[TOC]
Abs
Attention的问题:large memory requirements and computational complexity => This limitation is due to inherently limited data reuse opportunities and quadratic growth in memory footprints
我们的解决方案:a tailored dataflow optimization => transforming the memory footprint quadratic growth to merely a linear one
Our method both mitigates the off- chip bandwidth bottleneck as well as reduces the on-chip memory requirement.
所以解决的问题(off-chip data transfer)、解决的方式(tiling & scheduling)和flash attention是一致的。
*Roofline Model[^3]
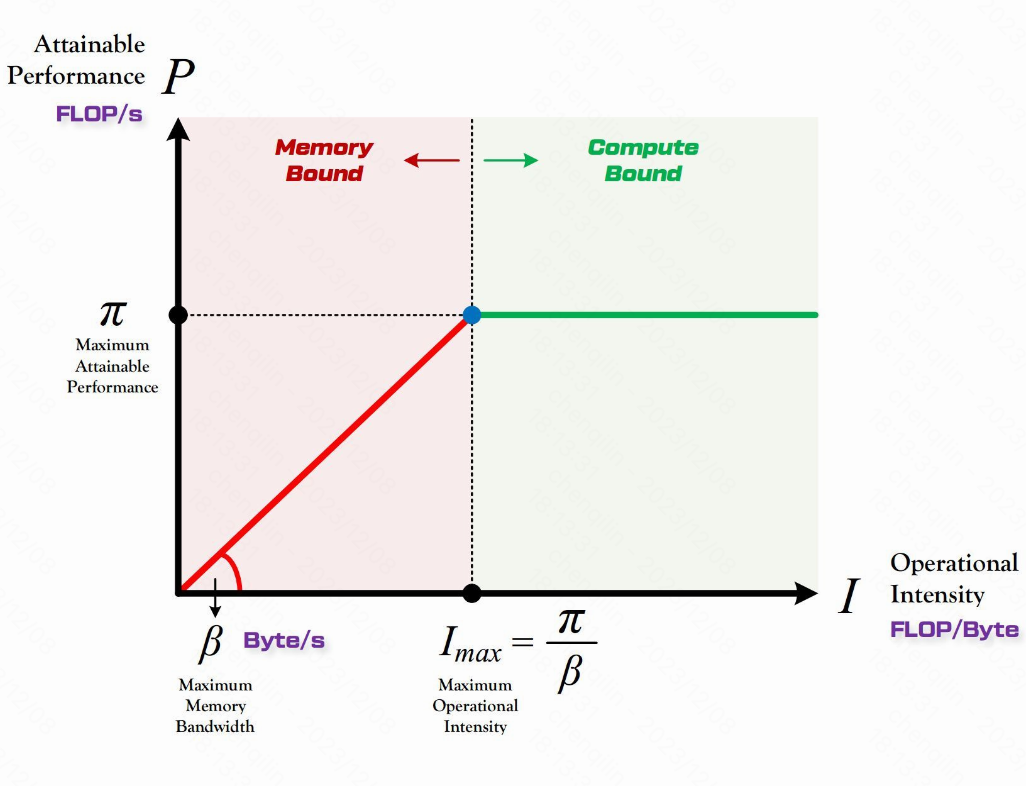
- Operational Intensity: performance of computing core over bandwidth of memory: OI := FLOPs per sec/ Memory Access per sec
- For a specific hardware, the optimal working operational intensity is $I_{max}$.
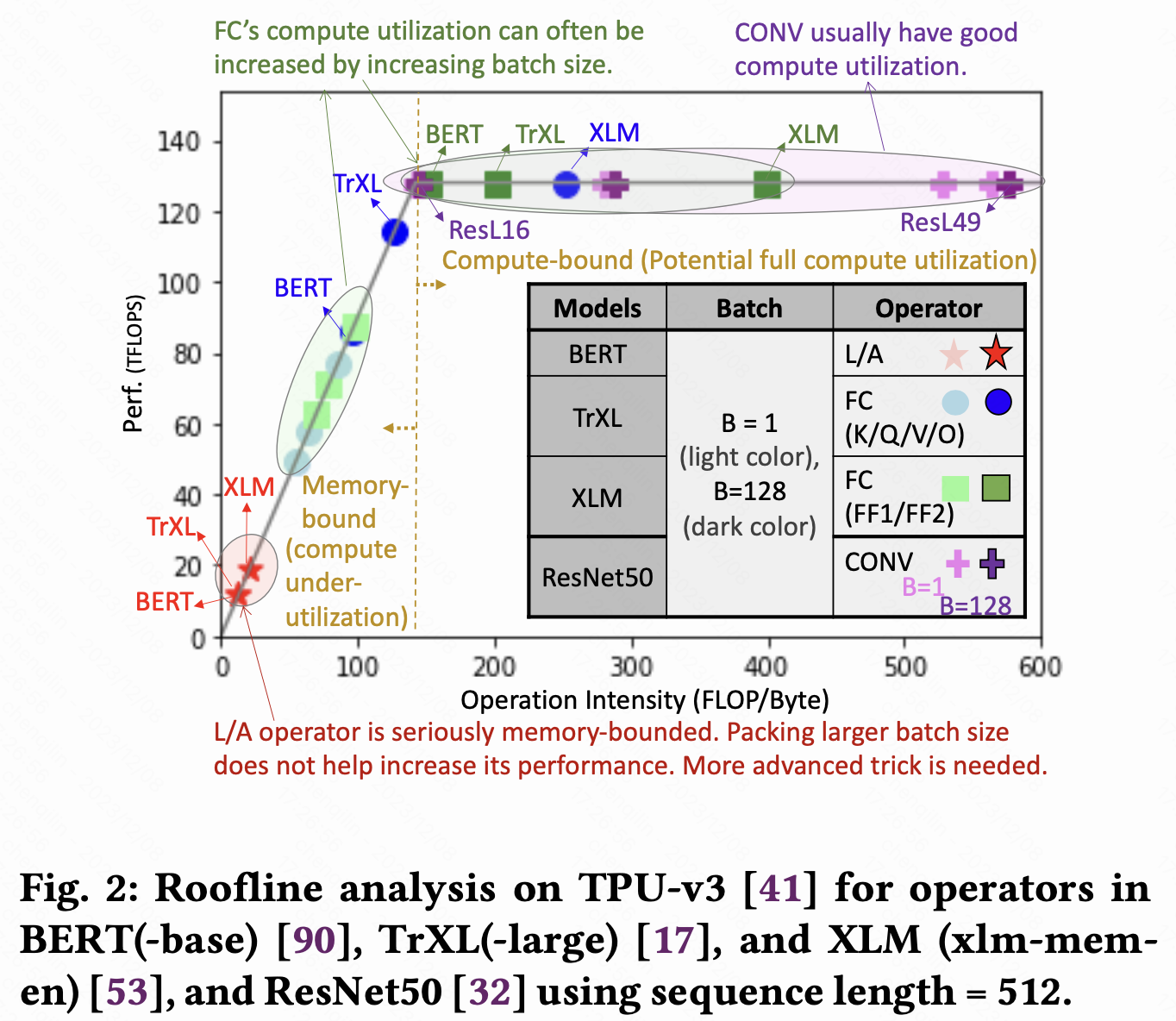
DSQ[^4] ran a similar analysis to Ivanov et al. [1]: OPT-1.3B Model:
- 47.93% latency: Attention layers. Memory-bound. (the matrix multiplications only takes around 66% of the latency in a single attention module.)
- 32.20% latency: FC layer. Compute-bound.
- 19.87% latency: Activation & Norm layer. Memory-bound.
Intro & bg
相比于Flash Attention的故事一直在紧抓SRAM-HBM访存次数问题,Flat Attention关注operational intensity(当然其实两者在本质上也是一致的)
但是有两个问题是必须注意的,这个也是在flashAttention中在motivation中没有说清楚的:
- flash和flat的优化对象是attention block,这样的话performance bottleneck反而是self-attention中的两个matmuls(computing intensity低)
- flash尤其flat甚至没有考虑自回归,分析intensity用的是prefill阶段的
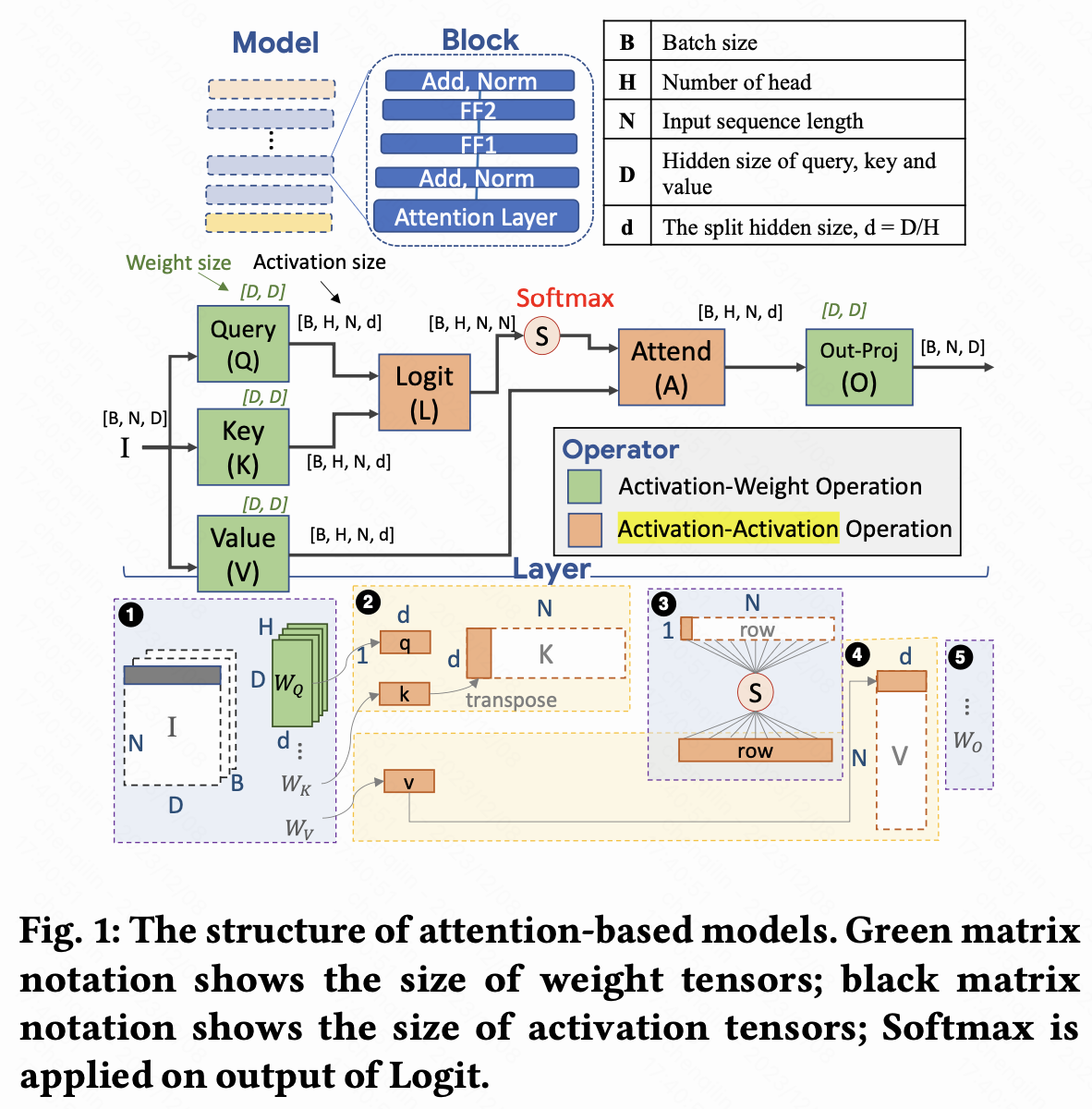
Flat把Attention中的op分为两类,一类是Activation-Weight operators (Q/K/V/O),一类是Activation-Activation operators (L/A),然后就会发现 L/A 限制了整体的operational intensity,即使增大batch size也没有用。
Method1
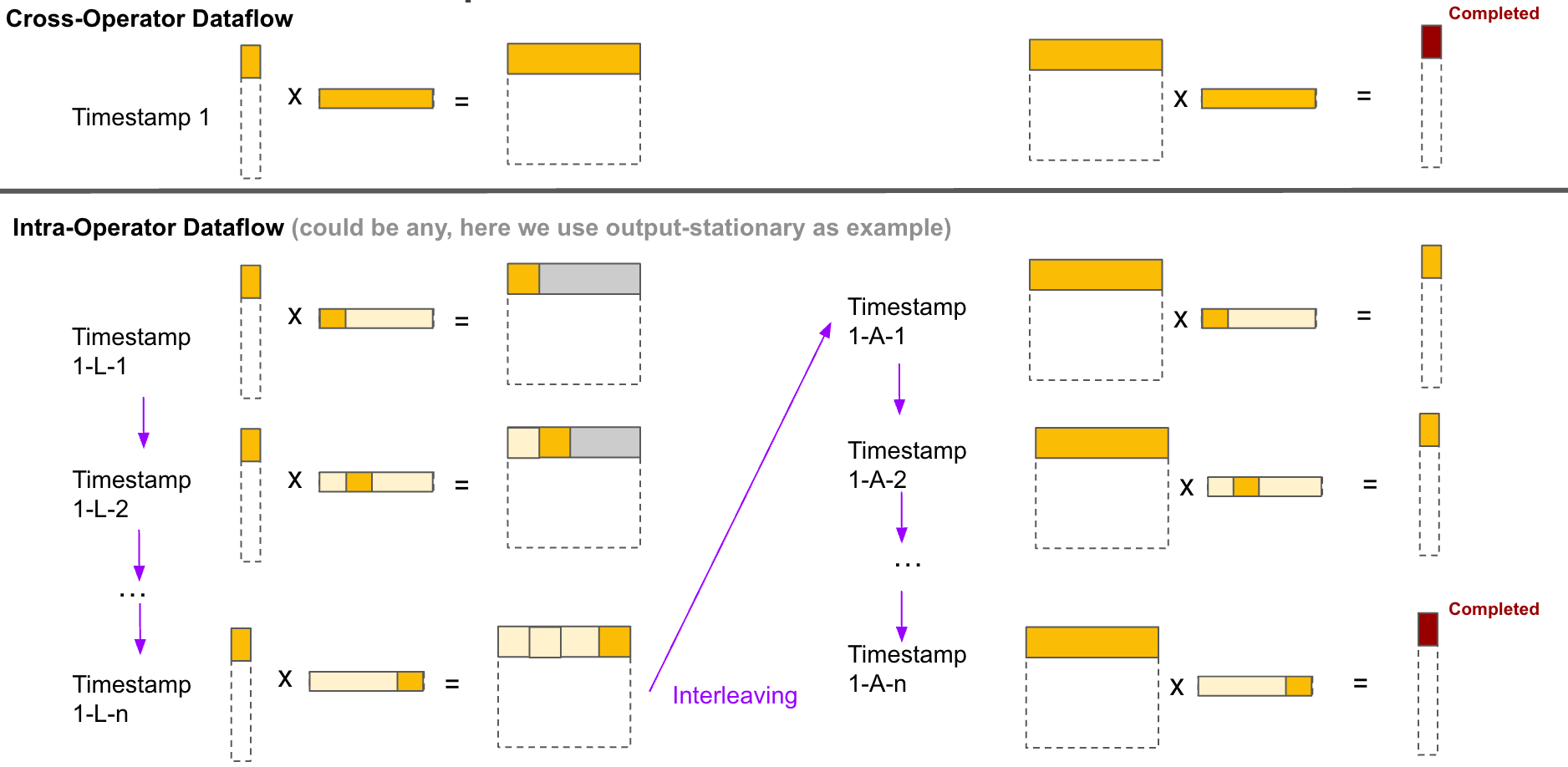
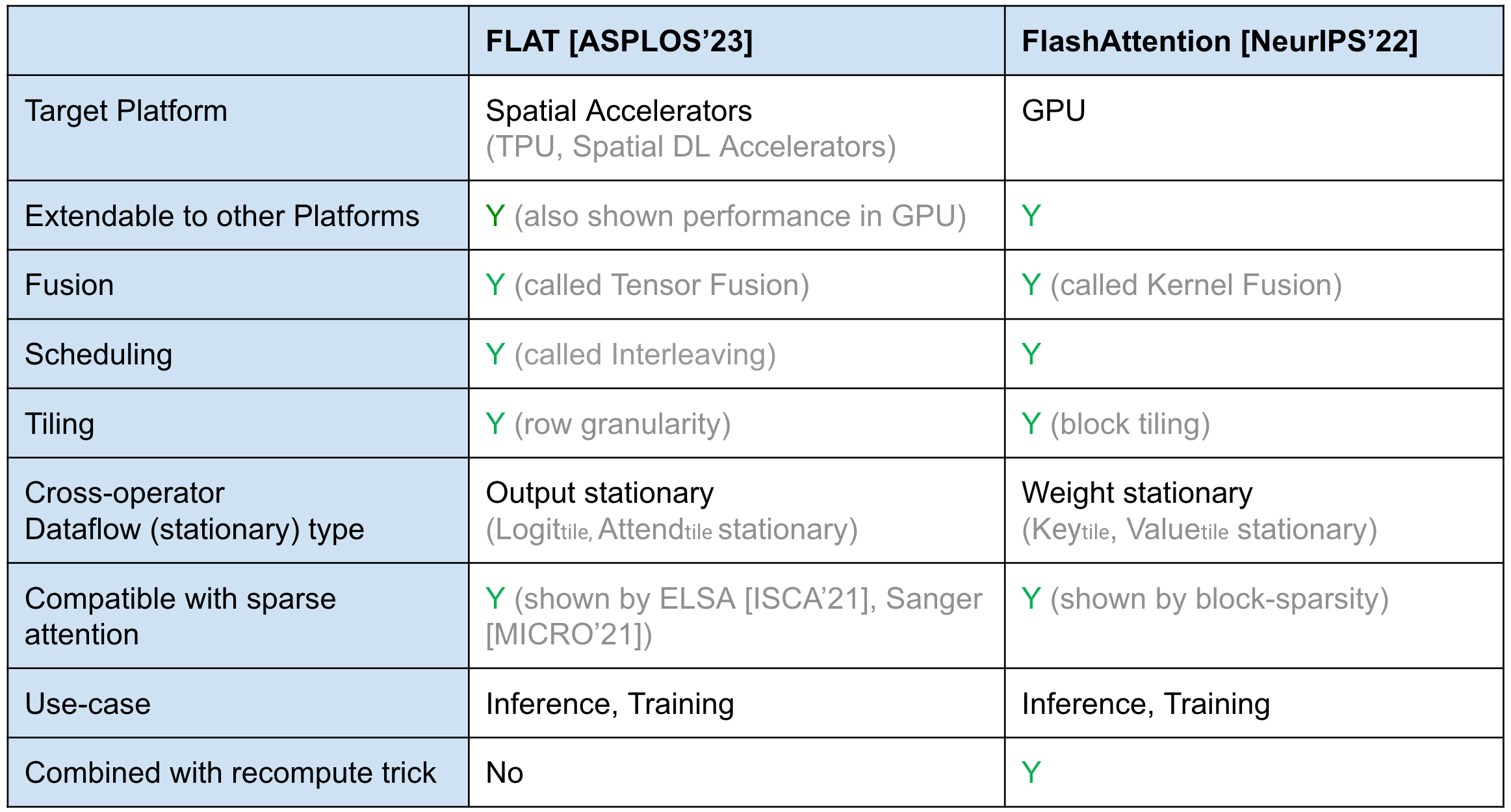
Tiling Strategy Comparisons
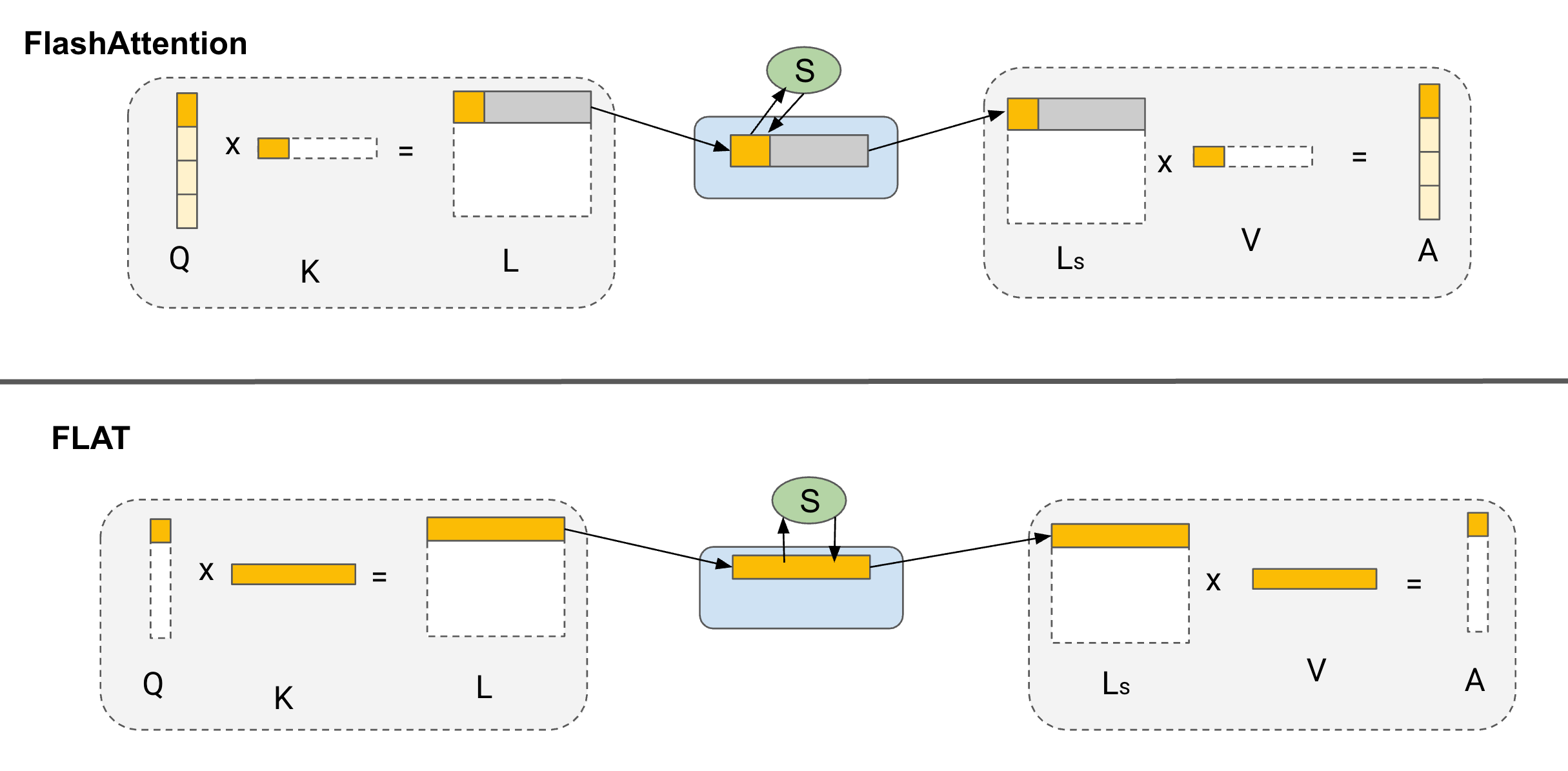
The tiling strategy difference between FLAT-Attention and FlashAttention. FlashAttention uses block tiling and weight stationary. FLAT-Attention uses row tiling (row-granularity) and output stationary.
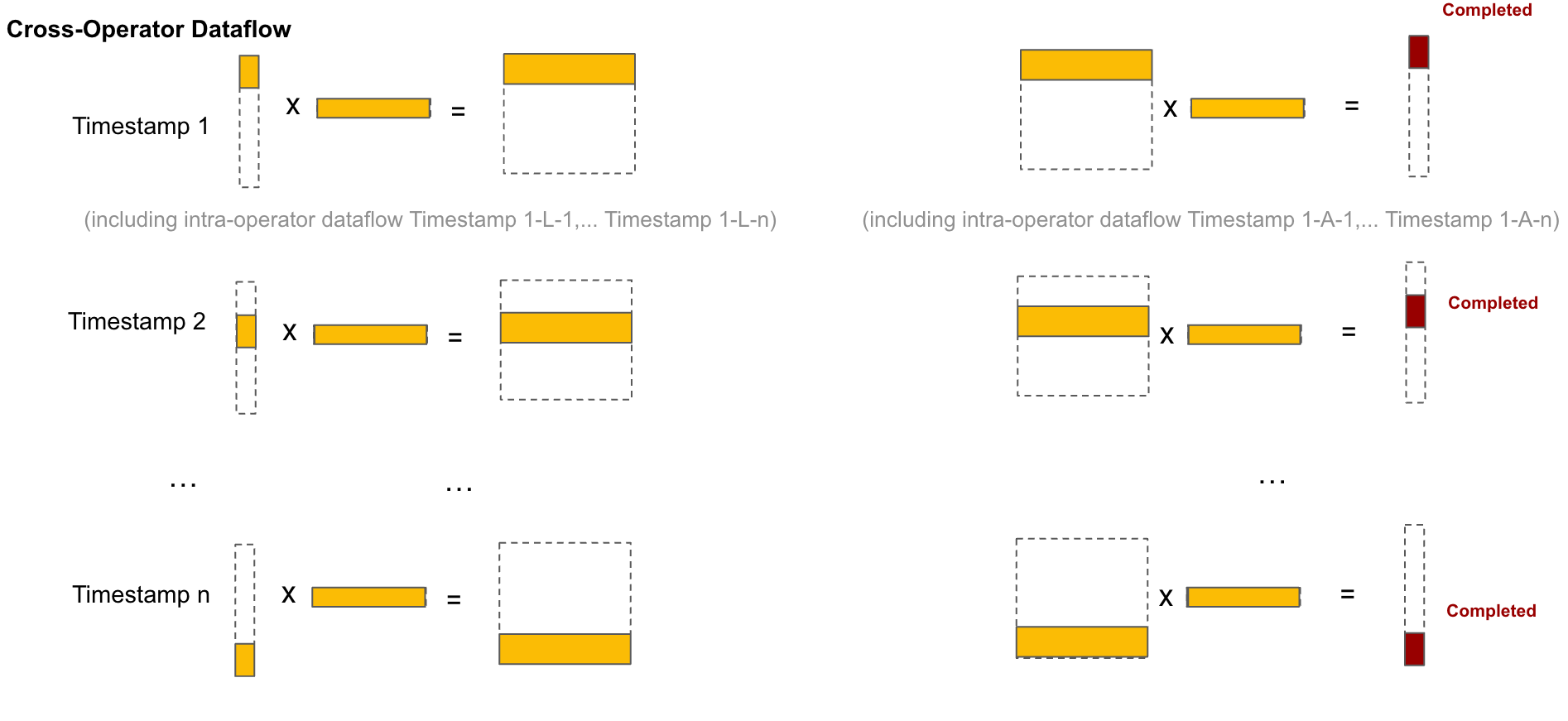
Scheduling Strategy (Dataflow) Comparisons
Flash Attention
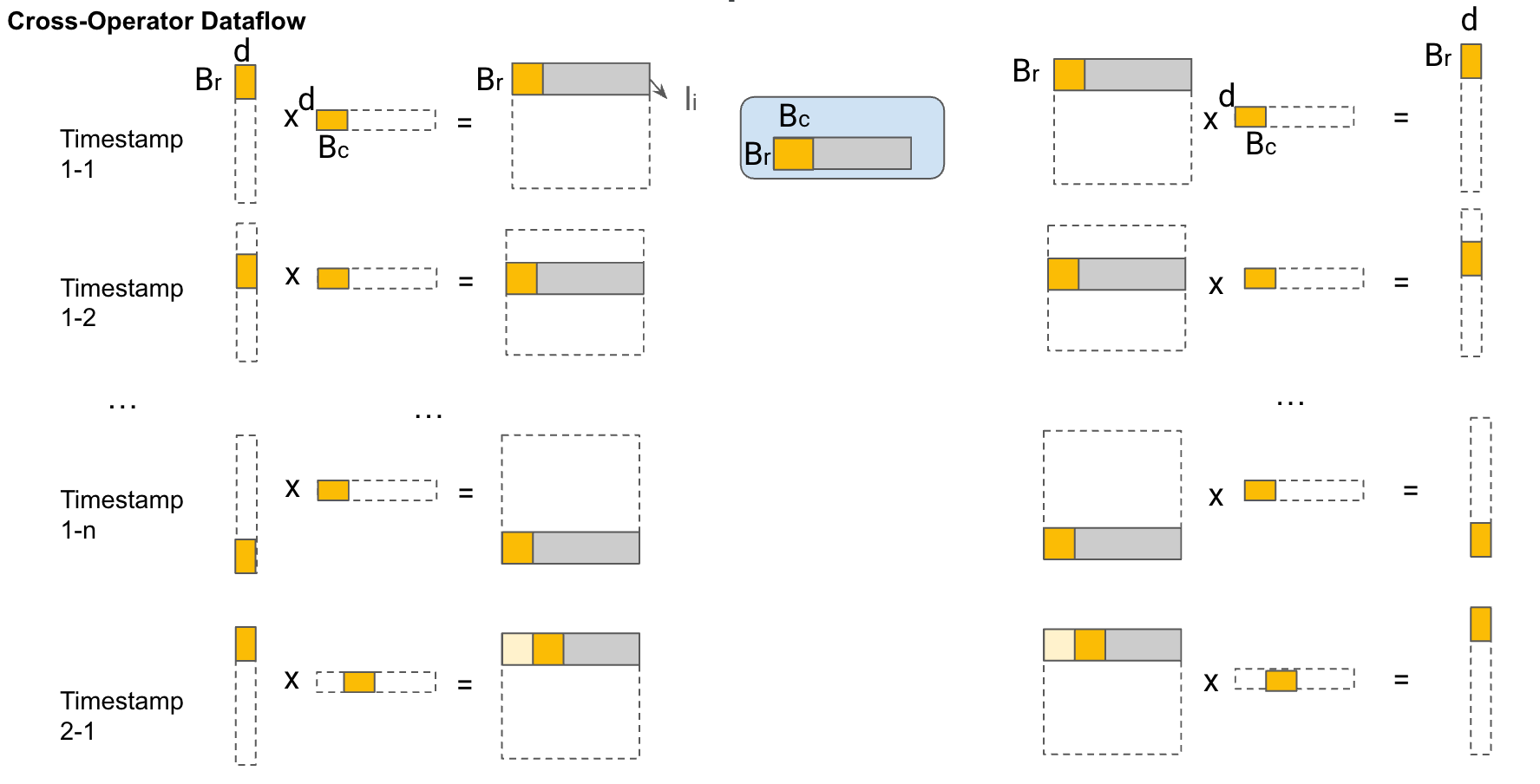
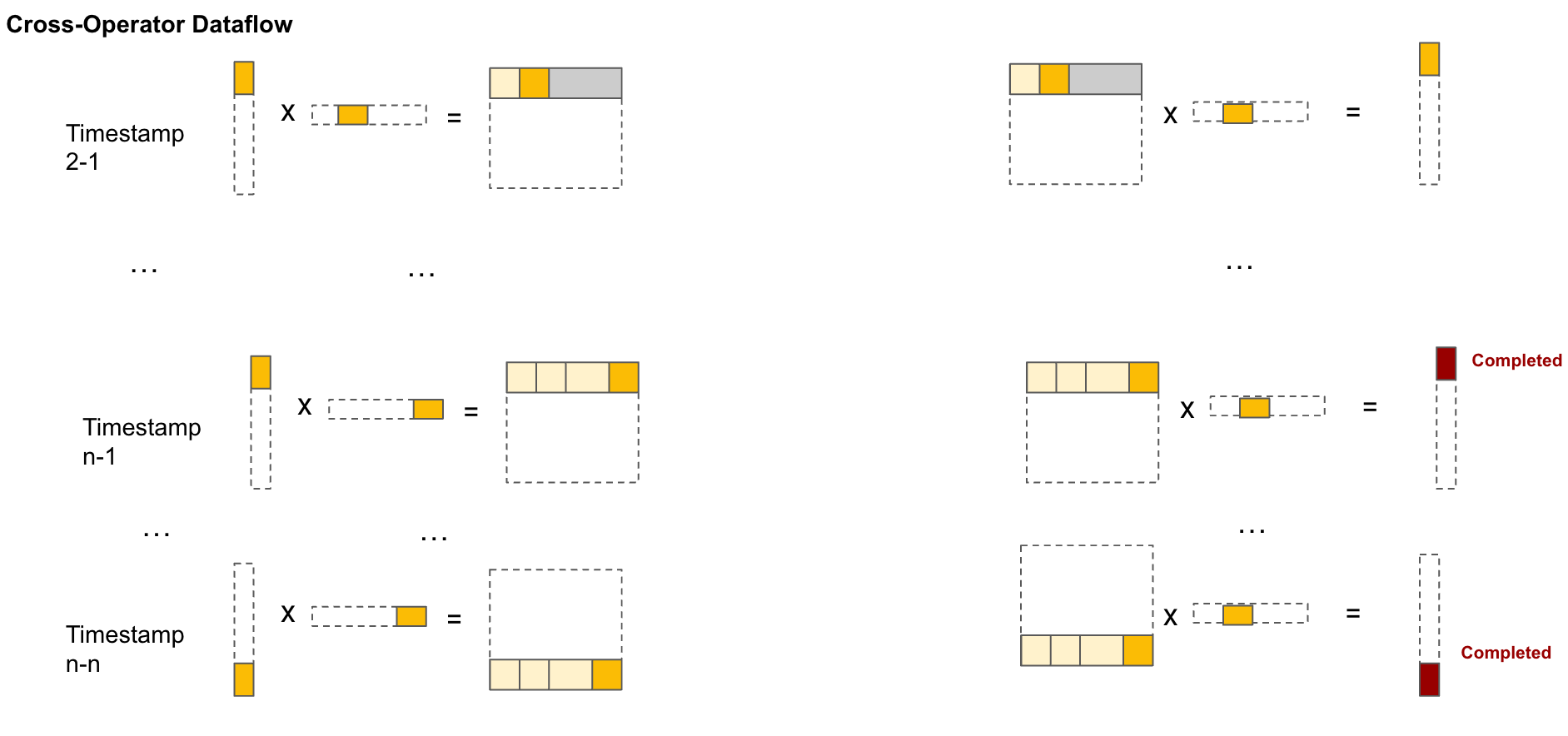
FLAT attention
Qualtively Comparisons1(FLAT vs. Flash)
Reference
[^ 2]: Kao, Sheng-Chun, et al. “FLAT: An Optimized Dataflow for Mitigating Attention Bottlenecks.” Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 2023.
[^ 3]: Williams, Samuel, Andrew Waterman, and David Patterson. “Roofline: an insightful visual performance model for multicore architectures.” Communications of the ACM 52.4 (2009): 65-76. [^ 4]: Yang, Guo, et al. “Dynamic Stashing Quantization for Efficient Transformer Training.” arXiv preprint arXiv:2303.05295 (2023).