[TOC]
Not Accept
Abstract
Computron, a system that uses memory swapping to serve multiple distributed models on a shared GPU cluster.
主要idea在于聚合GPU-CPU带宽,并用request-oriented调度的时间掩盖swap时间,并在实际service场景(it can tolerate real world variability factors like burstiness and skewed request rates)中,加速模型offload
项目地址:https://github.com/dlzou/computron
Intro
三个baseline:alpaserve、zero-inference、clockwork(https://dl.acm.org/doi/10.5555/3488766.3488791,OSDI, 20)
Arch
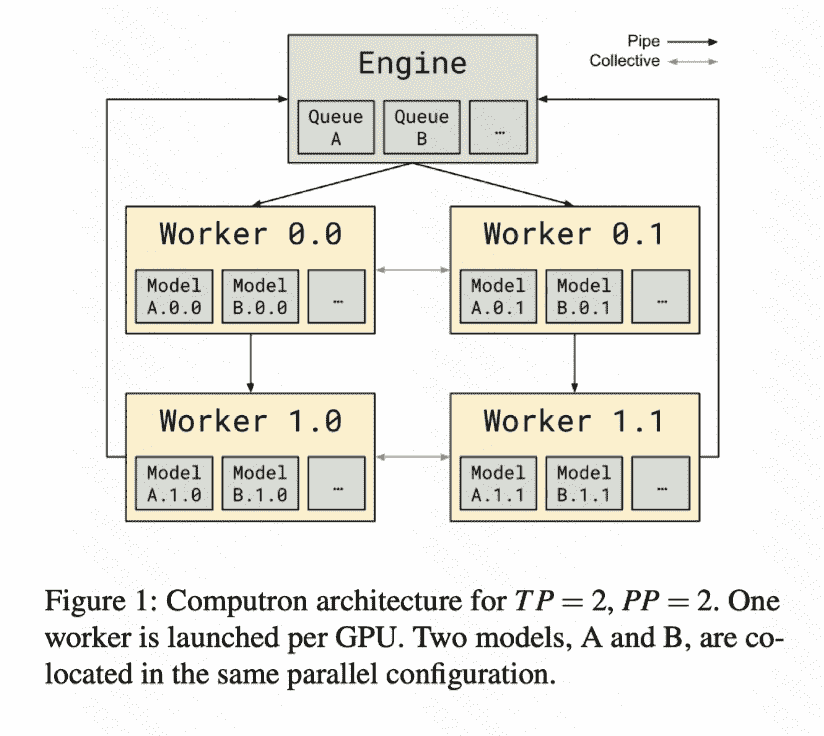
总体来说就使用了两个技术:
load entry/ batch entry scheduling
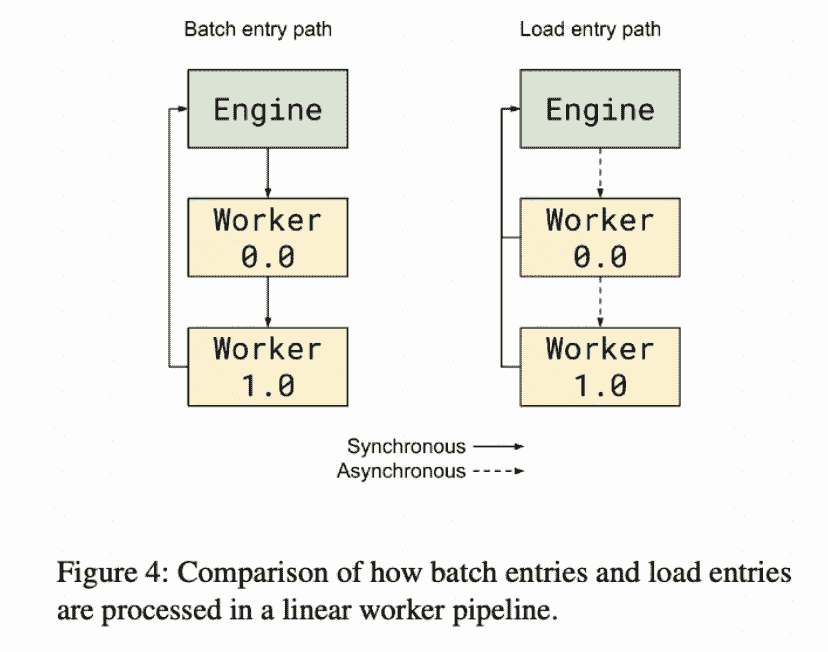
传统的load命令不会流水执行,相当于直接把一个model的所有stage同时load,这可能会造成流水线阻塞。
pinned memory
One more detail is the use of pinned memory. CUDA requires the CPU-side data buffer to be in page-locked memory during CPU-GPU data transfers to prevent interruptions caused by paging. Data objects on CPU are stored in paged memory by default, so data transfers would incur an extra copy on the CPU side from paged memory to page-locked memory. We eliminate this extra data movement by making sure that when a model is offloaded, the parameters are kept pinned in CPU memory.
- 可以参考的一个点,要是offload到cpu,得offload到page-locked memory
Experiments
Setup
设计了两个实验:
-
worst case worklaod
-
random arrival process
Device
We conduct experiments on a single GPU node of the Perlmutter supercomputer managed by NERSC. The GPU node has one AMD EPYC 7763 CPU and four NVIDIA A100 GPUs, each connected to the CPU through a PCIe 4.0 x16 link [9].
终究是但node
Metrics
主要是服务延迟 Latency
以及 Latency 的 CDF