[TOC]
Abs
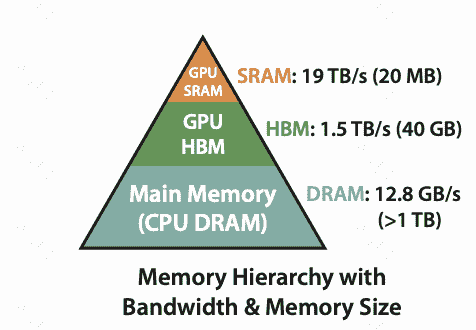
目标:reduce the number of memory reads/writes between GPU high bandwidth memory (HBM) and GPU on-chip SRAM
Intro
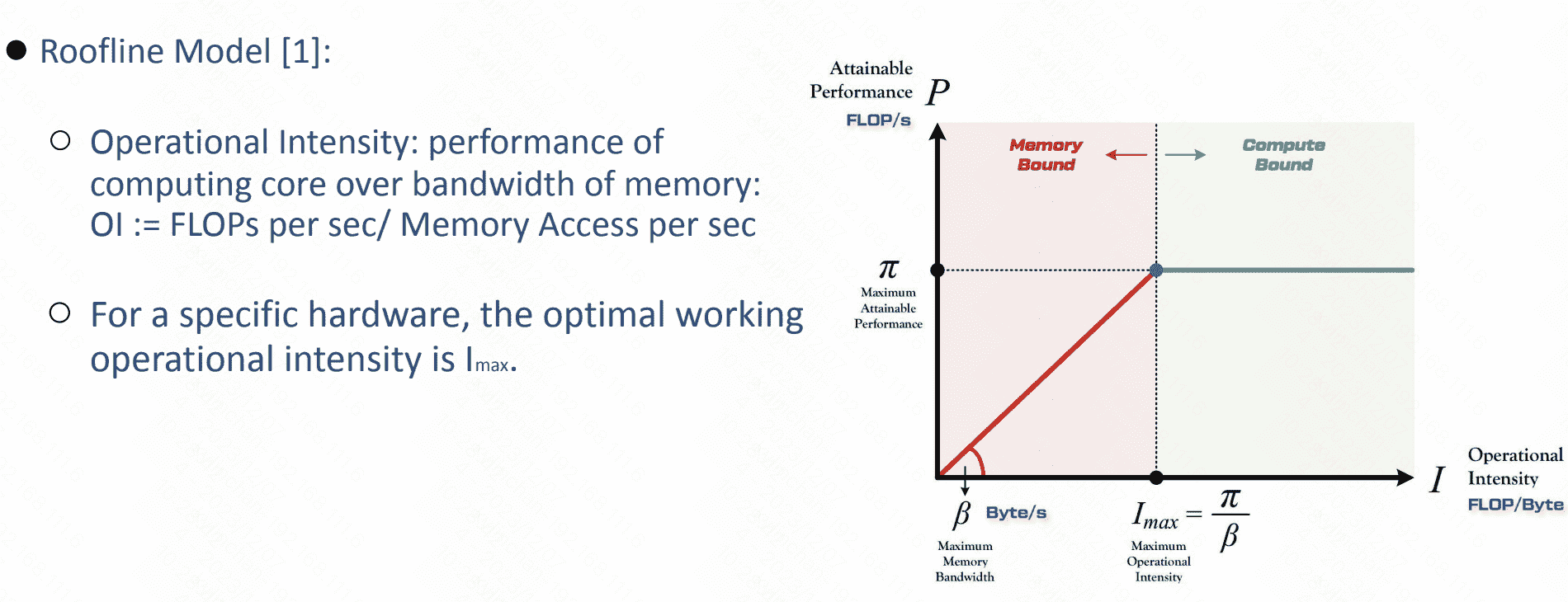
为什么IO-aware在transformer里是重要的?
对pytorch实现版的attention进行profiling,发现利用GPU并行性最好的matmul占比其实不高
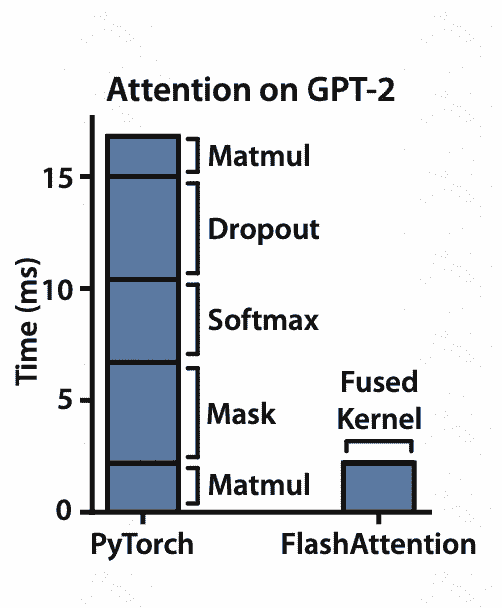
而其他操作却是IO-bound的状态:
Method
主要方法,相比于整个attention加载,逐步加载,逐步存入:

但是有一个比较关键的问题是softmax的分块算法(因为其他op的分解已经很成熟)
flash attention 分块softmax算法证明1
- 为解决HBM重复读写问题,提出了tiling算法(右图)。这个算法中最重要的还是解决softmax的forword、backward分块。
- 为解决backword过程需要O(n^2)储存的问题(也一同解决HBM重复读写问题),提出了recomputation算法。
Reference
-
从 FlashAttention 到 PagedAttention, 如何进一步优化 Attention 性能 https://zhuanlan.zhihu.com/p/638468472 ↩