[TOC]
Challenge:However, existing systems struggle because the key-value cache (KV cache) memory for each request is huge and grows and shrinks dynamically, When managed inefficiently, this memory can be significantly wasted by fragmentation and redundant duplication, limiting the batch size ==》 进一步导致latency和throughput受限。
vLLM特性:(1) near-zero waste in KV cache memory and (2) flexible sharing of KV cache within and across requests to further reduce memory usage.
没有说continuous batching,因为这是orca提出来的
result:即使在latency上也有2x-4x sota的效果,在throughput上估计10x
Intro
At the core of LLMs lies an autoregressive Transformer model [53]
activations – the ephemeral tensors created when evaluating the LLM
KVcache insights:
-
existing works need a contiguous memory to save it
-
its lifetime and length are not known a priori
Method
PagedAttention
PagedAttention 看 vLLM 即可
BeamSearch 解码
看 vLLM 即可
Scheduling and Preemption
When the request traffic surpasses the system’s capacity, vLLM must prioritize a subset of requests. In vLLM, we adopt the first-come-first-serve (FCFS) scheduling policy for all requests, ensuring fairness and preventing starvation. When vLLM needs to preempt requests, it ensures that the earliest arrived requests are served first and the latest requests are preempted first.
若发生抢占,需要回答两个问题:: (1) Which blocks should it evict? (2) How to recover evicted blocks if needed again?
第一个问题:启发式驱逐,并且遵循all-or-nothing eviction policy:要是抢占就直接把 beam search candidate一起驱逐
第二个问题的两种策略:
The performances of swapping and recomputation depend on the bandwidth between CPU RAM and GPU memory and the computation power of the GPU.
- Swapping
当耗尽GPU Mem时候,换到CPU DRAM上,并在下一次new request接受之前换入(一个简单的想法)
1)When vLLM exhausts free physical blocks for new tokens, it selects a set of sequences to evict and transfer their KV cache to the CPU.
2)Once it preempts a sequence and evicts its blocks, vLLM stops accepting new requests until all preempted sequences are completed.
有一个重要的问题是:DRAM 缓冲不会超过GPU内存总量:
Note that with this design, the number of blocks swapped to the CPU RAM never exceeds the number of total physical blocks in the GPU RAM, so the swap space on the CPU RAM is bounded by the GPU memory allocated for the KV cache.
- Recomputation
重新计算,把解码之后的token当作新prompt进行重新的KVcache生成
Distributed Execution
不是流水线,而是SPMD(Single Program Multiple Data) execution schedule
相同的处理手段:Megatron-LM style tensor model parallelism strategy on Transformers [47]
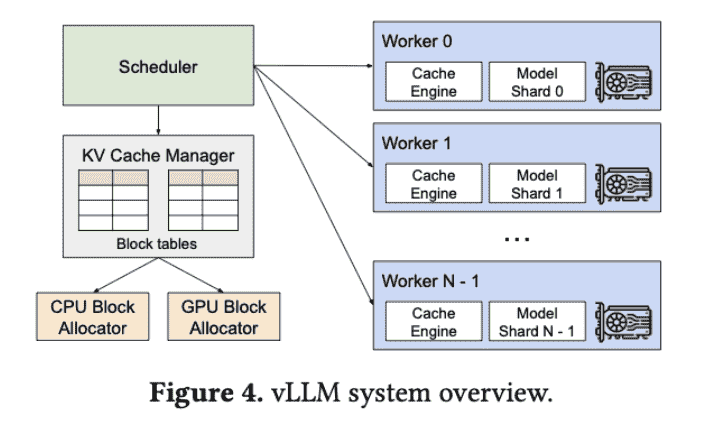
Worker只在计算开始&结束时和Scheduler交互一次
Experiments
Models and Configurations
We use OPT [62] models with 13B, 66B, and 175B parameters and LLaMA [52] with 13B parameters for our evaluation.
设备用的是Google Cloud Platform:
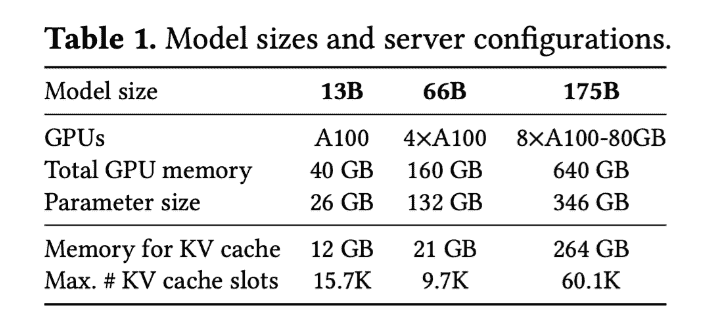
Workload
ShareGPT [51] and Alpaca [50] datasets(ShareGPT的平均prompts长度大)
模拟了访问时间戳:Since these datasets do not include timestamps, we generate request arrival times using Poisson distribution with different request rates.
还增加了一个chatbot workload
A chatbot [8, 19, 35] is one of the most important applications of LLMs.
Baseline
Triton(没用,但是这个也有continuous batching诶)
- FastTransformer
- Orca:自己实现的,配置了三个环境:
Orca (Oracle). We assume the system has the knowledge of the lengths of the outputs that will be actually generated for the requests. This shows the upper-bound performance of Orca, which is infeasible to achieve in practice. Orca (Pow2). We assume the system over-reserves the space for outputs by at most 2×. For example, if the true output length is 25, it reserves 32 positions for outputs. Orca (Max). We assume the system always reserves the space up to the maximum sequence length of the model, i.e., 2048 tokens.
Metrics
We focus on serving throughput
一个重要原因:A high-throughput serving system should retain low normalized latency against high request rates.
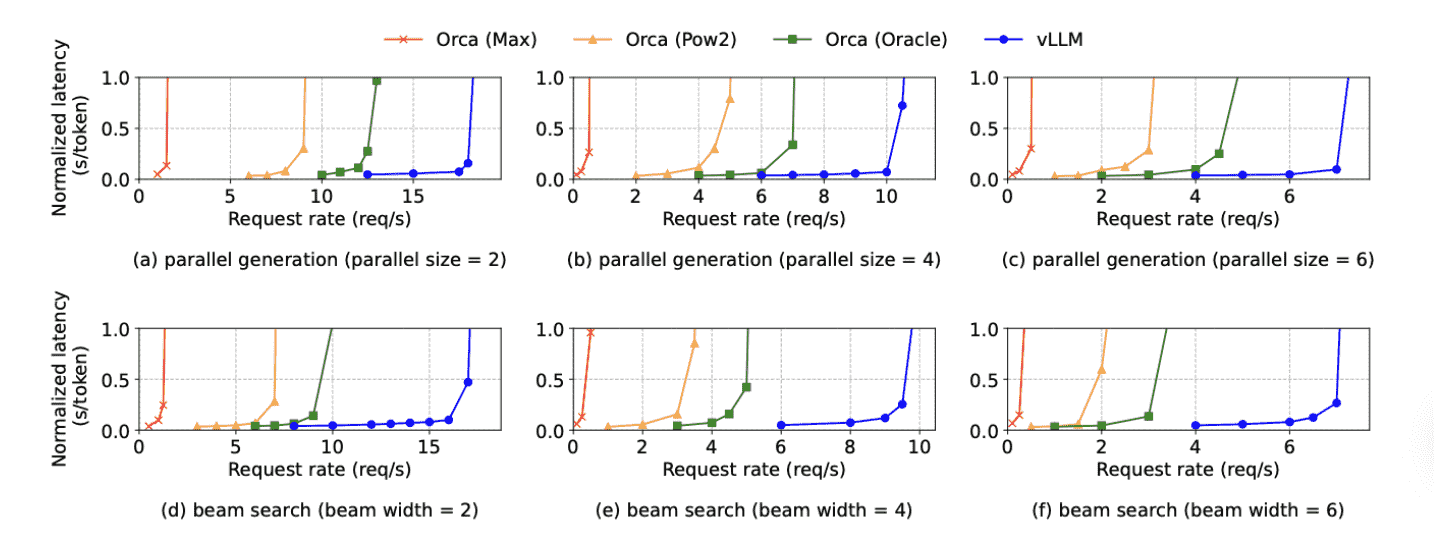
Result
实验衡量的是request rate和normalized latency之间的关系:
Ablation
这是一个可以考虑的点,如何根据配置选取recompute和swap: