[TOC]
ICML 23
一篇类似的:Bapipe:Exploration of Balanced Pipeline Parallelism for DNN Training
BPipe
只针对activation transfer:BPIPE employs an activation balancing method to transfer intermediate activations between GPUs during training, enabling all GPUs to utilize comparable amounts of memory.
Intro
Insights: Memory压力周期:增加-平稳-减少
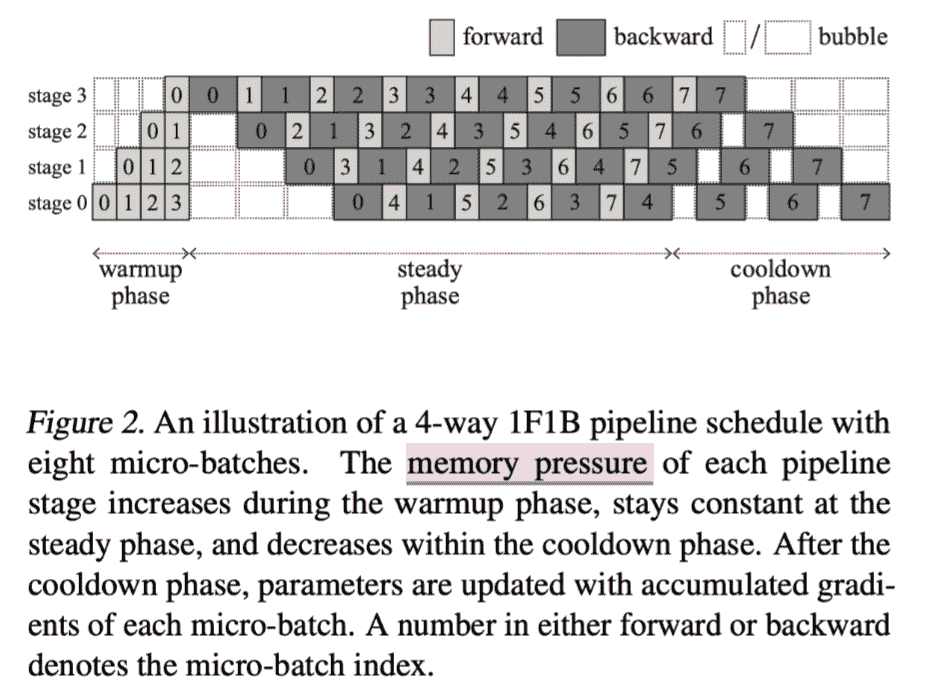
Fig2: the first stage has to store activations as many micro-batches as the pipeline parallelism degree during the warmup phase.
因为同一批数据 的activation 是在 backward 之后被释放的,所以即使steady阶段内存也是不平衡的。
但是把后边的stage分配更多weights是不能解决问题的,因为computation时间的不对称会使得latency变大:but it incurs inefficiency because the pipeline latency is minimized when each pipeline stage has the same computation time
有一个尝试牺牲内存结局问题的work:efficiently training largescale neural networks with bidirectional pipelines
Method
引起内存不平衡最重要的一点是【每一个stage需要储存的activation数量不一致】,这个数量是 $p-s$ , 其中p是pipeline的stage总数,s是当前stage编号。
solution:we pair each stage s with stage $p − s − 1$ to balance $μ(s)$ and $μ(p − s − 1)$
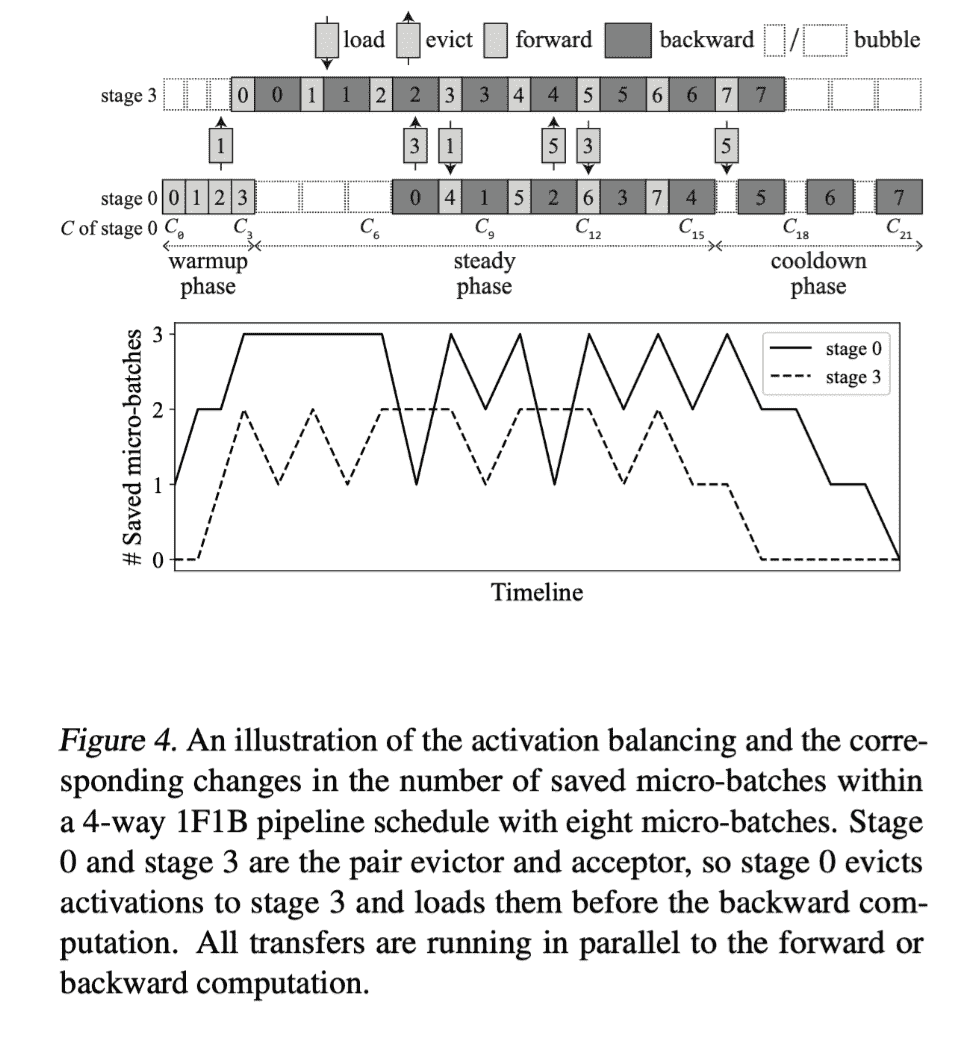
details:
- actvation 的 transfer 做了和computation 的 overlap
- BPIPE always evicts the latest micro-batch among the saved to minimize the number of transfers.
Experiments
Does BPIPE facilitate faster training of large language models? (§ 4.2)
Does BPIPE flatten the memory usage of each pipeline stage? (§ 4.3)
Does BPIPE efficiently evict and load activations without performance degradation? (§ 4.4)