[TOC]
Harnessing the Power of LLMs in Practice- A Survey on ChatGPT and Beyond
Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth
What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
主流三种架构
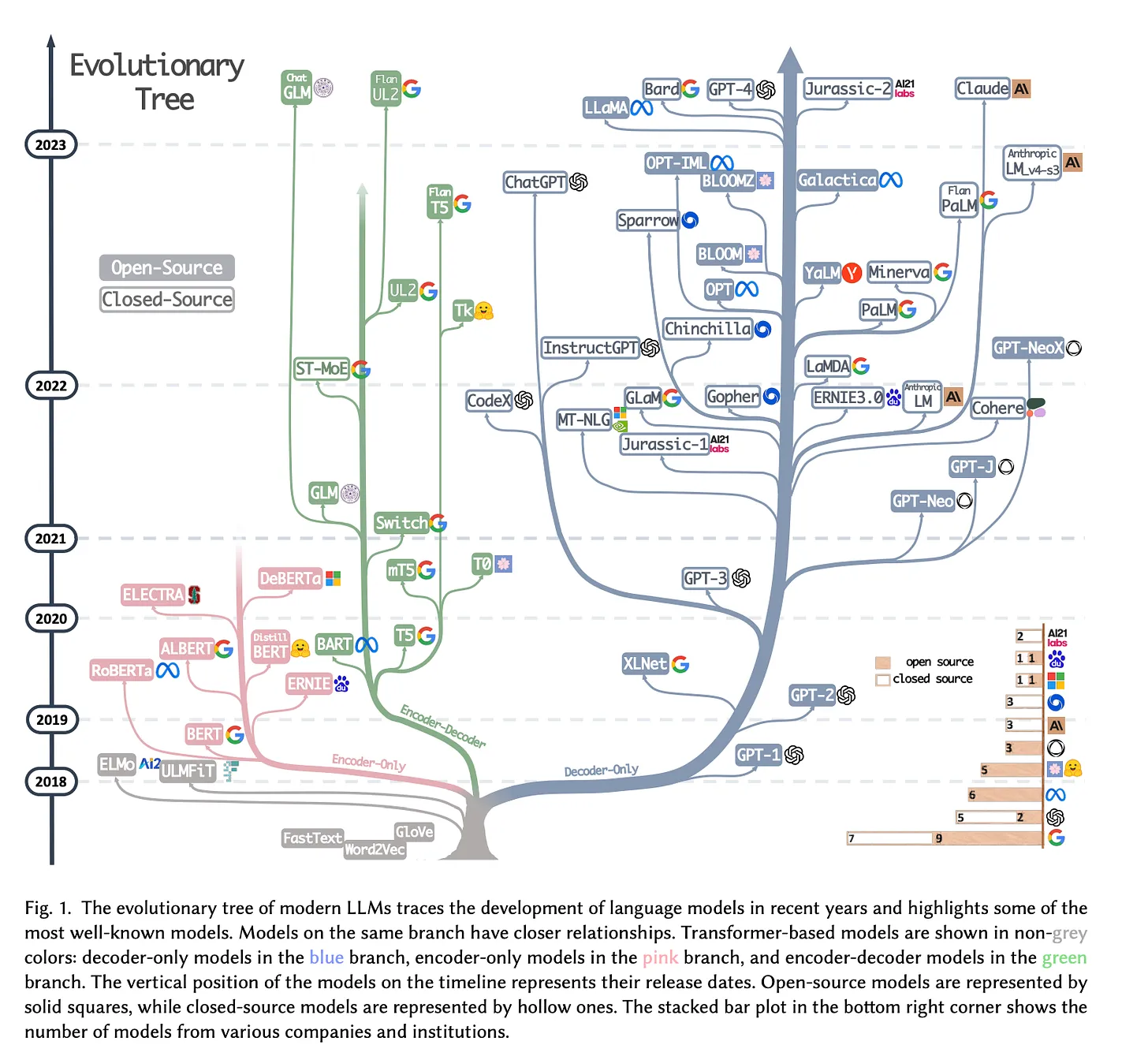
-
encoder-decoder
-
encoder-only
-
decoder-only (casual)
-
decoder-only (non-casual)

至于encoder-only的mask呢就是没有mask
为什么现在主流是用 decoder-only 架构?
主要是GPT是老大,让大家误以为LLM只有decoder-only的结构。
先说性能对比结论:decoder-only的zero-shot能力最好,但是 models with non-causal visibil- ity on their input trained with a masked language modeling objective followed by multitask finetuning perform the best among our experiments. 但是zero-shot能力对于LLM是重要的,所以一般认为decoder-only的模型要更好。
至于为什么加入encoder不行?(明明对于prompt引入双向注意力是自然的)
refer了 https://kexue.fm/archives/9529 中暂未验证的观点:引入的encoder因为mask引入低秩问题,导致表达能力不强。这与引入softmax一样,其实softmax的非线性缓解了低秩问题
并且认为google t5文章中的对比实验,encoder-decoder效果好主要是因为benchmark crime(参数量翻倍了)