[TOC]
Mobius offload key insights:Note that we focus on extending GPU memory with only DRAM, since publicly available pretrained models can usually fit in DRAM and the limited bandwidth of SSDs is a performance bottleneck on a single server.
Baseline:
Gpipe(只使用GPU Memory)、Deepspeed(最先进的heterogeneous memory训练系统,但是pipeline只支持纯GPU的)
Challenge:
low interGPU communication bandwidth and pressing communication contention(通信争用) on the commodity GPU server obstruct training efficiency

Method:
Mobius partitions the model into stages and carefully schedules them between GPU memory and DRAM to overlap communication with computation.
1)怎么分:It formulates pipeline execution into a mixed-integer program problem to find the optimal pipeline partition.
2)怎么stage-GPU映射:It also features a new stage-to-GPU mapping method termed cross mapping, to minimize communication contention.
Contribution:
- profile existing fine-tuning systems on commodity GPU servers, and find that communication resources is the bottleneck (communication)
- A proposed system, Mobius, for fine-tuning large-scale models on commodity GPU servers. (Off-the-shelf GPU)
Gaps:
-
server GPU 有 NVLink,带宽有900G/s,远超PCIe的16G/s
-
server GPU 可以使用 GPUDirect:其核心原理是:在不必要的时候避免CPU的参与
GPUDirect是NVIDIA为其CUDA平台引入的一组技术,它们允许直接数据交换介于GPU与其他设备,如其他GPU或网络设备。其主要目的是避免数据在交换过程中不必要地通过主机内存,从而减少数据传输的延迟并增加系统整体的吞吐量。
GPUDirect的几个主要部分包括:
- GPUDirect P2P (Peer-to-Peer) Memory Access: 允许CUDA上的一个GPU直接访问另一个GPU的内存。这避免了CPU介入并减少了数据传输的延迟。
- GPUDirect RDMA (Remote Direct Memory Access): 这允许第三方设备(如网络适配器)直接读取/写入GPU内存,而不需要CPU的干预。这对于大规模高性能计算环境中的网络通信尤为有用,因为它可以减少通信的延迟。
- GPUDirect Storage: 这是一个新的技术,它旨在提高GPU与NVMe存储设备之间的数据交换速度。传统上,GPU处理数据时,数据首先需要从存储设备加载到CPU内存,然后再复制到GPU。但是,有了GPUDirect Storage,数据可以直接从存储设备传输到GPU,跳过了CPU内存。
- GPUDirect for Video: 这是为视频应用程序设计的,允许视频设备直接与NVIDIA GPU通信,从而避免数据通过主机应用程序。
Framework
3个方面的work组成mobius的一条pipeline:
1)Mobius : a novel pipeline parallelism to reduce communications
2)model partition algorithm based on mixed-integer programs (MIP)
3)cross mapping to map stages to different GPUs and reduces communication contention
1)Pipeline
- Gpipe Baseline:
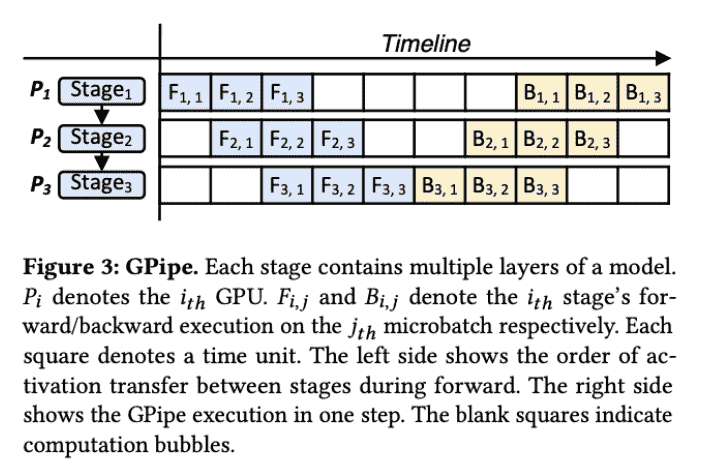
microbatch 是指流水线并行的batch
- Mobius:
这里也可以看出cross mapping的作用
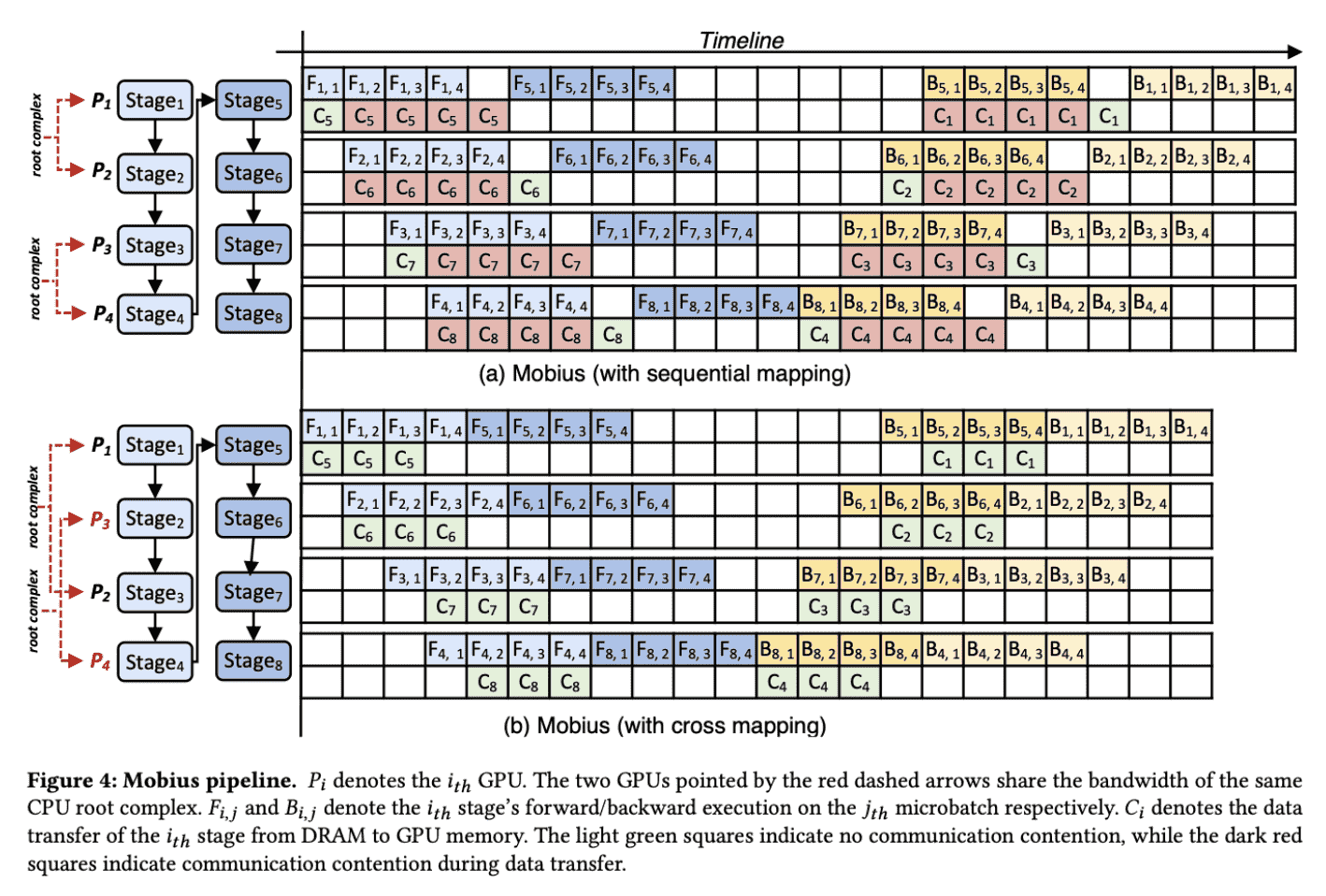
这里分析了这个pipeline的communicationTraffic,结论是DS需要在每一个GPU上load一次parameters,但是Mobius只需要一次load,所以结论是cost降低到1/N了。
2)Model Partition
利用Mixed Integer Program (MIP) 解决:
- 多少stage
- layer-stage mapping

Profiling 的时候做了层聚合,为了方便,但是没有细说算法
MIP 是用 Gurobi 做的
3)Cross Mapping
Based on the observation, Mobius maps adjacent stages to GPUs not under the same CPU root complex as much as possible, called cross mapping.
其实就是尽量把相邻stage不要分配到一个GPU上呗
这里有一个争用度的概念:对于 stage_i 和 stage_j,有两个观察:
1)i和j的绝对差越小,争用越大
2)若i和j在同一个root complex上,连接的GPU越多,争用越大
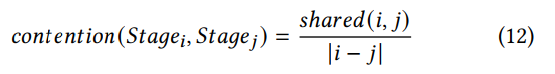
sh𝑎𝑟𝑒𝑑(𝑖, 𝑗) is the number of GPUs under the same CPU root complex where 𝑆𝑡𝑎𝑔𝑒𝑖 and 𝑆𝑡𝑎𝑔𝑒𝑗 are located. If the GPUs storing 𝑆𝑡𝑎𝑔𝑒𝑖 and 𝑆𝑡𝑎𝑔𝑒𝑗 are under different CPU root complex, 𝑠ℎ𝑎𝑟𝑒𝑑(𝑖, 𝑗) is zero
因此分配的优化objective为:
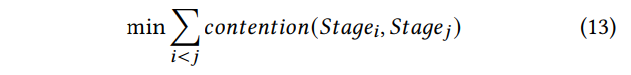
mobius 是枚举之后进行最小化的
还有一个trick是如果prefetch争用了,那个stage先执行就给它赋予高权限(cudaStreamCreateWithPriority),目标是避免之后更多的流水线阻塞。
Evaluation
Setup:
(first setup)1.5TB DRAM, two Intel Xeon Gold 6130 CPUs and 8×3090-Ti。Every 4 GPUs are connected to a CPU root complex via PCIe 3.0x8 and a PCIe Switch。
(second setup)EC2 P3.8xlarge instance,provides 4×V100 GPUs (16 GB memory) and enables GPUDirect P2P via NVLink with bandwidth of 300 GB/s.
并且尝试不同的GPU拓扑,这会影响 communication contention
The 3B model with batch size of 2 is the largest model that GPipe and DeepSpeed with pipeline parallelism can train
GPipe和DS不能完全适应offload,因此实验有很多妥协。
Metrics:
带宽CDF
每一个step训练时间