[TOC]
https://arxiv.org/pdf/2309.17453.pdf
Abs
两个gap:
- during the decoding stage, caching previous tokens’ Key and Value states (KV) consumes extensive memory
- popular LLMs cannot generalize to longer texts than the training sequence length (实际上受制于positional decoding罢了)
一个insight:Lost in the middle(attention一般只注意头尾的tokens):attention sink, that keeping the KV of initial tokens will largely recover the performance of window attention
在以下文献里面也讨论过这个现象: Lost in the Middle: How Language Models Use Long Contexts: https://browse.arxiv.org/pdf/2307.03172.pdf
Attention Is Off By One:https://www.evanmiller.org/attention-is-off-by-one.html?continueFlag=5d0e431f4edf1d8cccea47871e82fbc4
LM-Infinit:https://arxiv.org/pdf/2308.16137.pdf (Λ-shaped attention mask,其实就是sink,研究挂arxiv上晚三四天)
Intro
现有的几种 Attention (KV cache) 方法:
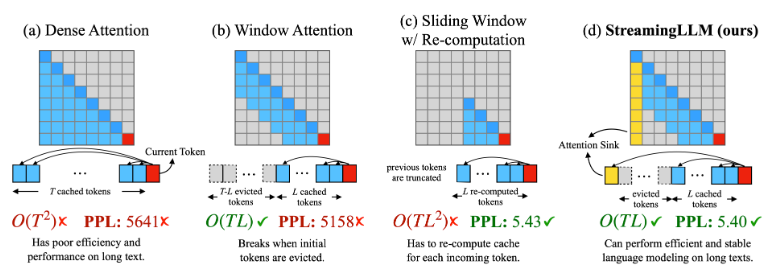
Meth
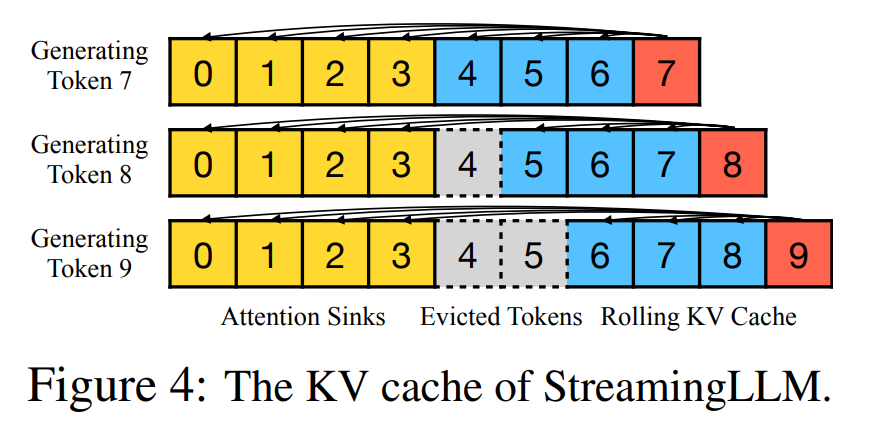
干了啥?将滑窗 L 分为固定前缀加上滑动后缀