[TOC]
Why KV cache?
refer to https://kylinchen.cn/2023/08/21/KVCache/
需要注意的是,KV cache本身也是一种优化策略,用缓存Key Value(空间)避免重复计算(时间),但是现在发现这个KV cache实在太大了,尤其是在Serving System了里面,轻松达到模型参数占用4倍。
所以优化一般分为两个方向:
- 储存优化(主要)
- 计算优化
Attention 机制修改
减少Head
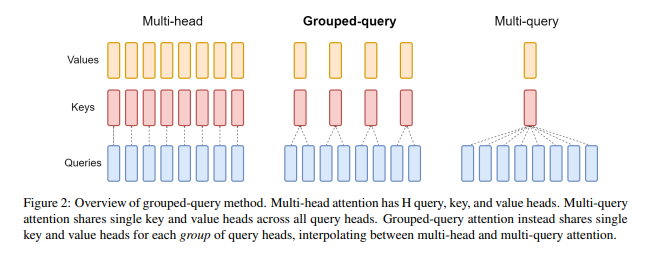
MQA (Multi Query Attention,多查询注意力) 是多头注意力的一种变体。**MQA不同的注意力头共享一个K和V的集合,每个头只单独保留了一份查询参数 **。支持对已经训练好的模型进行微调来添加MQA。
保留了一定数量的KV-cache,使得其在MHA和MQA之间平衡。
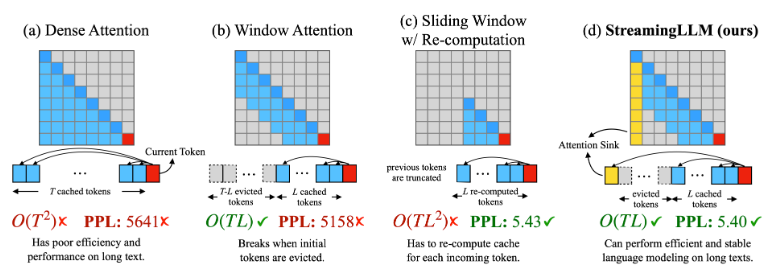
Window Attention
LongFormer
arxiv 23.09
refer to https://kylinchen.cn/2023/10/29/StreamingLM/
注意力集中在头尾,所以咱 tokens 保留头尾的就好
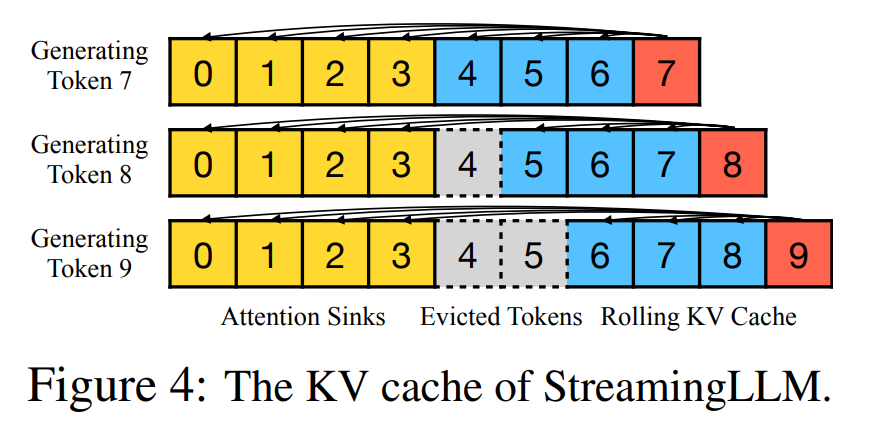
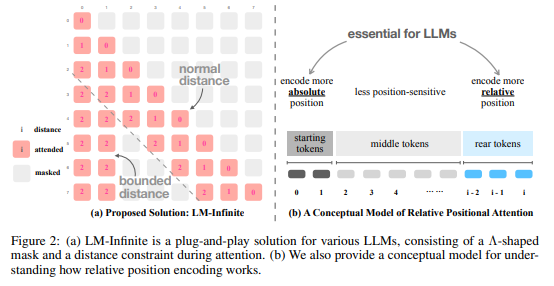
arxiv 23.10
同 StreamingLM,本质上就是保留头尾,给出Λ-shaped attention mask
Sparse Attention
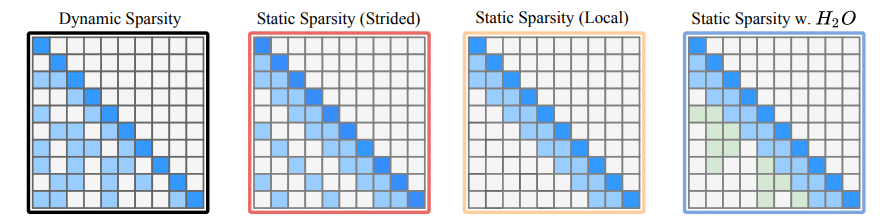
arxiv 23.06
通过动态的评价方式来判断需要保留和废弃的KV值
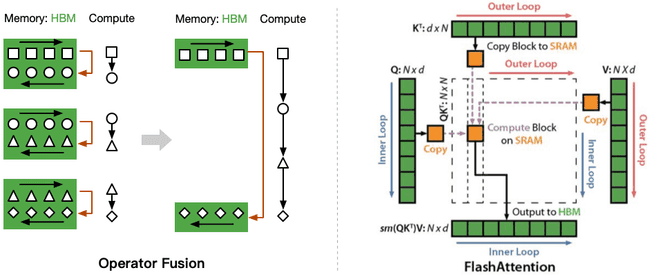
计算-储存优化
SOSP 23
通过 tiling 和 recomputation 等策略减少 HBM 读写,达到:1)加速,2)节约内存