[TOC]
Background
SpaseRCNN 是在 DETR 之后的一个工作,与 Deformable DETR 同期
DETR去掉了 Anchor Generation 和 NMS, 但是在Decoder中,Object Query 和 Feature Map上每一个点要计算一次 Cross Attention,这部分计算仍然是密集的,而这部分操作产生的Attention Map难以训练进而导致DETR在训练阶段难收敛的问题。
SparseRCNN提出了一种两阶段的纯Sparse模型,收敛快,精度高。
Research Meaning
-
提出一种纯Sparse的pipeline
-
用一种奇怪的方式在使用和理解 Object Query
Structure of Paper
abstract
- 原来的方法都是基于Dense Object Candidates,Anchor 数量和 feature map 的 size 有关
- SparseRCNN 只使用固定数量、可学习的 Anchor(h*w*k 减少为 N 个)
- 收敛快,精度高
Problem of previous research
- Anchor设计
原因:Anchor看数据集
- NMS 选择
原因:有数据集会遮挡
- DETR 收敛慢
Cross Attention中 Obj queries 和 Feature map 计算 attention 需要很长时间
Sparse RCNN
Dense to Sparse
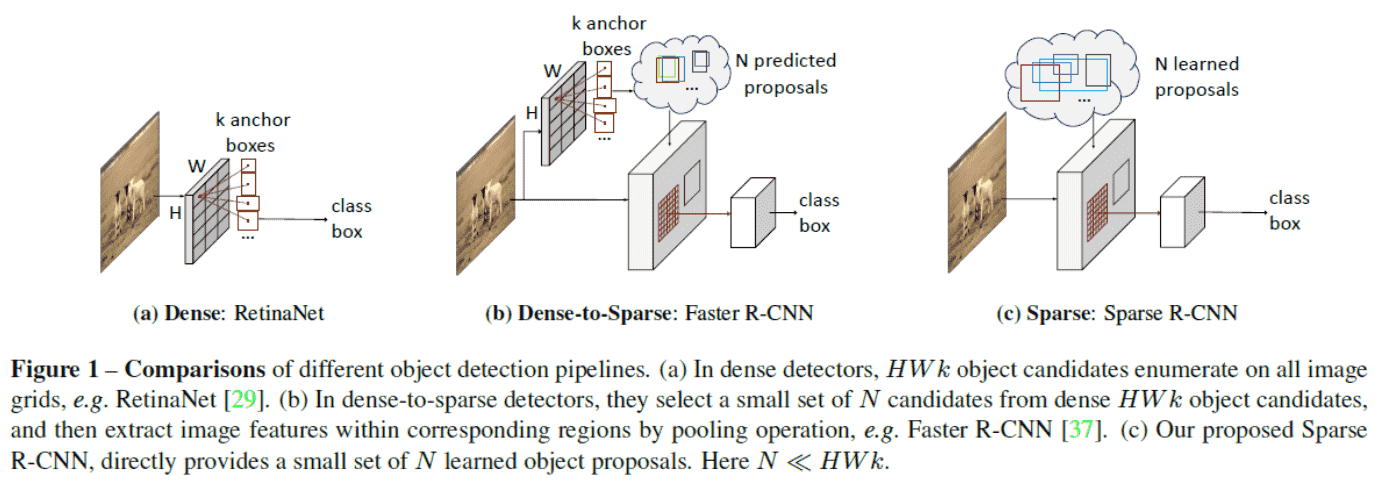
SparseRCNN 解决方案:
- 去掉Anchor
- 去掉NMS
- 把Object Query的职责分成两部分,一部分表示为代表定位的 Box,另一部分为代表内容的feature, 两者都是可学习的。然 后通过适当的交互,得到最后检测所需feature。
Architecture
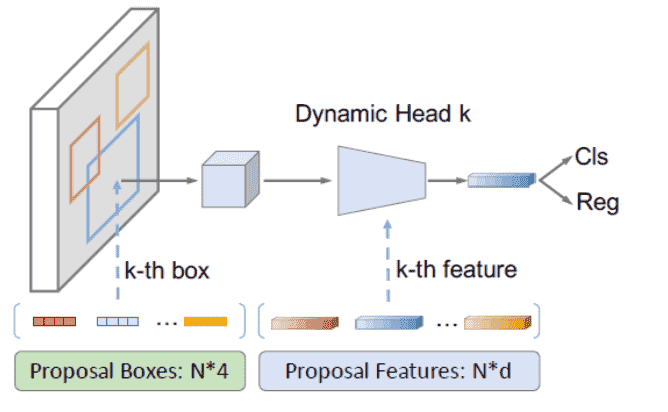

- 生成N个可学习的proposal boxes和N个可学习的proposal Features。前者用来去Feature Map上抠图, 后者用来生成 $1 \times 1$ Conv中的参数。
- Input -> Backbone+FPN -> Feature Map
- Proposal boxes去Feature Map上crop得到 $7 \times 7$ 的roi feature。
- Roi Feature和Proposal feature一起进Dynamic Head得到预测用feature。
- 过rcnn head出最后的预测结果。
Dynamic Conv
Paper: Dynamic Filter Networks 基本思想:在inference阶段之后,Conv中的部分参数应该是和输入有关的->所以是动态的。
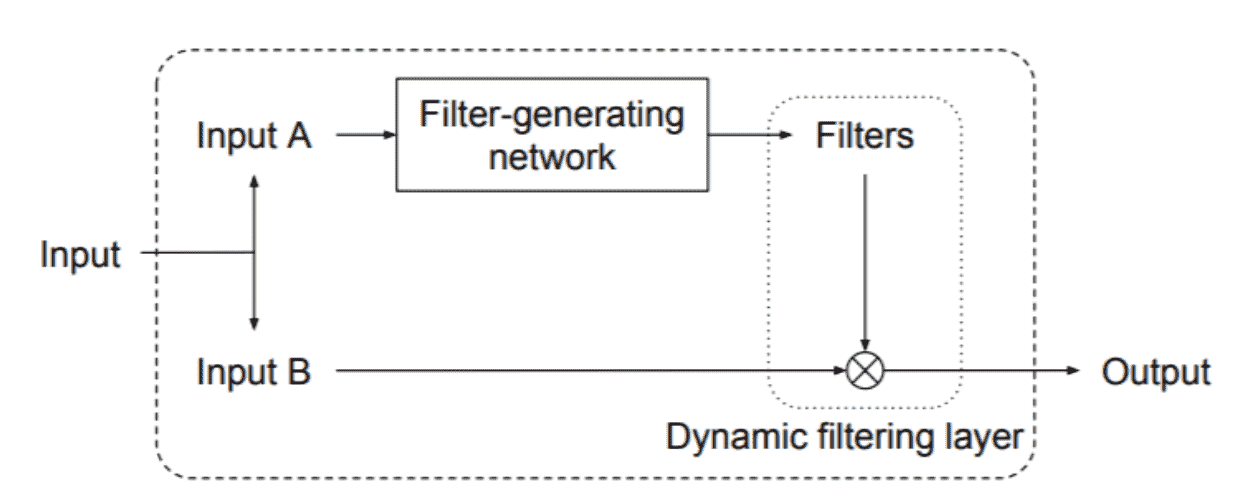
Dynamic Head
ROI (region of Interest) feature
每个Proposal大小不一样而RCNN Head中会使用nn.Linear,因此需要一个操作将大小不同的Proposal, resize到同样大小的Feature。 目前最优的操作是Roi Align (使用双线性插值取点) , 一般使用的目标大小为 $7 \times 7$.
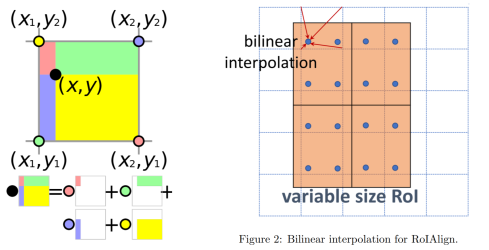
但是问题是 $7 \times 7$ 的 ROI feature 并不是都有用,因此需要 Attention,这就是 dynamic head 的作用。

Dynamic Head Architecture
Dynamic Head 和 Dynamic Conv 是一样的
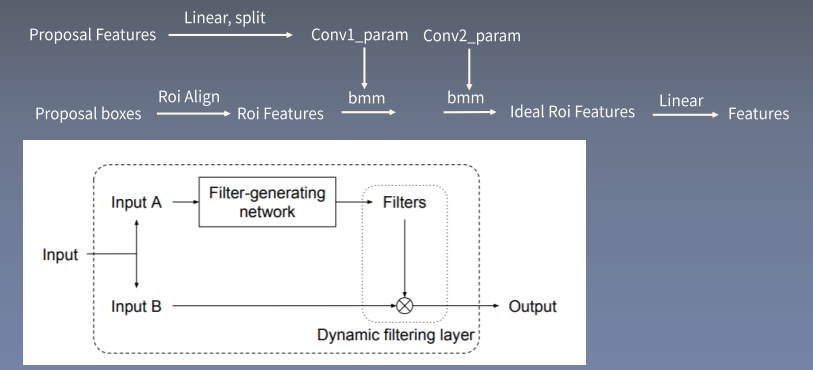
Code:
BMM 这一步本质上是为了拿到 attention,论文里面提到bmm 本质是1x1的卷积:


Iterative Refine
借鉴Cascade RCNN的思想,多个RCNN head串联, 下一个RCNN的输入是上一个RCNN的输出 这里预设的Proposal boxes和Proposal features都会被不断更新。
Experiment
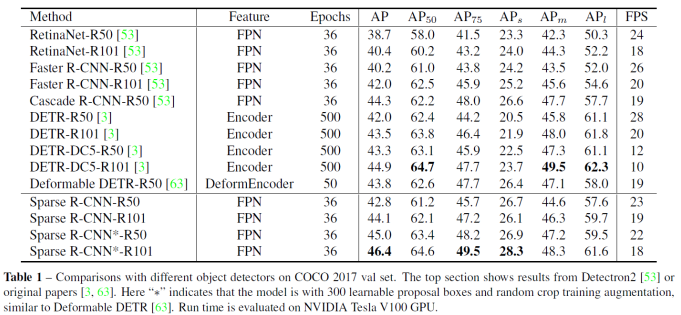
Ablation Study
做了Sparse、Iterative、Dynamic消融对比:
