[TOC]
Abs
challenge: prefill 和 decode 阶段的 compute density 不一样,具体来说,prefill在小batchsize时候就填满,但是decode阶段此时GPU利用率低。
challenge带来的问题:在pipeline parallelism中产生bubble,造成micro-batches不平衡
提出了:chunked-prefills:分chunck进行prefill,让不同microbatch均衡inference
decode requests 进行 piggyback(搭载),不会作为主要负载
由于这样做计算块比较小,因此可以实现均衡,少bubble
Intro
prefill and decode phases have different compute requirements
主要解决两个问题:bubble,microbatch imbalance
解决办法:统一request的compute requirements,本质上还是降粒度
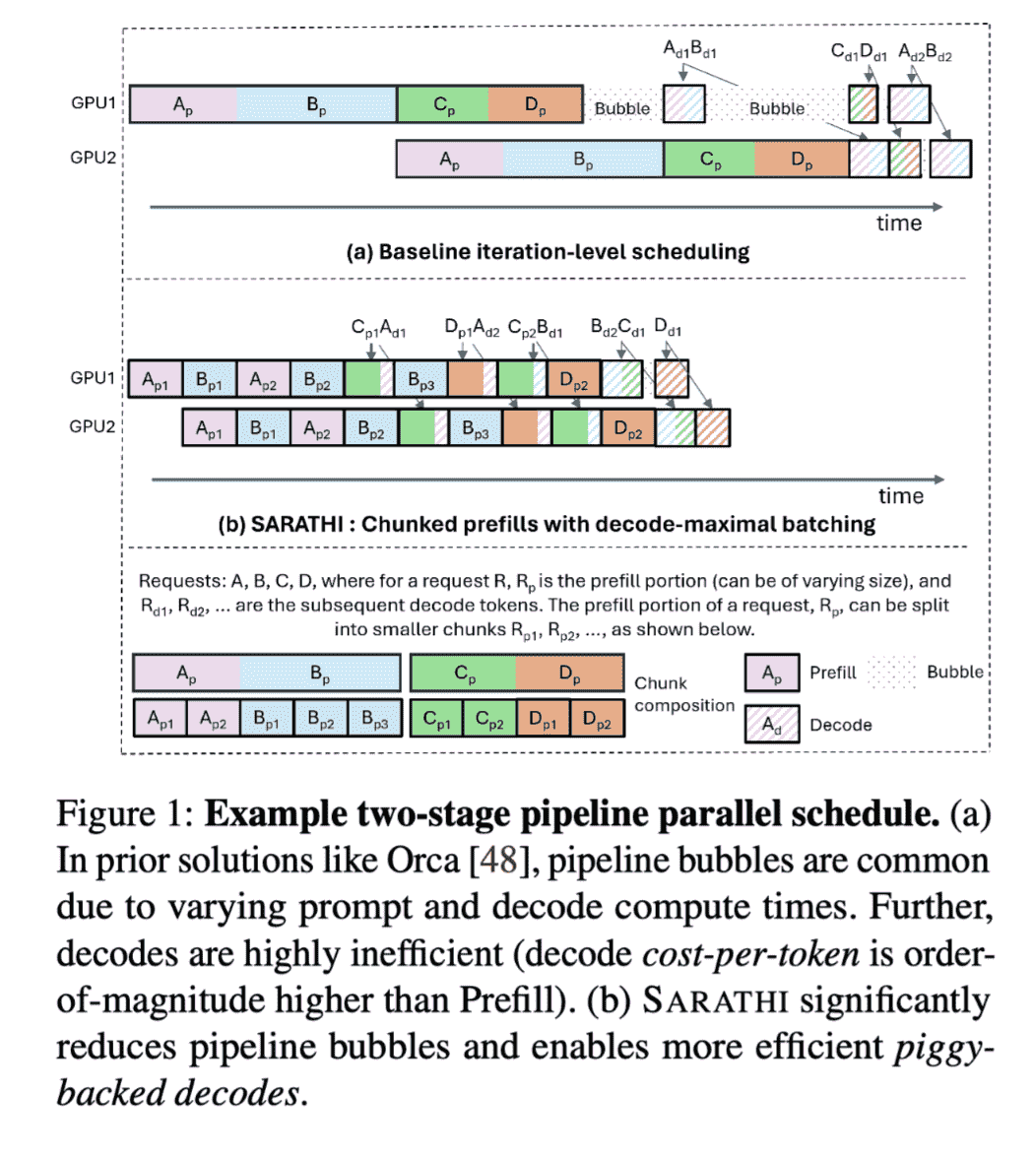
SARATHI
Chunked-prefills

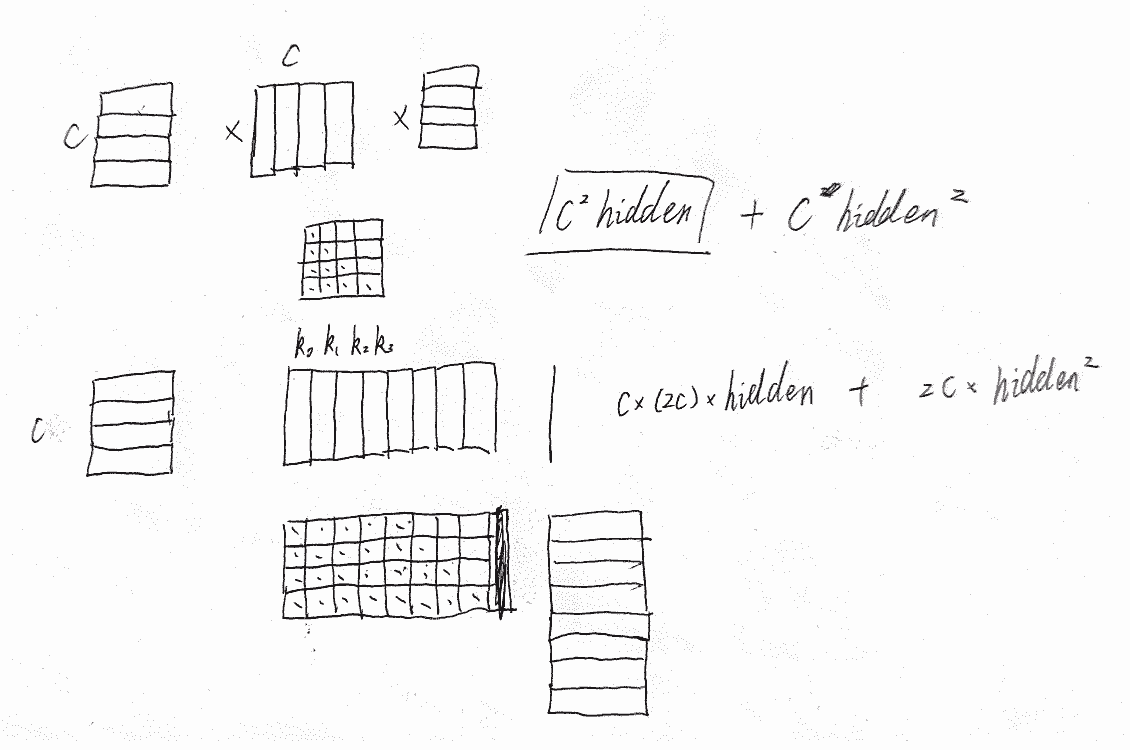
分析一下计算模式,发现是非平衡的,计算成本在第k个chunk是
\(kc^2\times hidden\_size + kc\times hidden\_size^2\)
Piggybacking decodes with prefills
计算一个最大decode batch,看最多可以搭载多少decodes
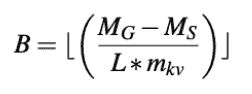
Identifying the ideal chunk size
定义了一个PD ratio来确定最佳块大小,但是这是扯淡的,因为要是能确定要decode多少token出来,all things 都没有了,但是以最大长度来算,显然又有浪费。
“P:D ratio” that is computed as the ratio of the number of prefill tokens to the number of decode tokens in a given batch
Exp
Question
throughput vs. end2end inference
impact of varying sequence lengths, batch sizes, and P:D ratios
throughput vs. orca-like
overheads of our system
Disc
- 多角度优化 latency, queuing delays, fairness(SARATHI只从throughput角度进行优化)
- how to pick an optimal chunk size as it depends on several factors
- how to process varying number of prefill and decode tokens (SARATHI假设定长)
- supporting very long sequences