[TOC]
IEEE TRANSACTIONS ON COMPUTERS
Abstract:
面向的应用场景是 图处理,图处理一般会存一些点、边关系在hard-disk or SSDs 上
massive expensive disk I/Os remain the major performance bottleneck of disk-based graph processing.
目标:加速图处理
两点观察:
1)可以把所有的点状态驻留在内存里
2)Redio introduces a dynamic selective scheduling scheme to identify inactive edges in each iteration and skip them when and only when such skipping can bring performance benefit。感觉应该是一种不常用内存offload策略
方法:
1)a compact edge storage to improve data locality
2)an indexed bitmap to minimize its memory and computation overheads.
Method
Arch
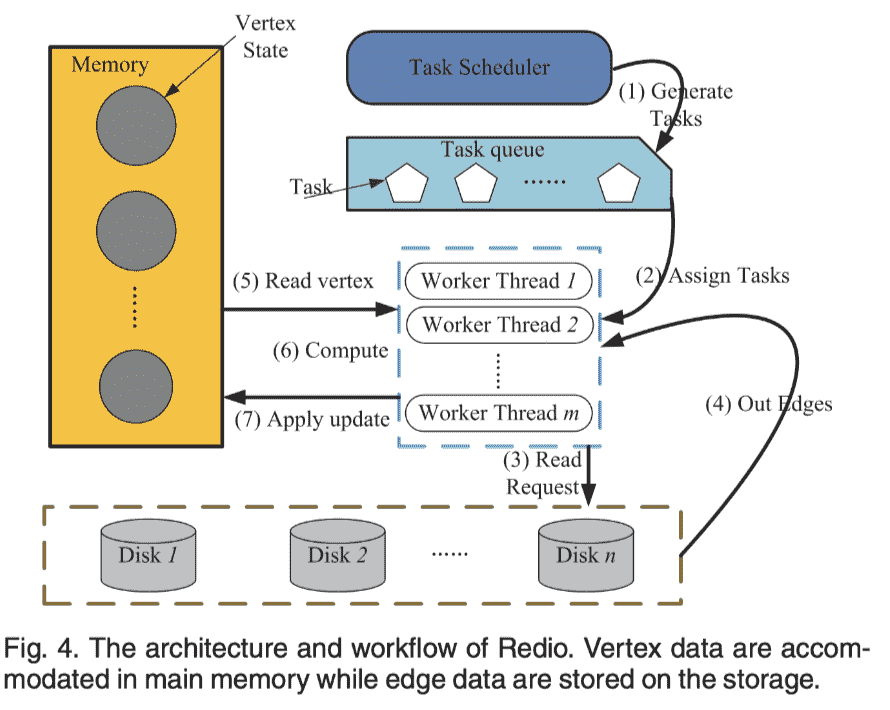
Fully Buffering Vertices in Main Memory
基于两个观察,buffer all vertex data in the memory to achieve high performance, and to store edge data on the storage for high scalability.
说建议存点在内存中,可以好好学学怎么argue的。
Dynamic Selective Scheduling
challenge:当要从disk读取边的时候,如果只读取active的,会引起随机I/Os,要是全部读取,会浪费disk bandwidth
solution:Redio introduces a dynamic selective scheduling scheme to skip inactive edges when and only when skipping is beneficial. To make it efficient, Redio incorporates a compact edge storage to improve data locality and an indexed bitmap to reduce computation and memory overheads.
- 合并activate blocks
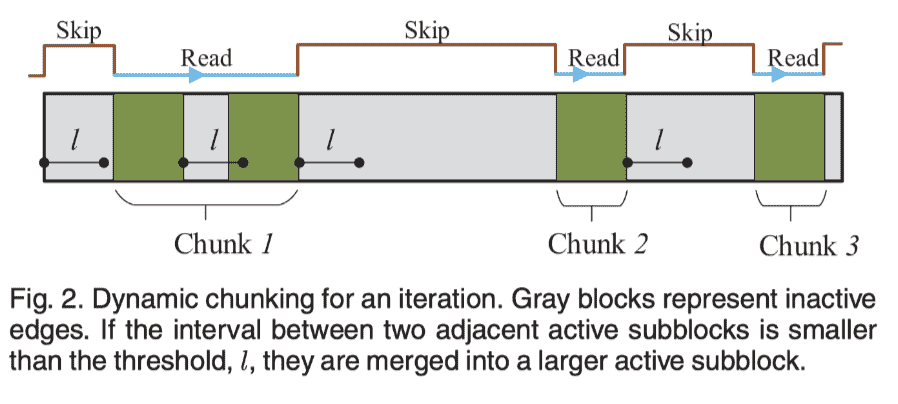
就是当两个活动边之间的非活动边小于阈值,就进行合并,目标减少随机disk访问
- BitMap:单纯记录谁是activate的
有一个说法可以学一下:
When most vertices are active, however, the index cannot reduce the scanning time, but this is fine because this means that Redio needs to read many edges in this iteration and thus the scanning time is relatively short compared to the I/O time.
Experiments
Metrics
-
speedups
-
储存压缩比例
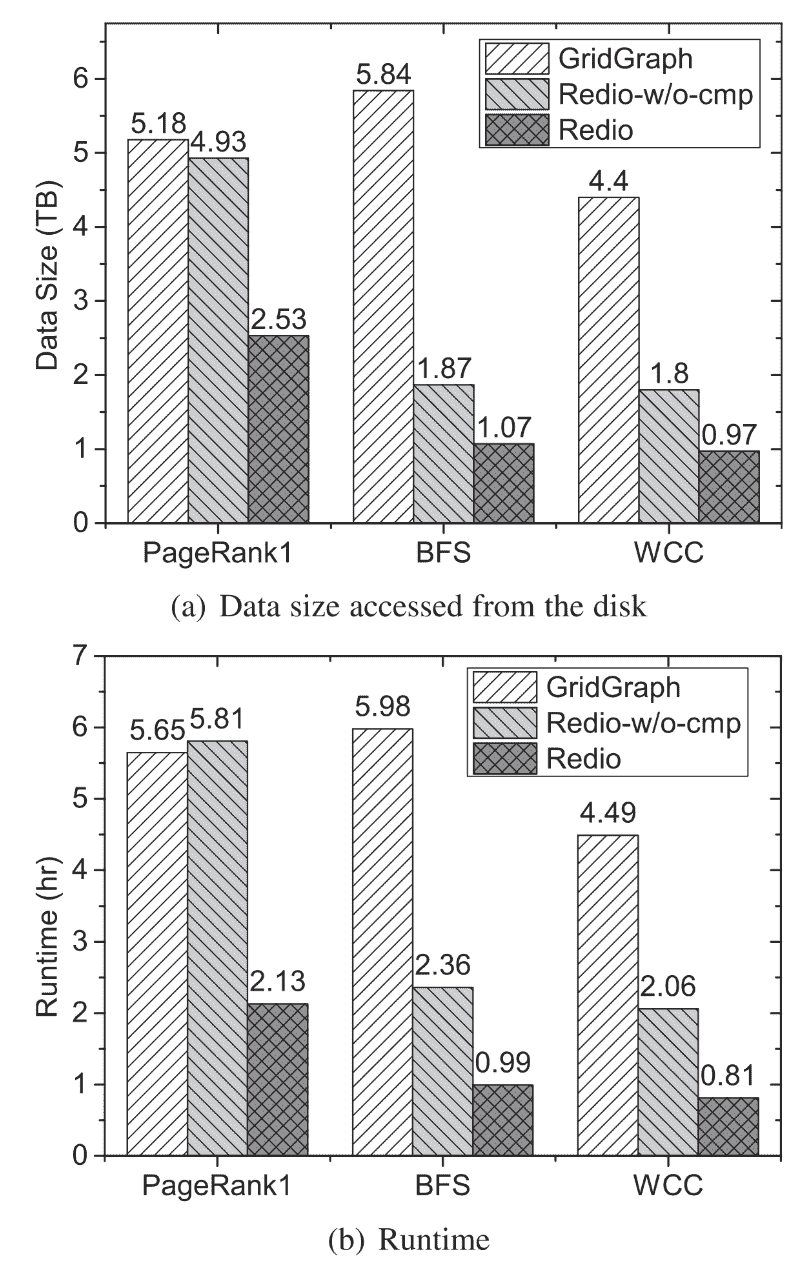
Disk I/O Analysis
compares the total disk I/O size
在文章里面做过一个分析:vertices’ accesses account for more than half of all accesses in a disk-based system and buffering all vertices can completely eliminate these I/Os,这个其实可以参考用来做我们的motivation
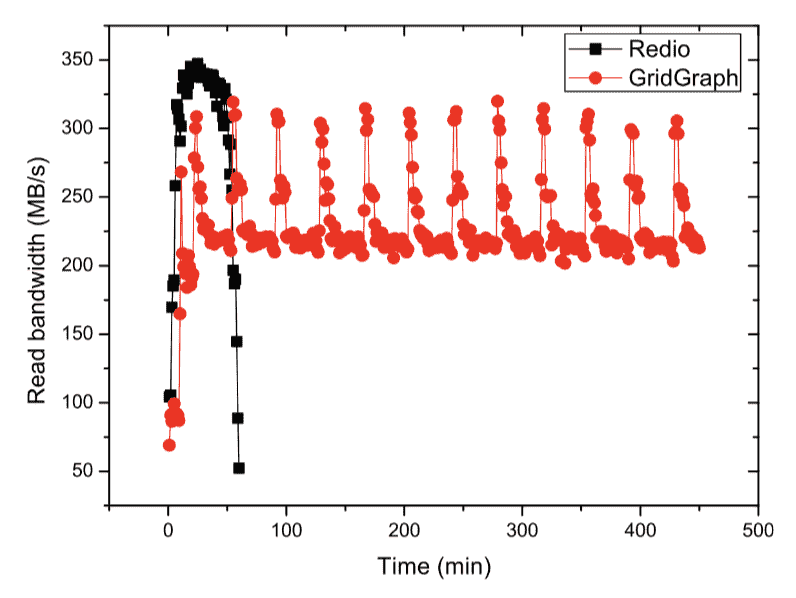
用 iostat对比I/O总读写和runtime,试图说明两者关联:
用iostat测量了I/O带宽,证明了系统的 I/O efficient: