[TOC]
Background
- Vision Transformer的结构设计越来越像经典CNNs
ViT是第一个使用纯Transformer结构做分类的论文
PVT修改了整体结构, 引入了CNNs中的金字塔结构, 使得网络对下游变得友好。
SwinTrans修改了微观操作, 限制了MSA中的交互范围, 降低了复杂度这种改动
模型从整体到微观越来越像经典CNNs
- Vision Transformer集成了很多先进的训练方法
实际上Vision Transformer在诞生之初, 就一直存在训练方面的不公平对比。比如, 更多的数据, 更长的训练ep, 更强的aug, 更好的优化器…
我们可以这样总结, 目前的Vision Transformer能一直刷榜, 是因为它既吸收了CNNs中的精华也利用到了CV其他领域中的进步点( 主要指训练recipe)
可以利用更先进的进步点来改进CNNs
Research Meaning
反思Vision Transformer的优势
提出了一种新时代的CNNs网络
给出了一种效果更好的CNN pipeline
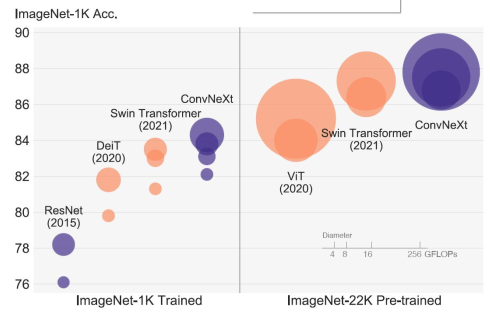
圆圈大小代表 FLOPs
Abstract
- Swin Transformer取得了在多种视觉任务上都取得了瞩目的性能。
- 虽然Swin是一个混合模型, 但其大获成功的原因更多的被归于Transformer的优越性。
- 因此我们设计了一整套复杂的实验来分析CNNs以及Transformer
- 具体而言, 我们给ResNet添加很多Vision Transformer的先进设置, 来观察其性能
- 最后我们从ResNet得到了ConvNext, 一个性能很不错的CNNs结构。
Motivation
- Conv 的应用支持很成熟
- 一些硬件设备支持的op有限, 一些新型op是没有的, 比如swin中的roll
- 针对Conv的加速方法很多, 哪怕flops相同, 部署到应用端时, Conv还是有优势。
- CNNs 比 Transformer 差多少?如果差,差在哪?
- Vision Transformer中有很大一部分性能并不来自于结构的优越。
Paper: DLViT https://arxiv.org/pdf/2106.04263.pdf
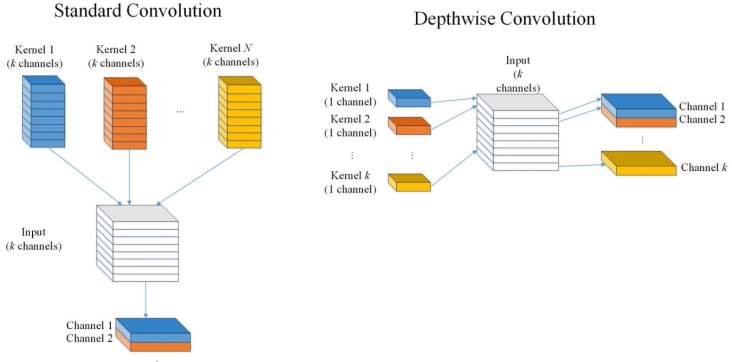
这篇论文用DW-Conv代替了Swin中的W-MSA, SW-MSA, 探究性能变化
能这样做是因为Dynamic Conv和W-MSA很像