[TOC]
一个绝好的教程:https://www.youtube.com/watch?v=80bIUggRJf4
KV-cache优化技术总结:https://zhuanlan.zhihu.com/p/659770503
KV-cache介绍
KV-cache本身就是model.generate baseline式的优化方法
- Attention的公式:
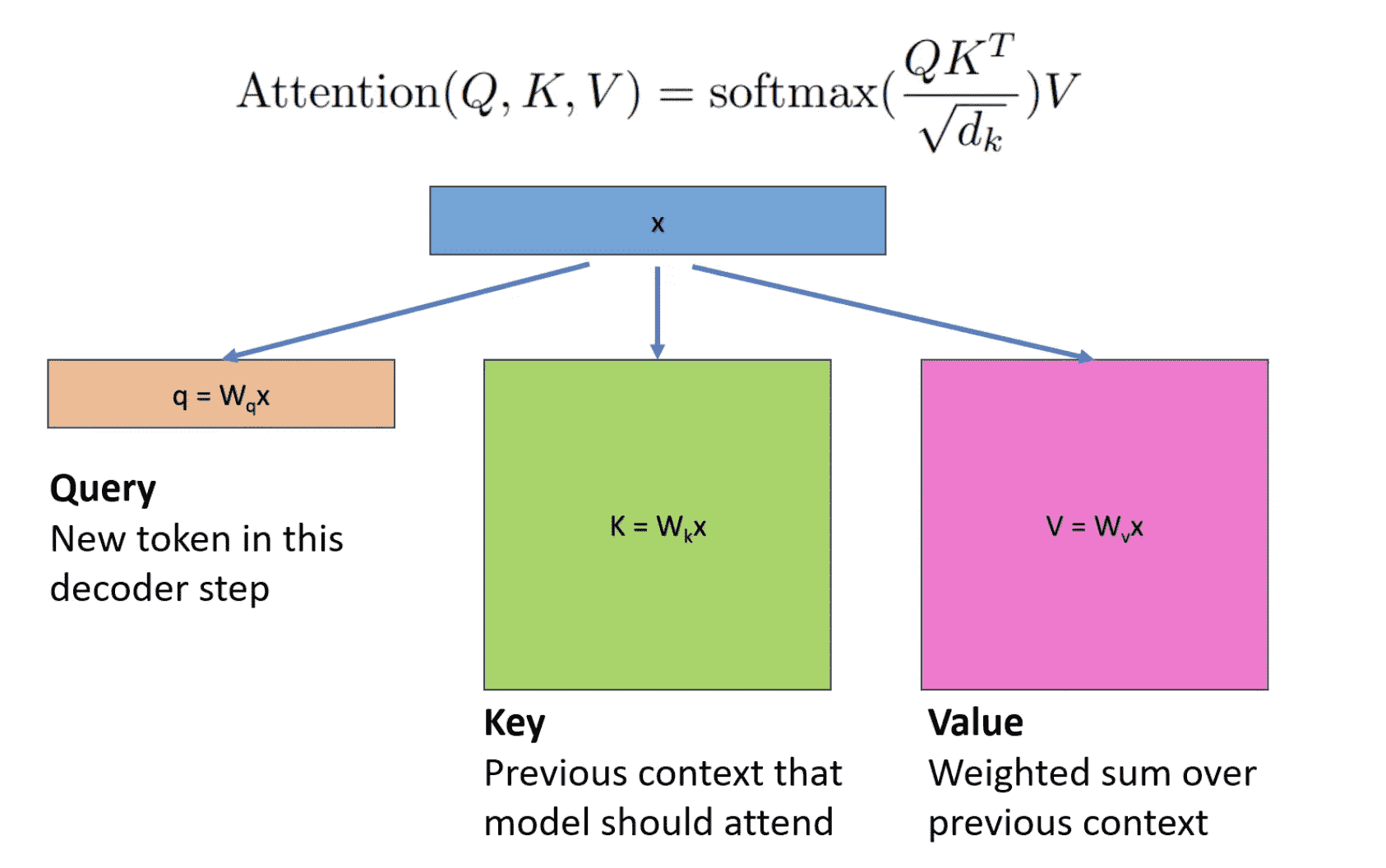
- Q是对于当前token的编码,但是K、V是对于之前+当前token的编码矩阵
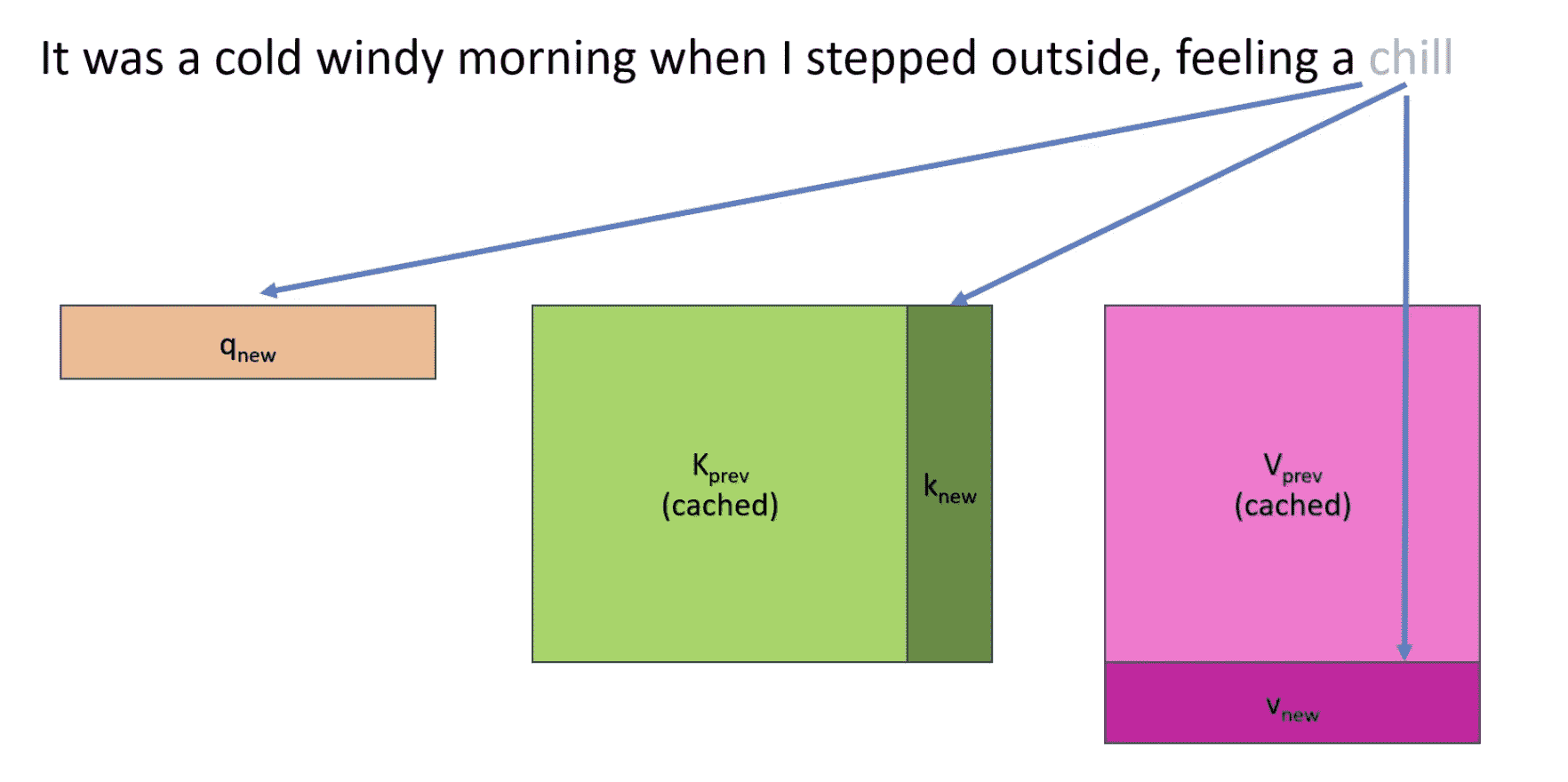
- 在Transformer架构中,只有self attention会进行token间交互,这里就会使用KV-cache:即记录下之前的kv矩阵
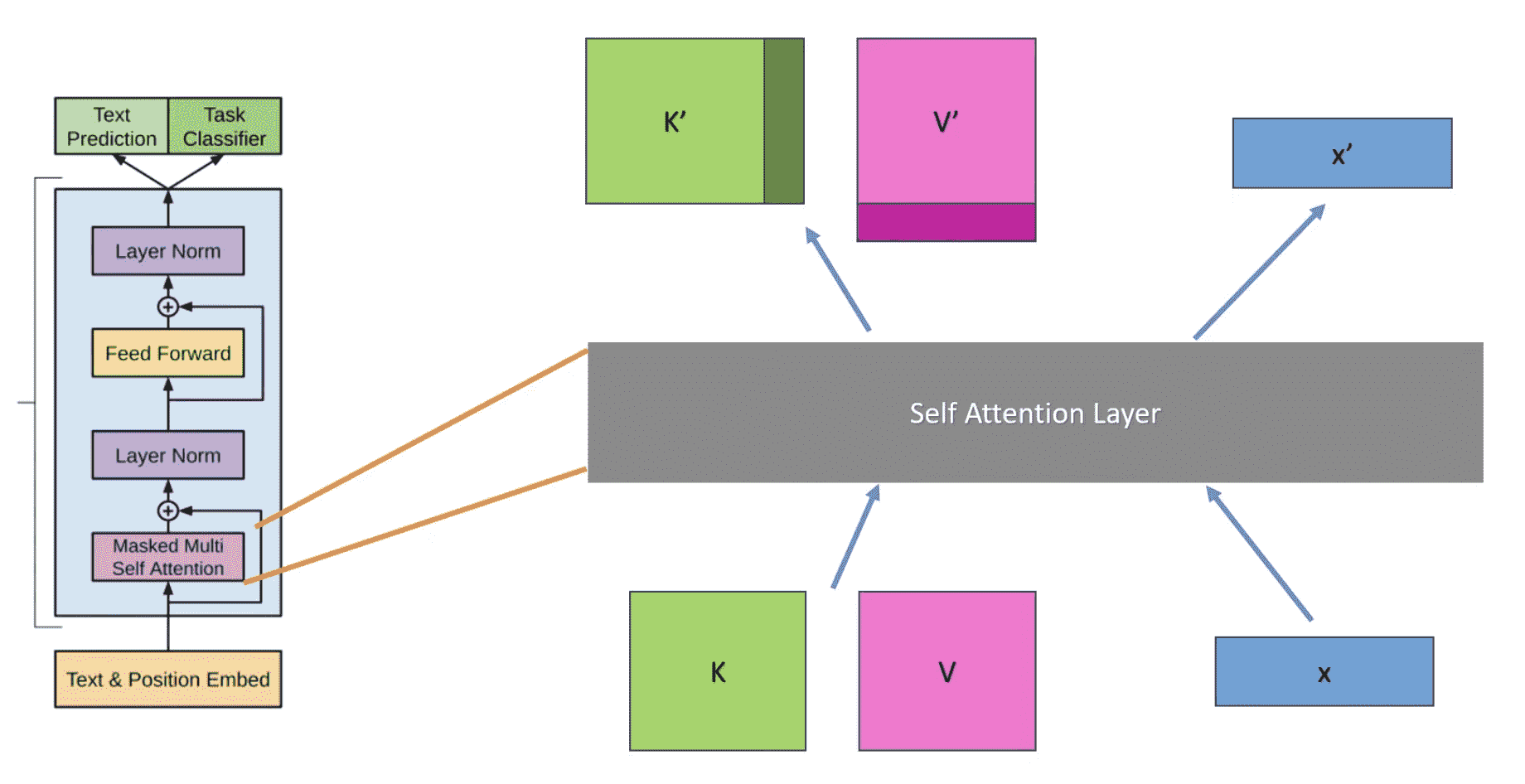
一般情况下,kv-cache常驻显存
KV-cache显存计算

- 例子:OPT-30B

- 例子:llama-7B
我计算了一下,在256 token的时候需要0.125G