[TOC]
Background
DETR是一个简洁的pipeline,但几乎不可用 DETR提出了一套不同于Dense Prediction的pipeline,将检测视为一个Set Prediction问题,成功去掉了Anchor Generation和NMS。
Problem
计算量问题:但是在实际使用中,DETR在训练阶段面临难以收敛的困难,正常模型最多需要36个ep收敛,DETR需要500个ep,一个完整的训练需要8卡v100训练一周,开销过高。 在测试阶段,Transformer因为计算量的问题,只能在分辨率最低的Feature Map上运行,这导致小目标上的性能很差。
Contribution
提出了一种改进的Attention (?不知道算不算) 机制,收敛速度快,精度高。
Research Meaning
说明了DETR收敛慢的原因
引发了对Attention机制的一系列思考
Paper:Rethinking DETR
DETR的缺点
- DETR收敛慢。
- DETR小目标性能差。
造成这些缺点的原因
- Attention Map变稀疏需要很长时间
- Transformer计算量大,只能运行在最 后一层feature map上,这会导致小物体性能差。
稀疏度收敛问题
Paper: Rethinking Transformer-based Set Predition for Object Detection
稀疏度的计算(负熵): \(\frac{1}{m} \sum_{j=1}^m P\left(a_{i, j}\right) \log P\left(a_{i, j}\right)\) 矩阵中的0和1越多,这个数值越接近0.
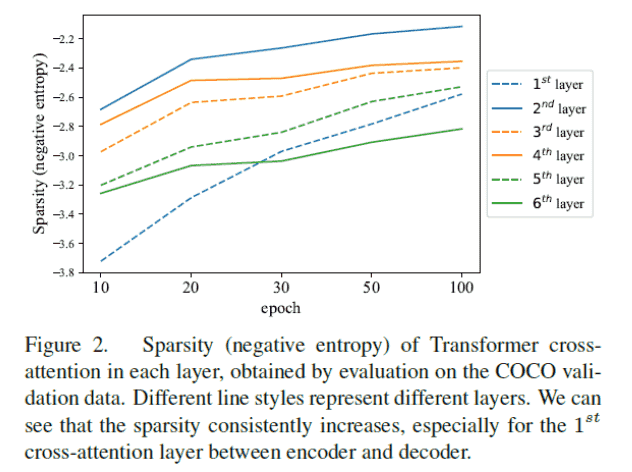
论文还猜想,匈牙利匹配的不稳定也可能是需要很长训练时长的原因。但是实验否定了。
论文结论是decoder造成了收敛慢。
小物体识别问题
下采样次数过多后,小物体会看不见,比较成熟的方案是用FPN, 用高分辨率的feature map预测小物体。
但是,Transformer计算开销过大。 高分辨率下面临计算资源不足的问题。
Solution
去掉 decoder

Deformable DETR
Architecture
- 主体结构和DETR一致.
- 利用了多层feature map
- 所有的 Attention 都是 Deformable Attention 这个词。

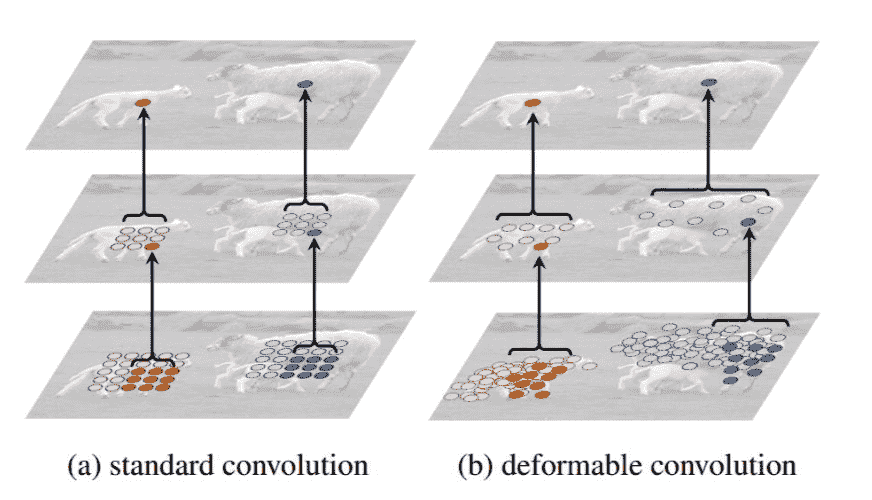
Deformable是什么?
Paper: Deformable Convolutional Networks
- Deformable指可变形
- 与标准的方形卷积相对应
- 参与卷积计算的点是可变的
Motivation: 希望Conv的感受野均来自目标instance上,而不包含背景
Implement:预测一个offset,之所以是2N的channel:一个N是x偏置、一个N是y偏置


Deformable Attention
公式表述
- Attention的另一种写法:

- Deformable Attention的写法:

Architecture
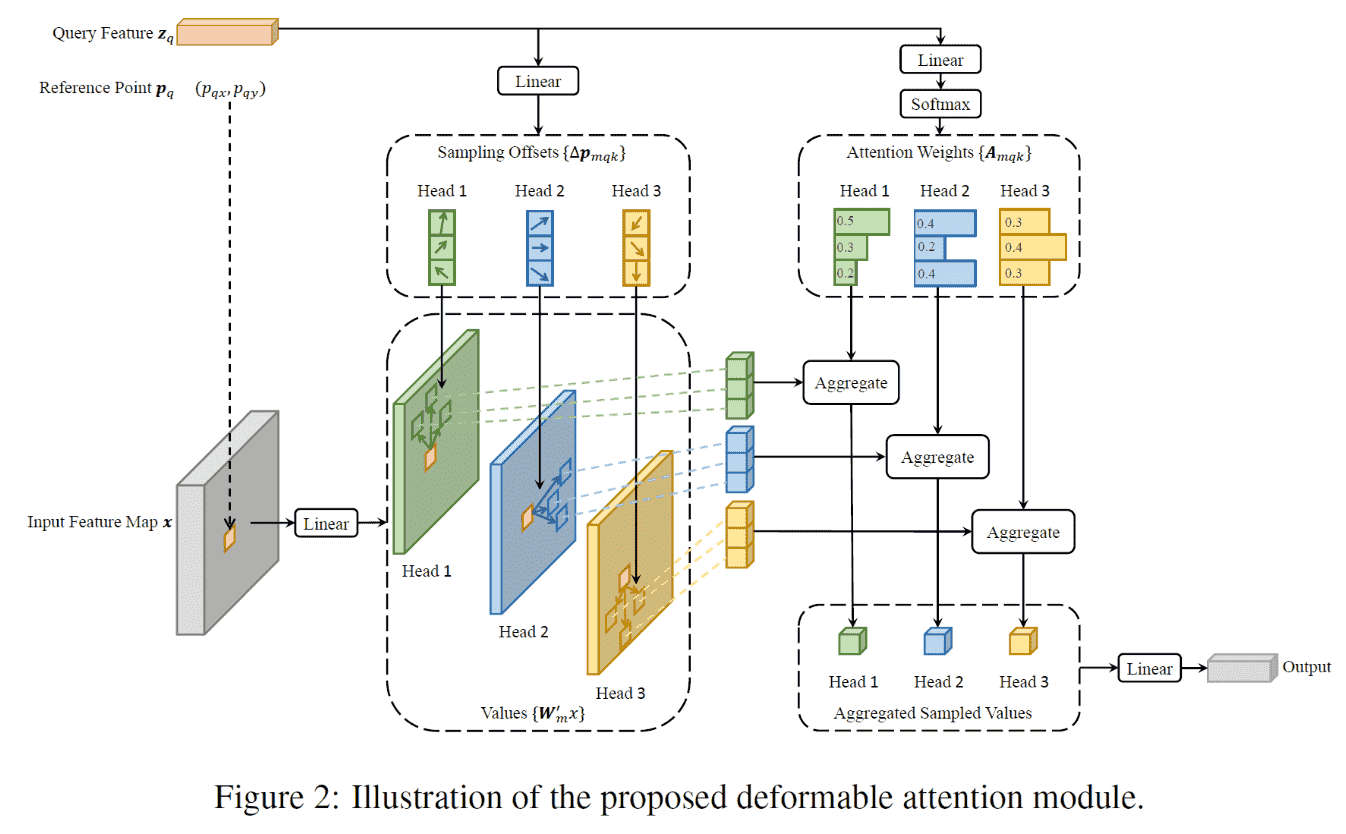
- Sample数量K提前定好
- V是通过offset找到的
- offset是linear(q)得到的
- 这里没有k
- Attention Map也是 linear(q) 之后过一个softmax得到的。
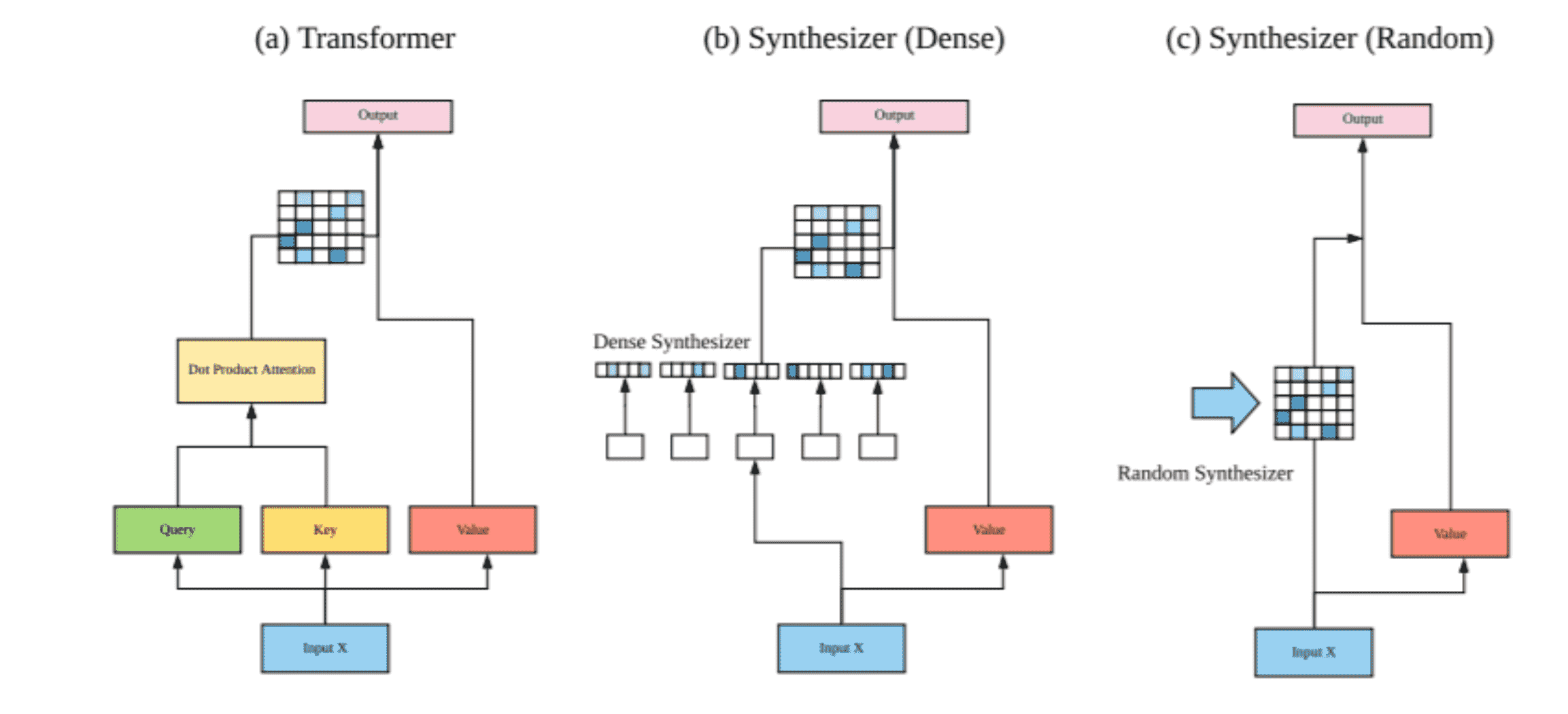
为什么 attention 是 Linear(q) 得到的?
Paper: Synthesizer: Rethinking Self-Attention for Transformer Models
最后结果证明Linear和Random效果也是可以的
MS Deformable Attention
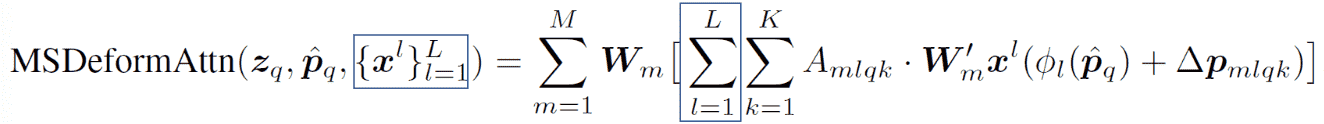
- MSDeformAttn代替了 Encoder中的MSA
- MSDeformAttn代替了 Decoder中的Cross-MSA
- 保留了DETR Decoder中 的MSA
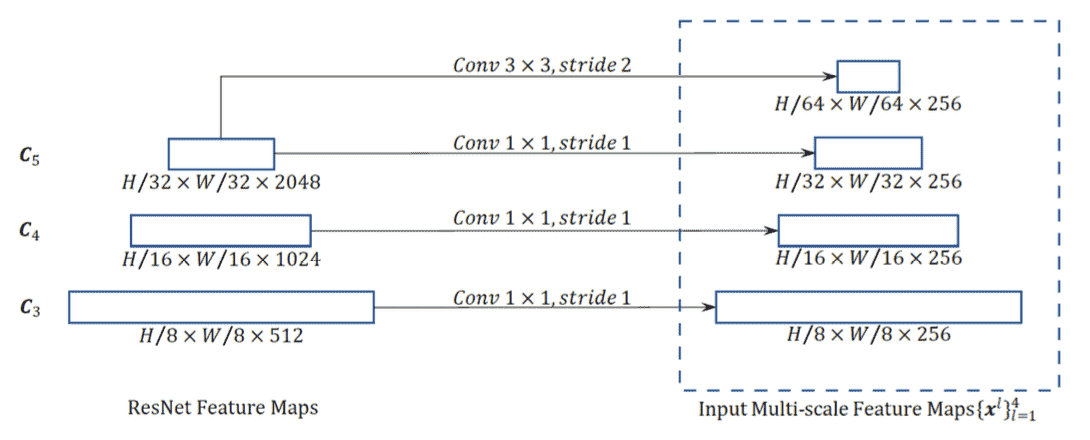
Deformable DETR Encoder
- 经过一个没有Top-down的FPN后得到4个feature map作为encoder输入
- Q为Feature Map上的一个点,为区分哪一层还多加了一个embeding
Deformable DETR Decoder
-
Decoder的输入是Encoder的输出
-
和DETR一样,Q是object query
-
Object query不在feature map上,公式里的 $p_q$ 怎么得到?
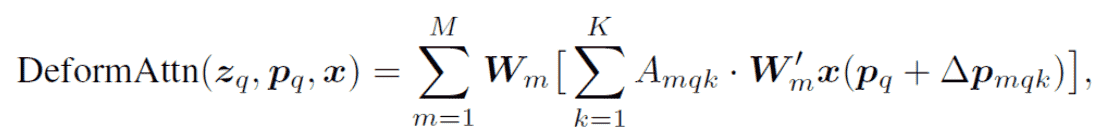
-
通过一个linear
-
还有一点不同,这里预测的box是相对于pq的偏移。
Iterative Bbox refinement
- 简单说就是把上一个decoder预测的bbox当作本个decoder的输入
- 有一点类似于Cascade RCNN

Two-Stage Deformable DETR
- 把Encoder中的每一个pixel当作一个object query。
- 预测出结果后,选Top score个当作decoder的object query输入。
- 有一点类似于Faster RCNN,这里encoder当作rpn,decoder当作rcnn

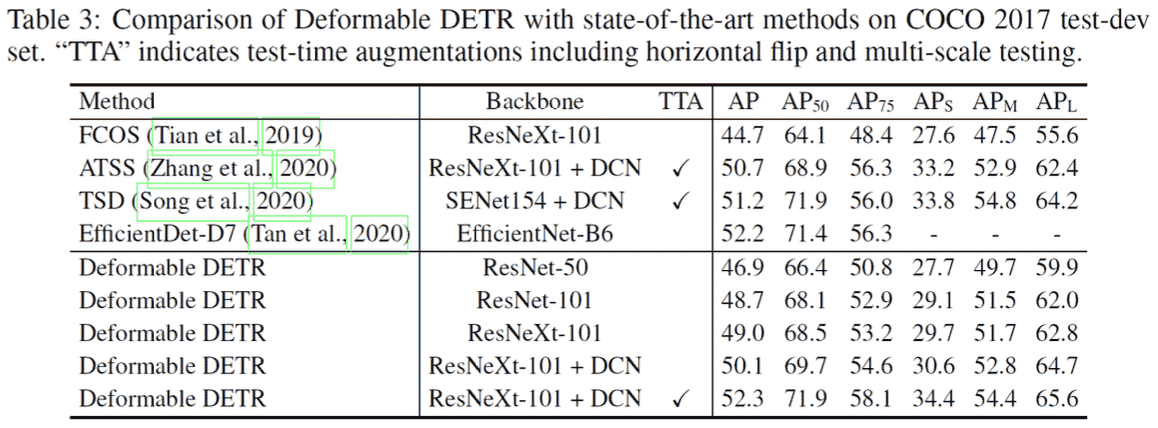
Experiments
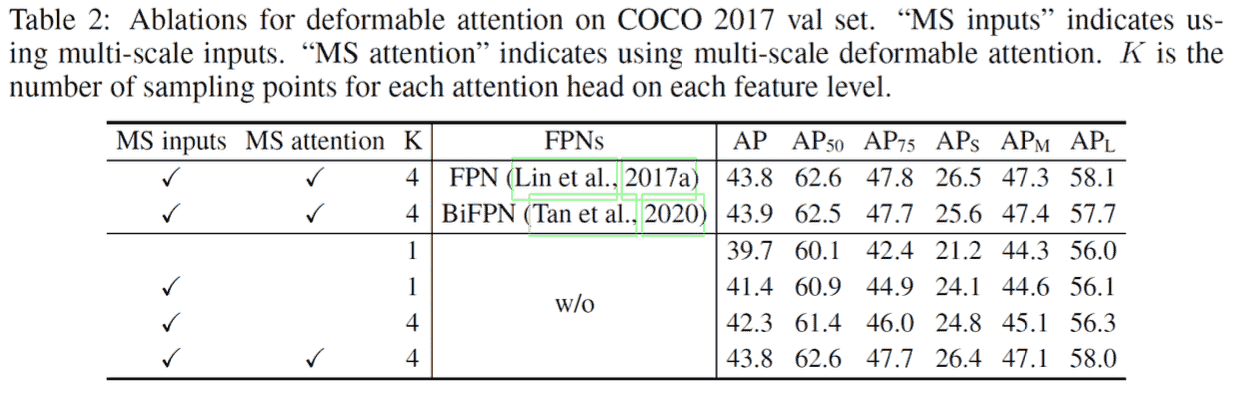
主要的设置follow了DETR,另外M=8,K=4(sampling points for each attention)

Ablation Studies
Attention及FPN的作用:
Conclusion
你觉得这还是Attention吗? 在Deformable Attn上有没有什么创新的思路?
这属于见仁见智的问题,区别与联系建议参考: Paper: An Empirical Study of Spatial Attention Mechanisms in Deep Networks
改进空间很小,这篇论文完成度很高。