[TOC]
Architecture
is all you need!
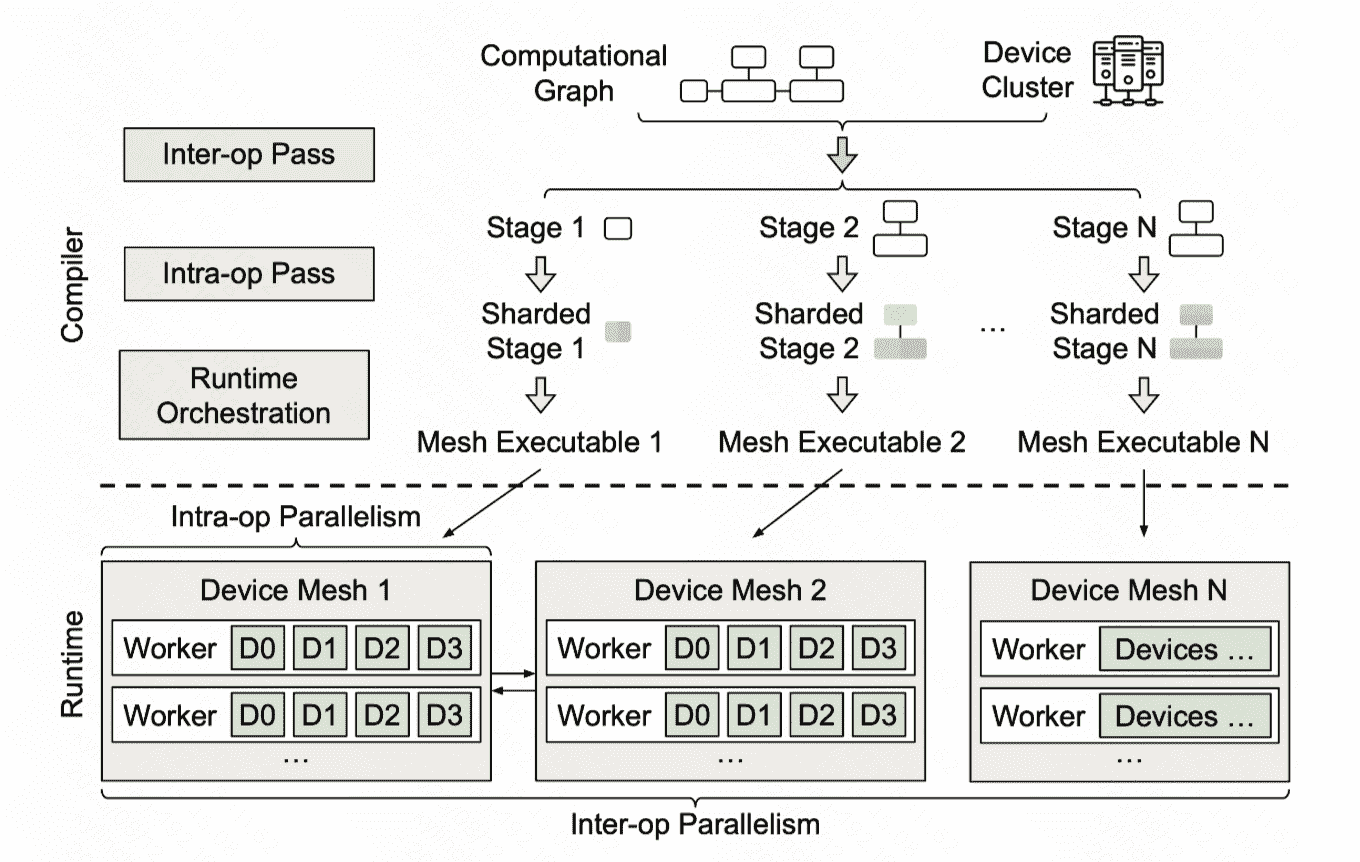
Framework
主要的idea:: 结合 intra-op 和 inter-op 两种并行策略,进行比较好的计算图划分、设备分配策略
什么是 intra-op 和 inter-op ?
- Intra-op: 对数据对划分、对算子的划分
- inter-op: 对计算图的划分,并用流水线方式运行(流水线方式和Operator parallelism最大的区别在于“Instead of partitioning ops, pipeline parallelism places different groups of ops from the model graph, referred as stages, on different workers”,即模型的不同部分放在不同的线程worker上,流动的数据在不同worker上是并行执行的)

整体架构分做四个阶段:
- Given a model description, in the form of a Jax intermediate representation (IR), and a cluster configuration, the inter-op compilation pass slices the IR into a number of stages, and slices the device cluster into a number of device meshes.
- ( inter-op 指派 subgraph(stage) 到 mesh )The inter-op pass uses a Dynamic Programming (DP) algorithm to assign stages to meshes and invokes the intra-op compilation pass on each stage-mesh pair, to query the execution cost of this assignment.
- ( inter-op call intra-op )Once invoked, the intra-op pass optimizes the intra-op parallel execution plan of the stage running on its assigned mesh, by minimizing its execution cost using an Integer Linear Programming (ILP) formulation, and reports the cost back to the inter-op pass.
- ( 回到 inter-op )By repeatedly querying the intra-op pass for each allocation of a stage-mesh pair, the inter-op pass uses the DP to minimize the inter-op parallel execution latency and obtains the best slicing scheme of stages and meshes.
所以,讲清楚 alpa 的 intra-op 和 inter-op 策略,论文的方法论部分就清楚了。
Intra-op
alpa 用了 SPMD-style intra-op parallelism 策略:partitions operators evenly across devices and executes the same instructions on all devices, as per the fact that devices within a single mesh have equivalent compute capability。
首先进行op合并,在code层面是jax op的聚合操作
intra-op并行策略的话,alpa只考虑sharding的通信损失,将其建模成一个 ILP 问题:
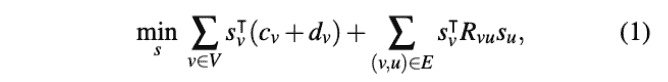
s是决策算法的one-hot向量,左边是算法的通信带宽cost和计算cost,右边是计算图edge进行resharding的cost
令d=0,因为论文假设每个设备的计算负载平均了:(1) For heavy operators such as matmul, we do not allow replicated computation. All parallel algorithms always evenly divide the work to all devices, so all parallel algorithms of one operator have the same arithmetic complexity; (2) For lightweight operators such as element-wise operators, we allow replicated computation of them, but their computation costs are negligible.
c、v的计算都是用通信bytes/mesh-dimension bandwidth.
Inter-op
Optimization goal: is to minimize the end-to-end pipeline execution latency for the entire computational graph.
这就涉及到三个地方:1)计算图划分、2)设备集群划分、3)子计算图-子设备群的配对指派
最终数学上的objective其实是优化流水时长:
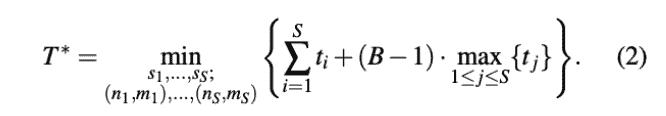
这里B=microbatchsize,第一项是一次流水时长,第二项是最长流水段时长的(B-1)倍。
- DP算法
转移方程:
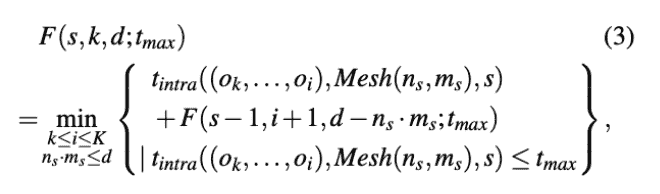
其中,s是stage,k是op数量,d是device数量,t_max是最长流水段
问题转化为:
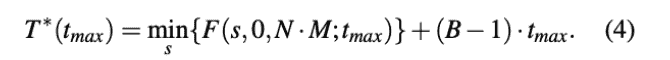
需要注意:
-
这里的logic mesh是枚举的的,总之只要axis_0*axis_1==device_nums,里面最好的一个
-
这里怎么会知道每一个段的执行时间呢?是真实测量的:We then compile the subgraph with this plan and all other low-level compiler optimizations (e.g., fusion, memory planning) to get an executable for precise profiling.
对于每一个intra-plan: IntraOpPass(stage,Mesh(nl,ml),opt ∈ LogicalMeshShapeAndIntraOp), 分别编译executable计算:
- stage latency (t_l)
- memory of stage (mem_stage)
- memory of intermediate activations (mem_act)
Performance optimization
- DP early stopping:早点停止没有意义的搜索
- OP clustering:利用重操作平衡、Flops平衡、input memory平衡进行op聚合
Experiments
Setup
使用模型:GPT-3 [10], GShard Mixtureof-Experts (MoE) [31], and Wide-ResNet [59]
设备:8 nodes and 64 GPUs. Each node is an Amazon EC2 p3.16xlarge instance with 8 NVIDIA V100 16 GB GPUs, 64 vCPUs, and 488 GB memory. The 8 GPUs in a node are connected via NVLink. The 8 nodes are launched within one placement group with 25Gbps crossnode bandwidth.
Metrics
alpa主要是测量在training时候的performance。paper 说因为alpa没改梯度聚合、同步算法,因此收敛速度、AI performance不用测了
- 系统稳定性 weak scaling of the system when increasing the model size along with the number of GPUs
- 集群浮点运算速度 aggregated peta floatingpoint operations per second (PFLOPS) of the whole clusters
Limitations
- Alpa没有对不同stage之间的通信成本进行建模,因为:alpa认为它很小、而且dp其实可以建模
- 没有考虑stage上分支的问题
- Alpa没有针对重叠计算和通信的最佳方案进行优化(mobius做了,真是难搞??)
- Intra-op目前有一个超参数:micro-batchsize B,alpa只能枚举进行搜索。