[TOC]
Translate and Note from http://www.anyscale.com/blog/continuous-batching-llm-inference
由于 LLM 通过迭代生成其输出,并且 LLM 推理通常涉及内存而不是计算,因此在很多实践中,优化系统级批处理可以使性能差异达到10倍甚至更多。
Continuous batching = 动态批处理 = 基于迭代级的批处理
两个重要的结论:
-
LLM 推理是内存 IO 限制,而不是计算限制。换句话说,目前加载 1MB 的数据到 GPU 所需的时间比 1MB 的数据在GPU上计算所需的时间长。这意味着 LLM 推理的吞吐量很大程度上取决于您能将多少批数据装入到高速 GPU 内存中。
-
GPU 内存的消耗量随着基本模型大小和标记长度的增加而增加。如果我们将序列长度限制为 512,那么在一个批处理中,我们最多只能处理28个序列;一个序列长度为 2048 则批处理大小最多只能为7个序列。需要注意的是,这只是一个上限,因为中间计算结果没有留下存储的空间。
静态批处理
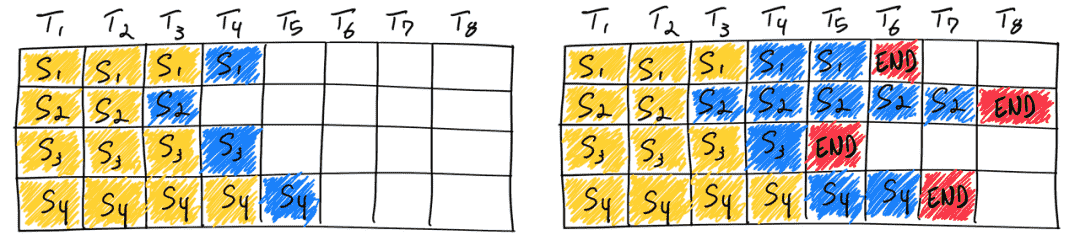
LLM 驱动的聊天机器人服务不能假定固定长度的输入序列,也不能假定固定长度的输出序列。在撰写本文时,专有模型提供的最大上下文长度超过8K个标记。使用静态批处理,生成输出的变化可能会导致GPU严重未充分利用(未充分利用部分是右图中的 blank cell )。
Baseline:Orca (osdi22)

一旦批中的一个序列完成生成,就可以在其位置插入一个新的序列,从而实现比静态批处理更高的GPU利用率。
现实情况比这个简化模型更复杂:因为预填充阶段需要计算,并且与生成阶段的计算模式不同,因此它不能很容易地与令牌的生成一起进行批量。
问题:计算模式有什么不同?
refer to Flexgen:prefill是矩阵x矩阵,generation是向量x矩阵
Continuous Batching
连续批处理框架目前通过超参数来管理这个问题:等待已服务比和等待结束序列标记的请求比(waiting_served_ratio)。
Experiments
Baseline
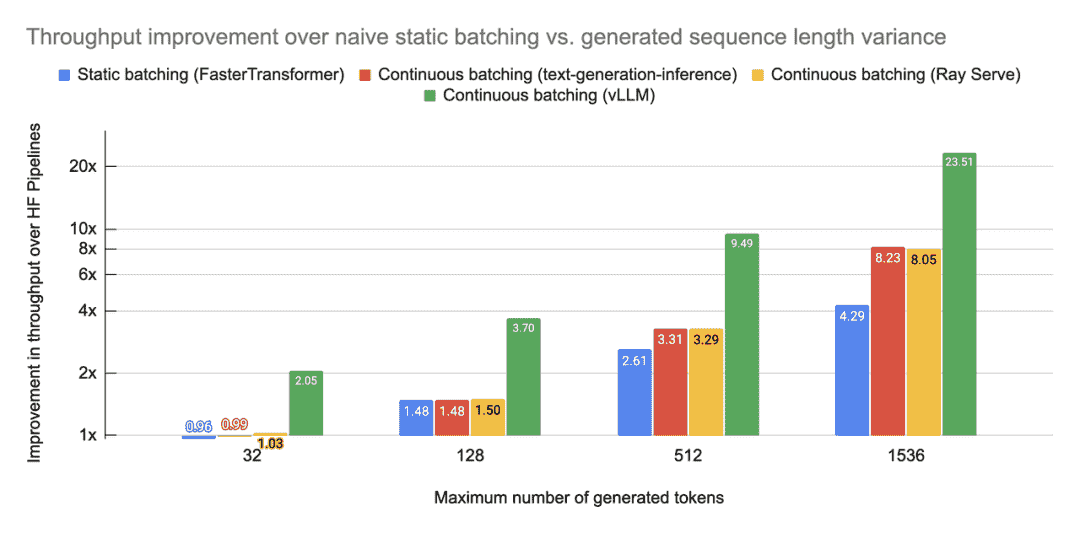
Throughputs测试
- Metrics
Tokens/second
- design
使用一个简单的基准测试脚本向我们的模型服务器提交 HTTP 请求。基准测试脚本以突发方式提交所有请求,使计算饱和。
- result
Laterncy测试
- Metrics
Second
- Design
在一个真实的用例上进行延迟-吞吐量权衡优化:对每个框架进行基准测试,并测量随着每个框架的累积分布函数(CDF)的变化,该函数如何随着每个框架的部署而变化。
实验没有像在吞吐量基准测试中那样同时提交所有请求。而是通过预先延迟每个请求一定的时间来进行基准测试。
通过泊松分布来确定每个请求提交后等待多长时间。泊松分布由λ和Queries Per Second(即每秒击中模型端点的查询数量,QPS)进行参数化。我们测量在 QPS 为1和 QPS 为4时的延迟,以了解随着负载的变化,延迟分布如何变化。
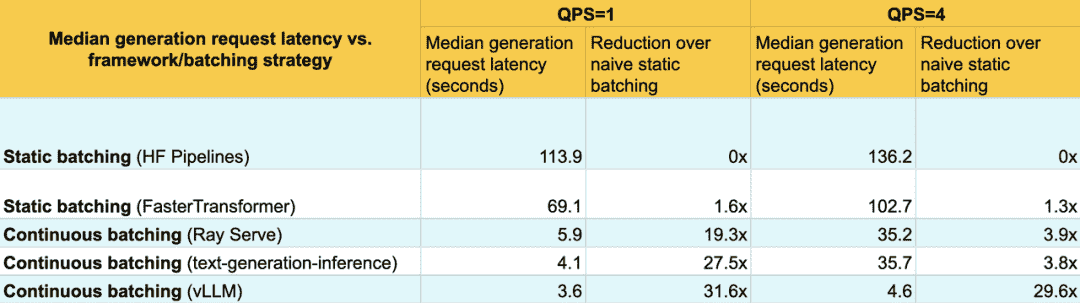
可以看到,在提高吞吐量的同时,连续批处理系统也改善了中位数延迟。这是因为连续批处理系统允许在有空间的情况下,将新的请求添加到现有的批次中。
并且在所有百分位数上都得到了改进:
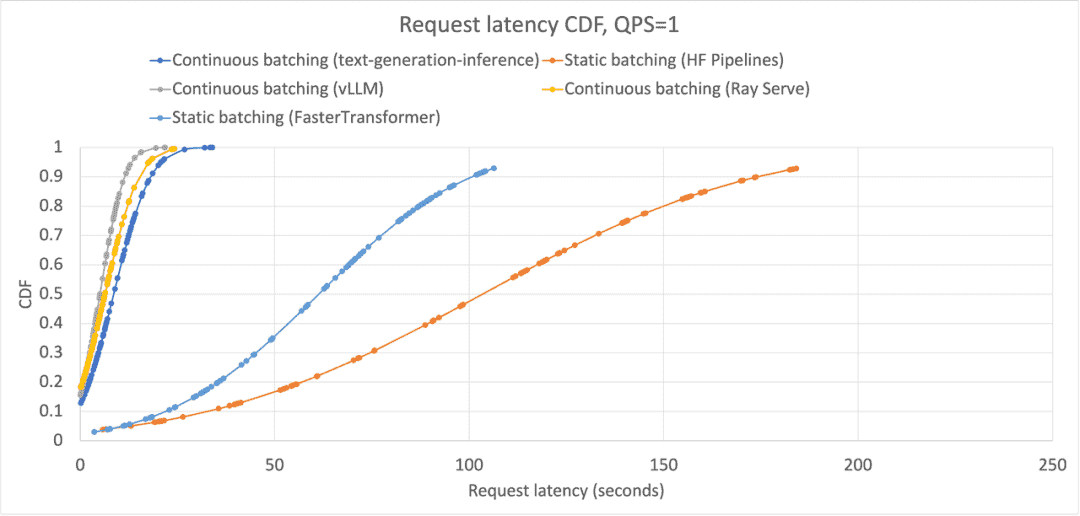
However, like static batching, continuous batching is still limited by how much space is available on the GPU. As your serving system becomes saturated with requests, meaning a higher on-average batch size, there are less opportunities to inject new requests immediately when they are received.
随着QPS增加,GPU预留空间的期望变小,因此static和continous的差距也在变小:
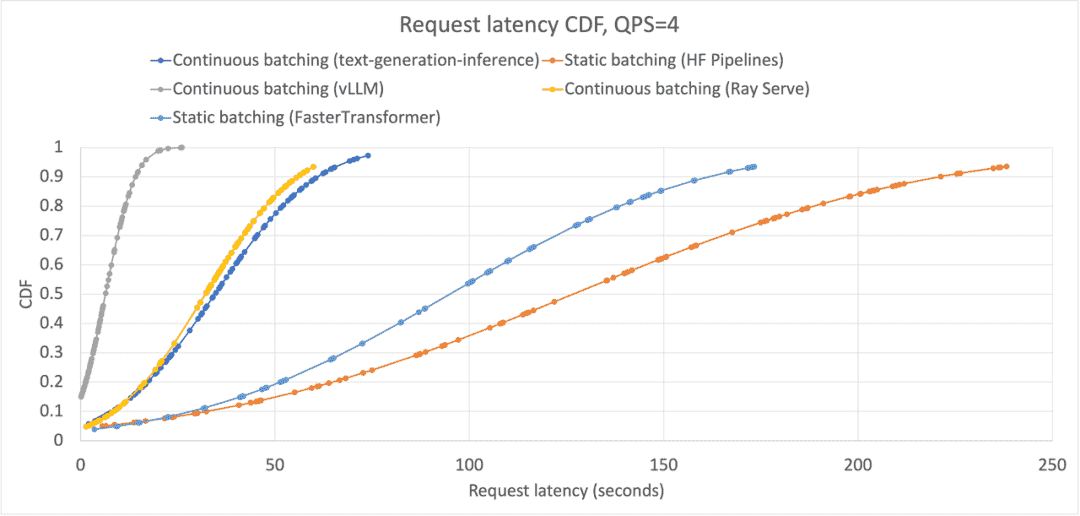
we have shown that continuous batching significantly improves over static batching by
- reducing latency by injecting new requests immediately when possible
- enable advanced memory optimizations (in vLLM’s case) that increase the QPS that the serving system can handle before becoming saturated.