[TOC]
Abs
general image tokenizer
Intro
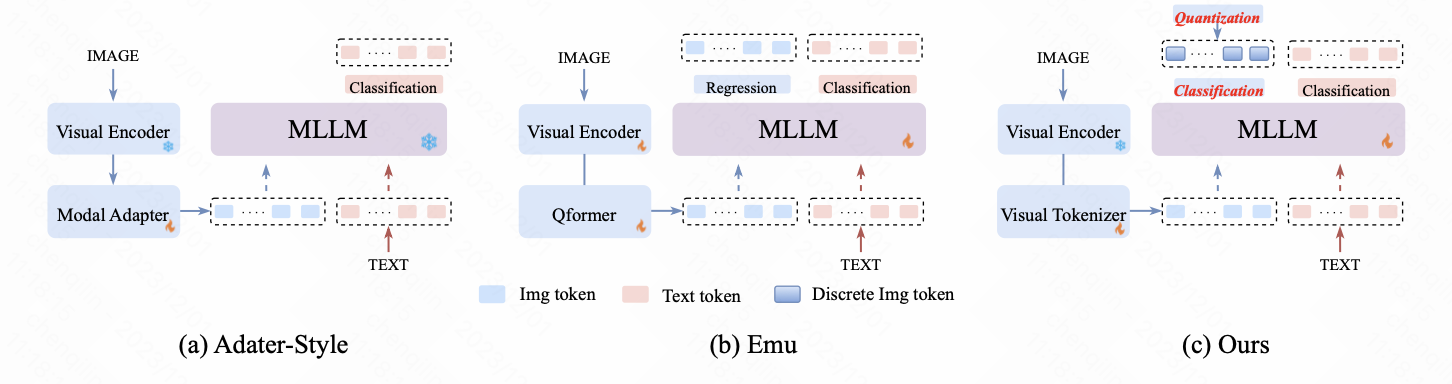
MLLM三种方式:
adapter architecture、Emu、ours(unified tokenizer)
challenges:
- Adater-style:
- is centered on predicting textual descriptions dependent on visual content, where the visual parts are merely regarded as prompts without any supervision. (没有有效利用多模态inputs)
- most of these methods completely delegate the responsibility of vision-language alignment to the newly added adapter with limited trainable parameters, which fails to leverage the remarkable reasoning capabilities of LLM to learn the interaction across different modalities.(没有有效利用LLM)
- Emu:
- 虽然会在pre-train阶段回归next-visual embedding,但是the inconsistent optimization objectives for image and text are not conducive to unified multi-modal modeling. (就是说两部分输出是分开处理的)
目标是在于实现一个tokenizer,这个tokenizer需要遵循两个原则:
- discrete visual token,但是一般视觉patch过vit之后的是连续的
- dynamic token allocation:一个是语义复杂度不一致;另一个是图像预测不能用self- supervising范式的next token prediction
Method
DYNAMIC VISUAL TOKENIZER
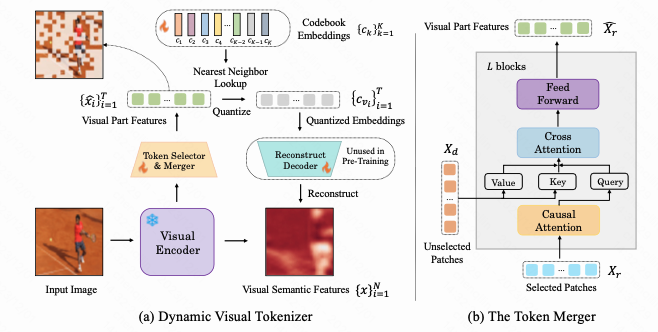
两个部分如图,先决定selected patches,然后再过L个Marger,目标在于动态选择哪些patches的表示有意义
Modeling
正常的casual modeling
有一个细节:To empower LaVIT with the capability to generate both text and images, we employ two different concatenation forms, i.e., [image, text] and [text; image]. When the image is used as a condition (on the left) to generate text, we use the continuous visual features Xˆr from the token merger instead of quantized visual embeddings as the input to LLMs.
Pretrain
Tokenizer Training:1)encoder is kept frozen and only the parameters of the selector, merger, and codebook are updated. 2)初始化unet,然后微调一下。
Unifoed Vision-Language Pre-training: 微调LLM。