[TOC]
Motivation: 之前的 research 都是按照一个 static plan 进行系统执行,而且一般考虑到:model architecture 和 hardware specification,现在我们想整一个 workload-aware 的 。
SmartMOE split the process of automatic parallelization into two stages, performed offline and online, respectively.
Evaluation
setup
用了3个不同拓扑结构的Clusters:
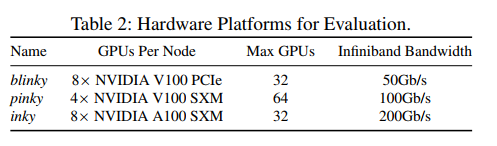
Model 用了 GPT-MOE 和 Swin-MOE
Baselines
- DeepSpeed-MoE
- Tutel
- FasterMoE
- Alpa
Metrics
training latency