[TOC]
Abs
问题:Existing LLM serving systems use run-to-completion(即使是Orca也是FCFS的服务1) processing for inference jobs, which suffers from head-of-line blocking and long JCT.
JCT是从提交作业(或任务、请求等)到作业完成并得到结果的总时间。这个时间可能包括了等待时间、执行时间、通信时间、IO时间等多个组成部分。通过优化系统设计和算法,可以降低JCT,从而提高系统的吞吐量和用户满意度。
解决思路:
1)preemptive scheduling,a novel skip-join Multi-Level Feedback Queue scheduler
2)an efficient GPU memory management mechanism, offloads and uploads intermediate states between GPU memory and host memory
Intro
challenge:
1)未知的输出长度
2)GPU内存开销
做的事情:
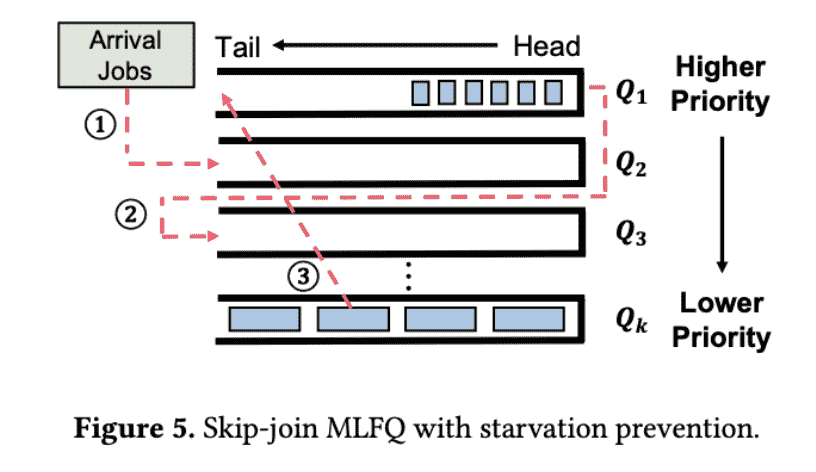
1)利用一个Multi-Level Feedback Queue (MLFQ)来调度推理任务:
假设:first token latency > decode latency, 即长prompt短输出
因此会首先衡量prefill的时间,根据这个时间分配队列层级(就是所谓的skipped)
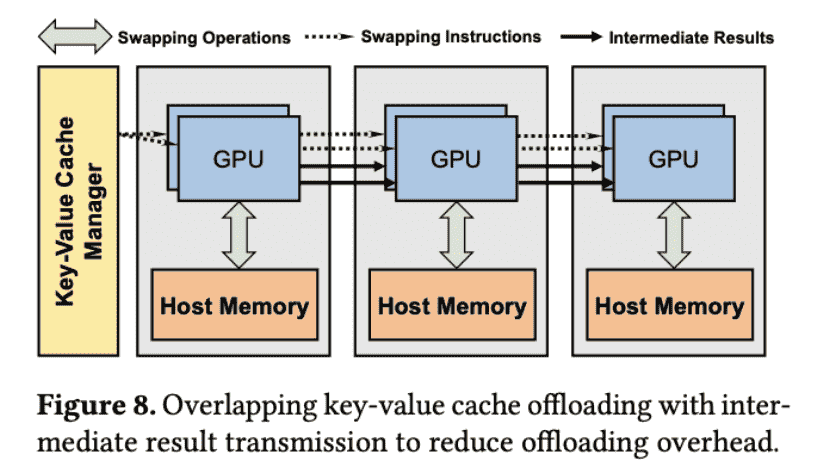
2)由于MLFQ启动的任务可能过多,因此要offload KV-cache,因此利用MLFQ的优先级动态offload;此外,还设计了GPU之间的分布式offload
FastServe
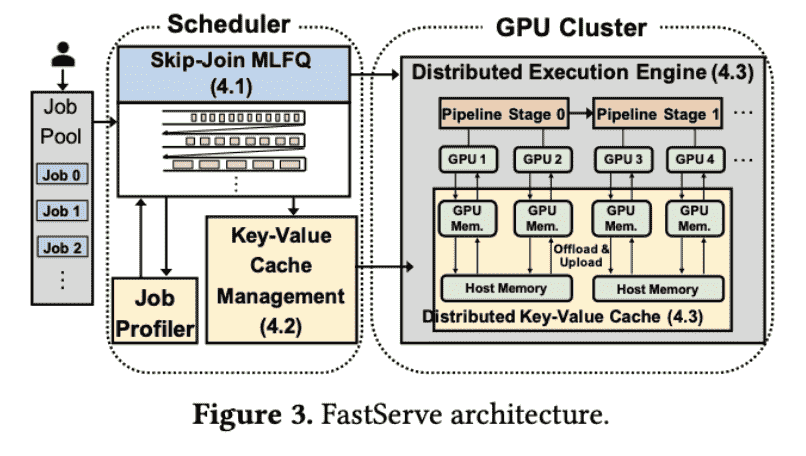
Skip-Join MLFQ Scheduler
Proactive Key-Value Cache Management
MLFQ的KV-cache占用比传统系统高很多
Exp
Metrics
average and tail job completion time (JCT)
Baselines
- FasterTransformer
- Orca
实验设计
- overall表现:就是在不同的workload和baseline的对比
- 消融实验,说明为什么系统的2部分分别起作用
- scaling:流水线分布式实验
Reference
-
[Paper Reading] 针对 LLM Inference 的调度: Fast Distributed Inference Serving for Large Language Models. https://zhuanlan.zhihu.com/p/648759542 ↩