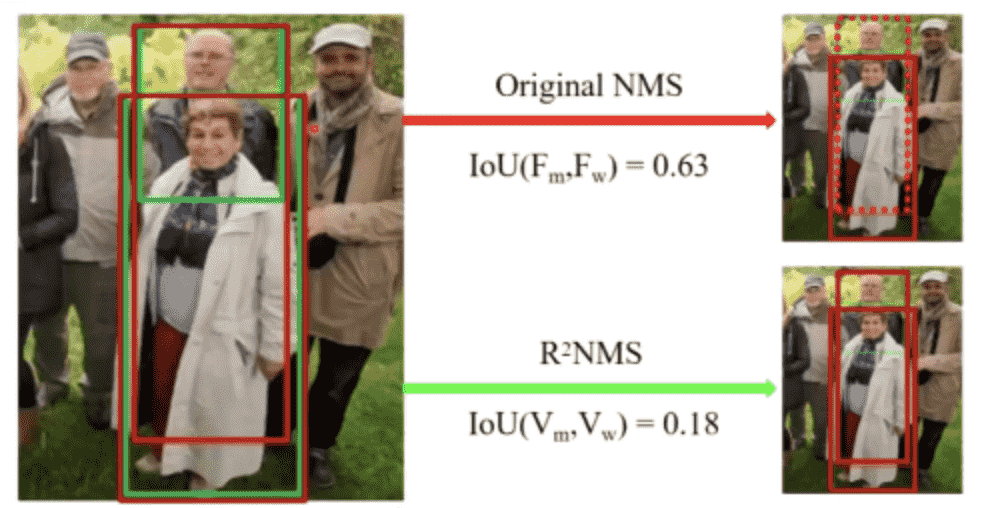
DETR
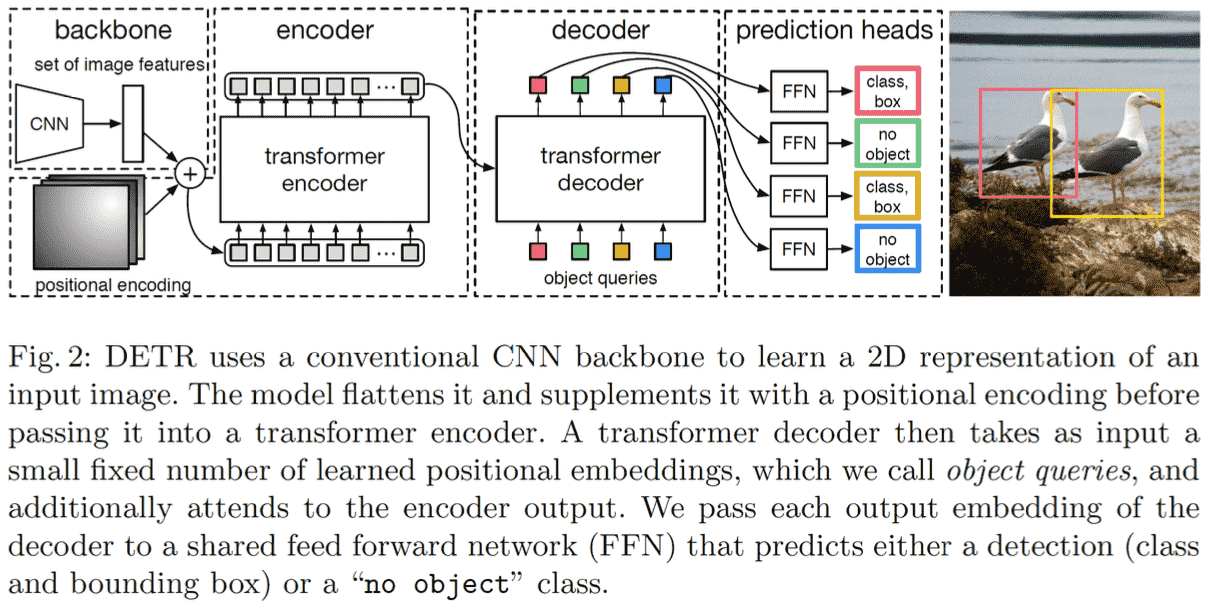
Architecture
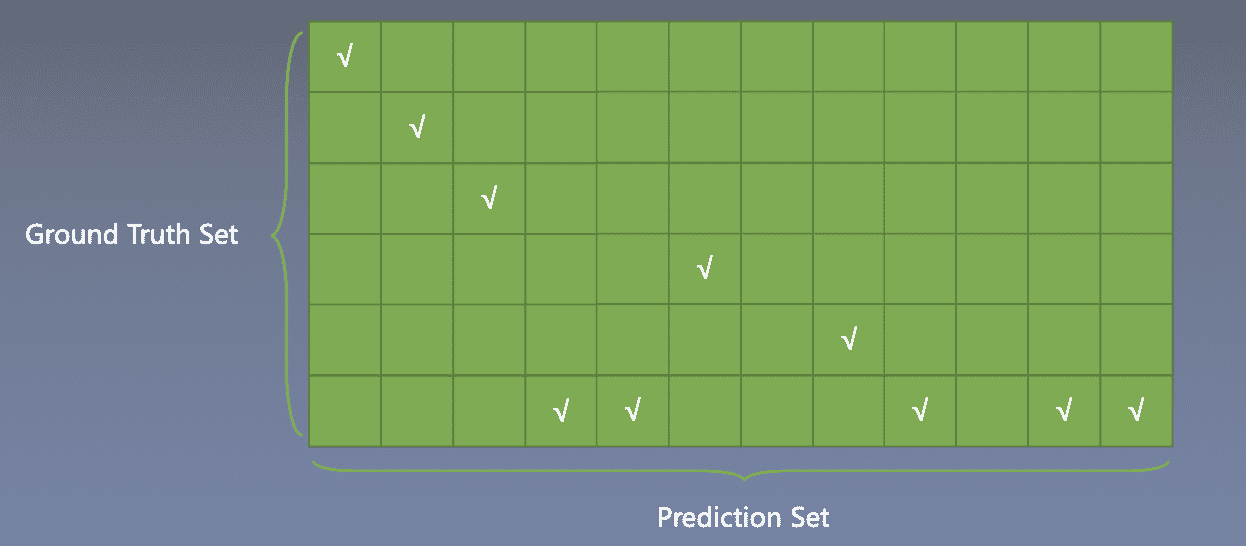
Set Prediction
问题:这是一个预测集和GT集之间匹配的问题,即集合是无序的,怎么给Target,怎么算loss?
解决方法:

这里的match-loss是回归loss和分类loss的加和,给下面这个矩阵填上loss,然后用匈牙利匹配找到loss最小的那种匹配方式, 此 时 loss 作为为最终 loss
匈牙利匹配调用scipy库
Position Embedding
这里的位置编码是固定的,不可学习的
具体写法是根据左边公式,其中pos代表token在序列中的位置,而d代表一个token用多少维来表示。 由于图像是2d的,因此DETR将这种方法推广到了2d。
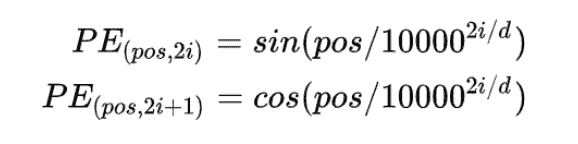
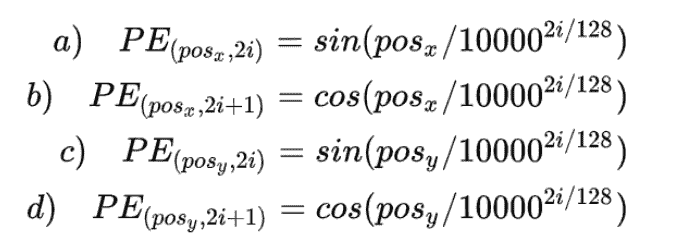
使用细节:
这里的位置编码会应用到每一个encoder上,而不只是开头的第一个 而且只会加到QK上,不影响V
原因: Patch间的信息交互才需要位置信息,也就是需要加到Q@KT这一步上。 而下一次生成QK,是根据V生成的,所以每一个encoder都要重新加一遍这个信息。
好的位置编码需要满足几个要求:
- 每个位置有独一无二的编码
- 相对的距离不随着序列长度的变化而变化
- 编码方式能作用于任意长度的序列
- 编码是确定的
推荐阅读:https://kazemnejad.com/blog/transformer_architecture_positional_encoding/
Encoder-Decoder
Encoder的位置编码会应用到每一个encoder上 而不只是开头的第一个 而且只会加到QK上,不影响V
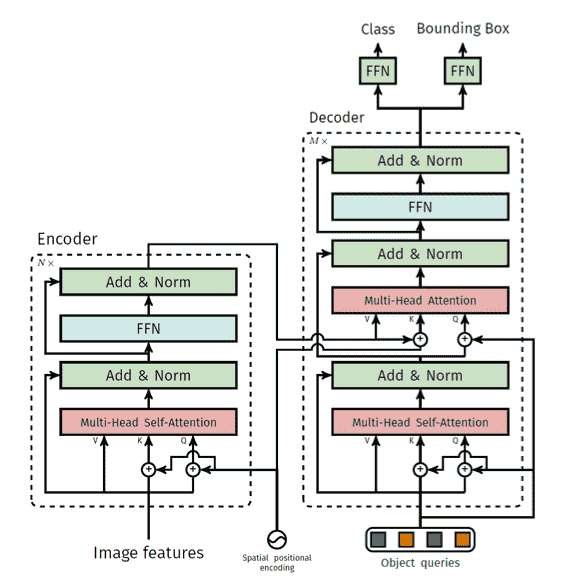
左侧为编码器,右侧为解码器 多出来的MSA,K和V来自于encoder 而Q是来自于Obj queries
这种来QK来自于不同地方的attention 也叫cross attention
Object Queries
Obj queries的作用和cls token类似,也是在整合信息。 Object queries是一个可学习的向量(num, b, dim)
-
Num是人为给的值,远大于图片内物体数量,默认100
-
b是batch size
-
dim是attention运行过程中用的维度数
Obj queries 最终学出来的东西类似于Anchor
Experiments
Resource : 16 V100 GPUs, 3days
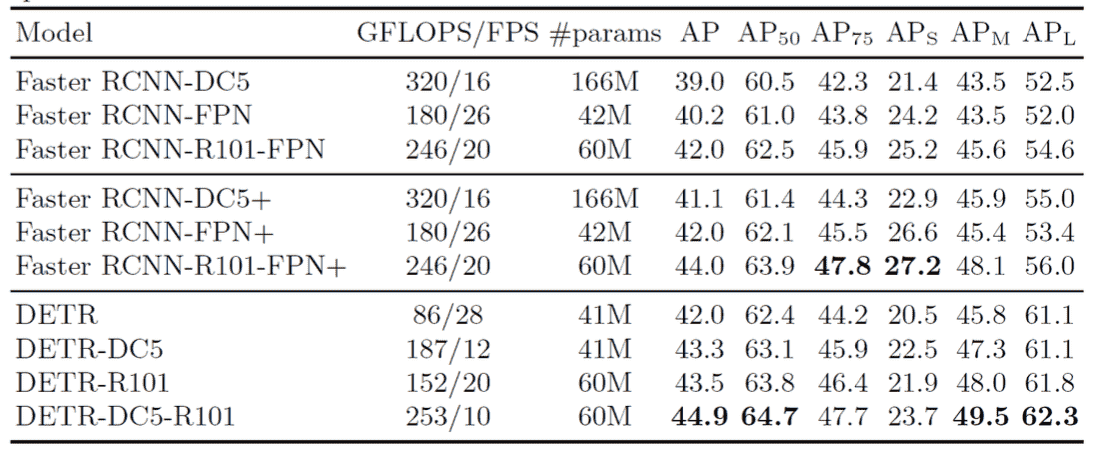
Ablation Studies
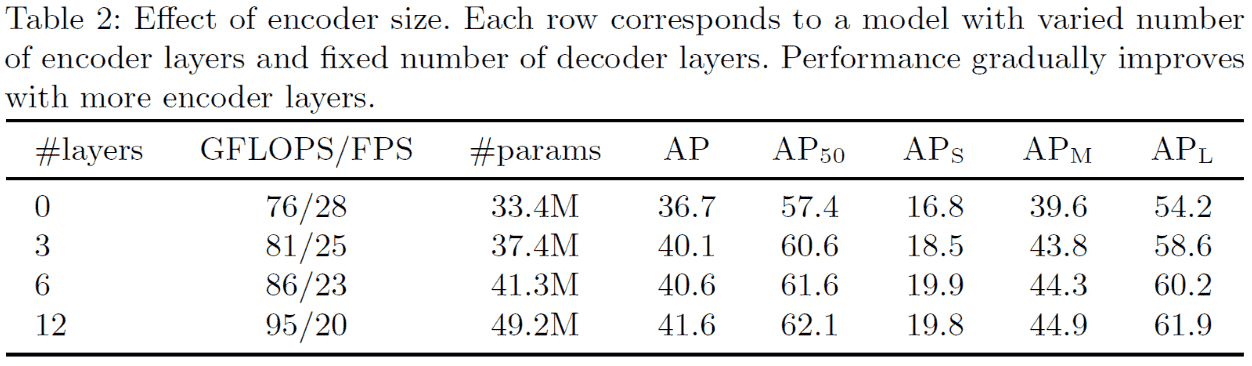
Encoder数量:
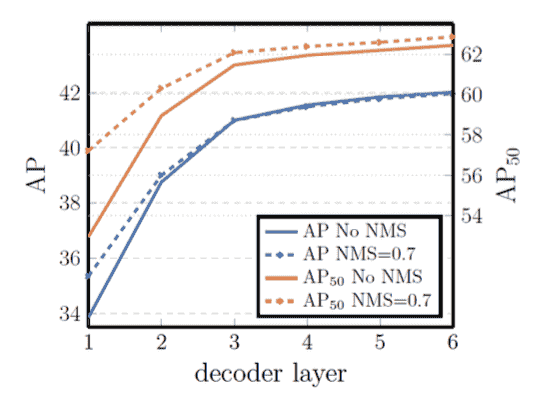
Decoder数量和NMS的作用:
不同的self attention方法:

如何实现 End2End ?
什么是End2End:无NMS
如果是set prediction的作用,是不是可以用CNN结构
Paper : End to End Object Detection with Fully Convolutional Network
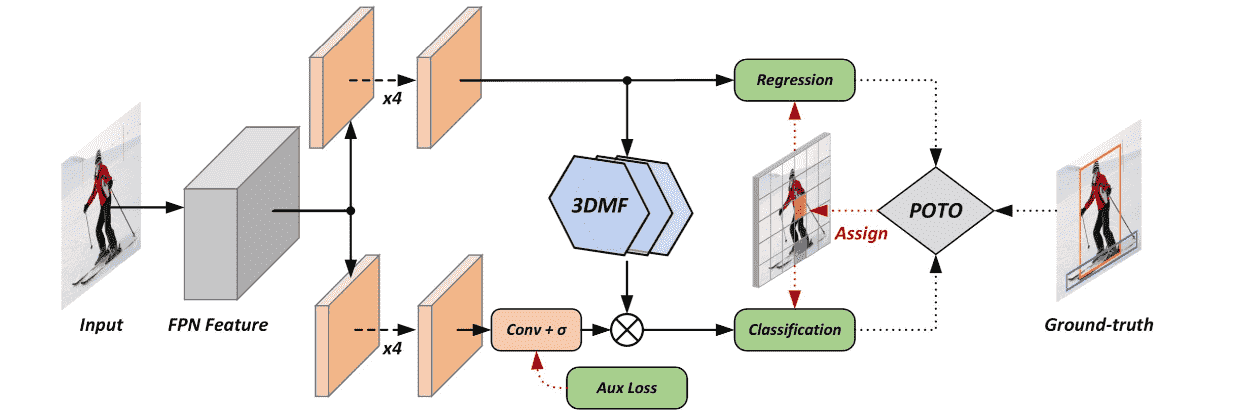
Experiments:
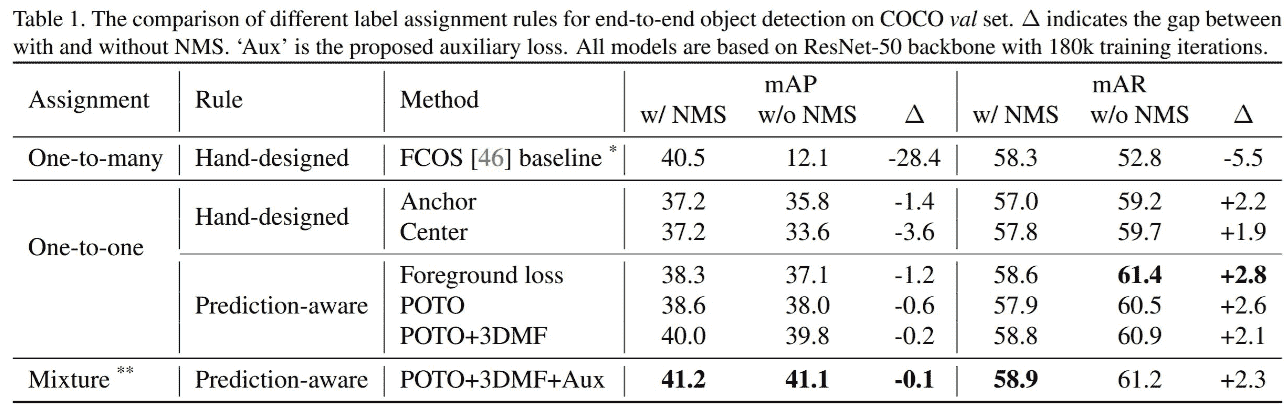
Conclusion:
-
一对一注册很重要
-
Pixel之间的比较也很重要
Conclusion
- Set Prediction
- Transformer 用在下游
DETR有什么问题? 在此基础上有没有什么创新的思路?
DETR的训练时间超长;DETR运行在分辨率最低的Feature Map上,小物体性能差
Idea: 我们需要金字塔结构