[TOC]
Background:Deployment of 10-100 billion parameter models is still uncertain due to the latency, throughput, and memory constraints.
Contribution:
EnergonAI adopts a hierarchy-controller system architecture to coordinate multiple devices and efficiently support different parallel patterns.
Technics:non-blocking pipeline parallelism, distributed redundant computation elimination, and peer memory pooling
这里回答了一个问题:为啥要多个host? For pipeline parallelism, it partitions a model by layers, and it can optimize throughput and memory footprint, other than latency.
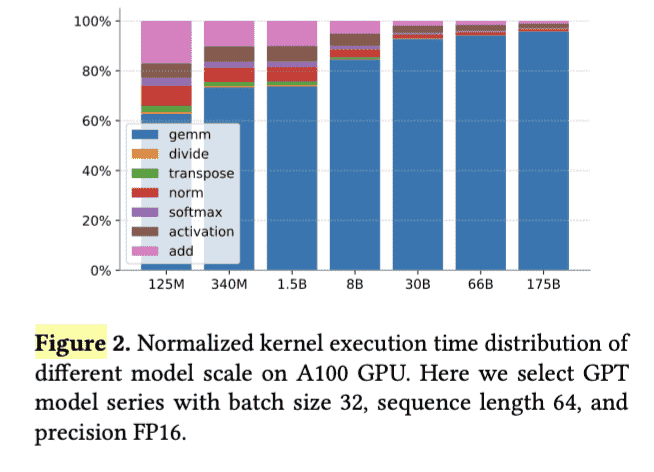
insights: 随着LLM参数量增加,矩阵计算时间占比是增加的: