[TOC]
Comprehensive
参考1 的图,介绍一下MLLM的发展主要有几个阶段:
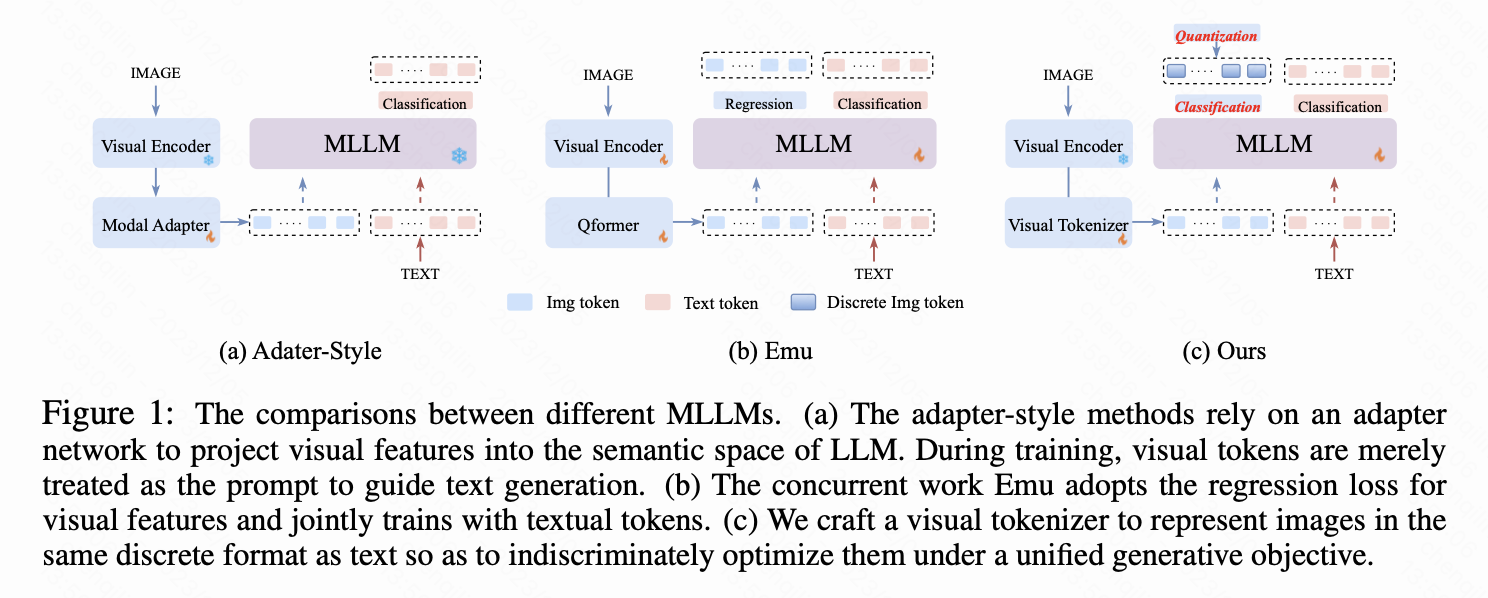
- 输入端多模态:Resampler2(Flamingo)、linear projection3(Llava)、Q-former4(Blip-2)这类模型还没有考虑到只能图生文,搞出来的visual embedding部分仅仅作为prompt不给予监督,训练目标是集中在根据visual content预测description上。可能的问题就是alignment压力全部给到adapter(这也是1试图解决的点)。
- 输出端伪多模态:Kosmos-25 这类研究的MLLM能够回归图片里面的bbox才帮助回答问题,这种方法也可能用在监督Instruction Tuning上,来避免幻觉等一些问题。
- 输入输出端多模态:这类研究要使得图生文可行,就要借助diffusion model或者transformer-based的方式(少数研究)来进行image的解码。所以关键问题是怎么接encoder和decoder了,所以整体模块很相似。而且根据meta6,图片tokenizer、transformer文生图结构至少在22年已经出现。Google的Gemini使用的是自回归的图生成方式。
自回归文生图
VQGAN (2020) & VQVAE (2017)
VQGAN 和的 VQVAE 都是两阶段的图像生成方法,并且出现时间早于diffusion models。
- 训练阶段:训练一个图像压缩模型(包括编码器和解码器两个子模型),再训练一个生成压缩图像的模型。
- 生成阶段:先用第二个模型生成出一个压缩图像,再用第一个模型复原成真实图像。
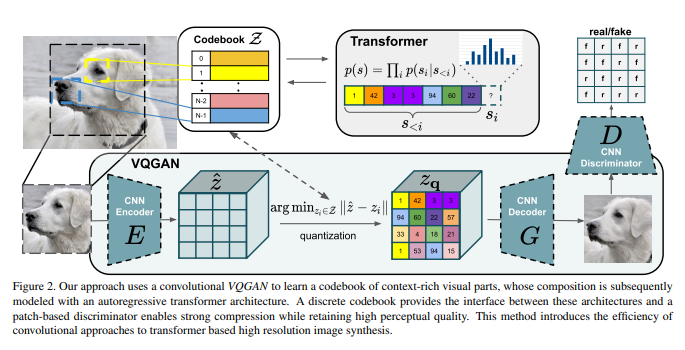
VQ (Vector Quantised)
经过压缩CNN之后的压缩图像是离散的,因此用一个learnable嵌入空间(codebook)去表示每一个压缩像素,这既有利于CNN decoder解压缩(VQVAE&VQGAN),更方便于transformer仿照离散token建模(VQGAN)。
Transformer-based Image Generation
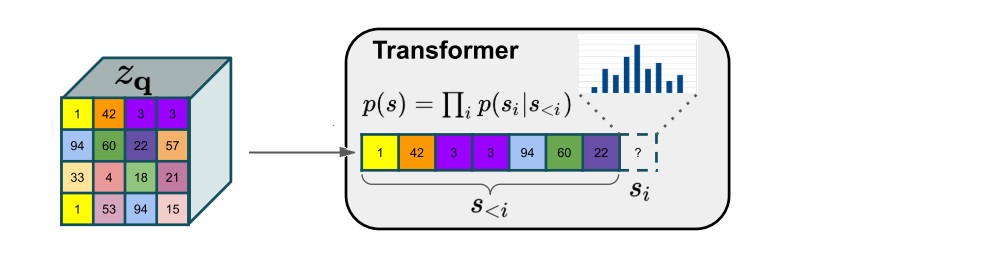
这部分十分粗暴,直接把压缩图像flatten之后就放到transformer中预测恢复图像(next token)
ViT-VQGAN (2021)
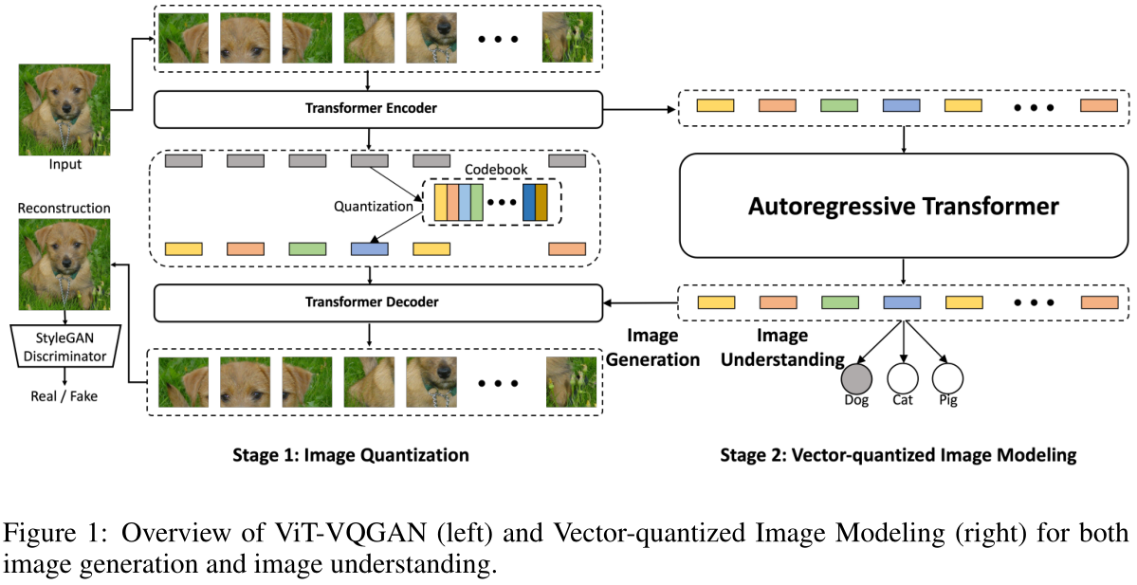
训练分为两个阶段:
- 给定分辨率为256×256的图像,基于Vit的VQGAN将其编码为32×32离散潜码(discretized latent codes),其中codebook大小为8192。
- 训练一个Transformer模型来自回归预测栅格化32×32 = 1024图像标记,其中图像标记由学习的Stage 1 Vit-VQGAN编码。对于无条件图像合成或无监督学习,预先训练一个仅解码器的Transformer模型来预测下一个令牌。为评估无监督学习的质量,平均中间Transformer特征,并学习一个linear head来预测类的logit(也就是linear-probe)。
Parti 中使用的就是这个训练codebook的技术。
ViT-VQGAN is trained end-to-end on image-only data with combined objective functions of logit-laplace loss, l2 loss, adversar- ial loss and perceptual loss (Johnson et al., 2016; Zhang et al., 2018).
Parti (2022)
这个框架很自然的把文本Token(Encoder端)和图片Token(Decoder端)分开了。
训练分为两个阶段:
- 用image data训练一个ViT-VQGAN2模型,这个模型可以把image映射到8000多种不同的visual token上。
- 固定ViT-VQGAN,初始化一个Transformer Encoder和一个Transformer Decoder(其中可以用text corpus和image-text pairs先pre-train一下)。然后开始用Sequence-to-Sequence Autoregression来训练encoder和decoder。这个过程类似于machine translation。其中text起到一个可以帮助初始化第一个token(
-> i_1)和后续的Sequence-to-Sequence学习过程。
推理过程:体的流程是text -> Transformer Encoder -> Transformer Decoder -> visual token sequence -> Image Detokenizer in ViT-VQGAN -> low-resolution desired image (256x256) -> SR module -> high-resolution desired image (1024x1024)。
输入输出端多模态
*cm3leon
这个研究就比较实诚,一点没魔改,全部拼起来。
框架使用的是CM3 multi-modal architecture7
Image Tokenizer 用的是Vector Quantised的方式8,直接自回归,估计也要类似VQGan解码,但是论文里面没有多说这个
总的decoding用了一个之前只用在纯文本大模型上的Contrastive Decoding TopK (CD-K)来提升解码效果。
Gemini
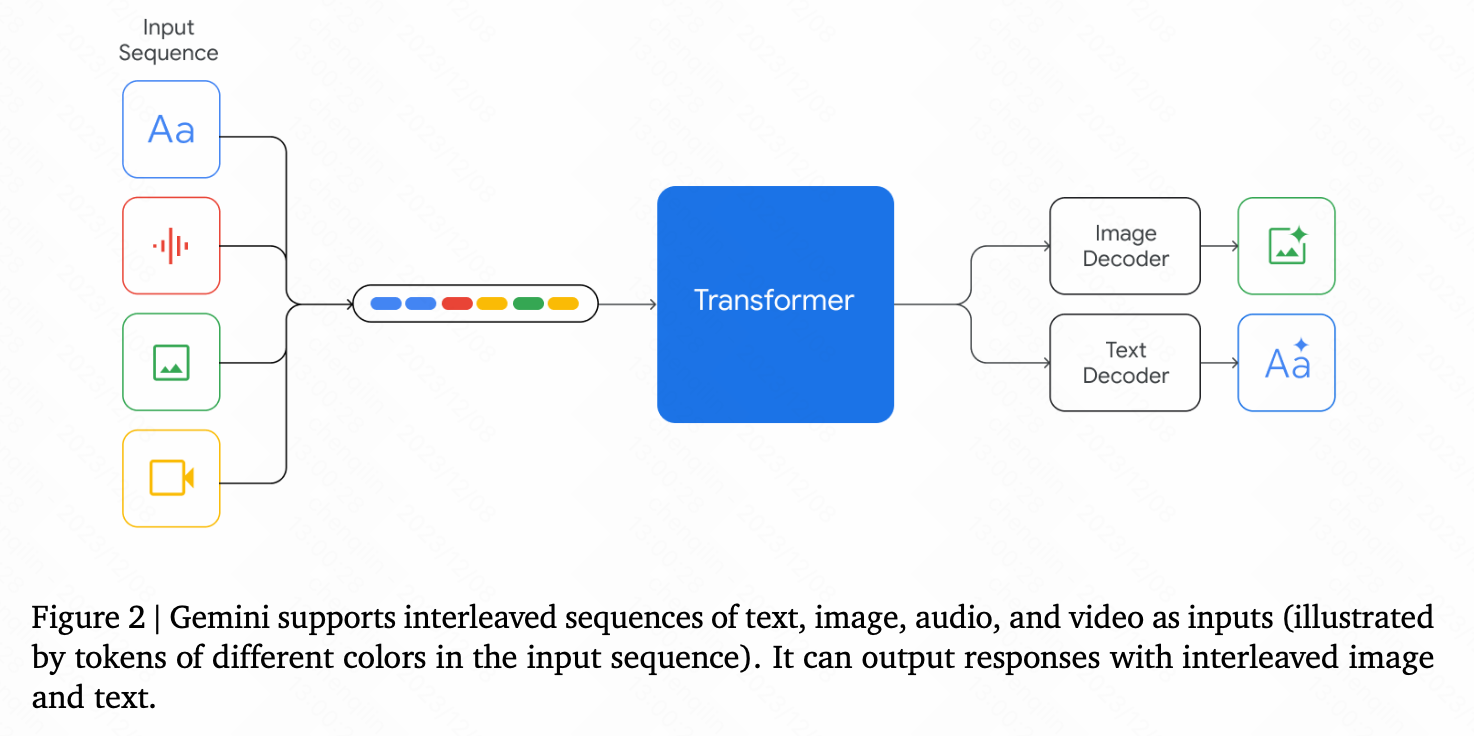
若干技术细节:
- decoder-only 结构
- multi-query attention
- interleaved multi-modal input data
- text and image output data
- visual encoder:Flamingo,CoCa,PaLI(with the important distinction that the models are multimodal from the beginning and can natively output images using discrete image tokens)
- visual decoder:discrete image tokens 910
- video understanding:encoding the video as a sequence of frames,video frames or images can be interleaved naturally with text or audio as part of the model input
- audio understanding:can understand signals from Universal Speech Model (USM)
Emu
Emu is then end-to-end trained with a unified objective of classifying the next text token or regressing the next visual embedding in the multimodal sequence.

- Casual Transformer把图片转化成有next-token依赖的形式,为了适用于“Unified next-token prediction”
- Image Regression最终是通过condition的方式输入进去SD的 (SD不监督)
We adopt the cross-entropy classification loss for discrete text tokens, and the l2 regression loss for continuous visual embeddings.
We replace the linear projections of the cross-attention modules in Stable Diffusion with new linear layers that accommodate the dimension of Emu and Stable Diffusion.
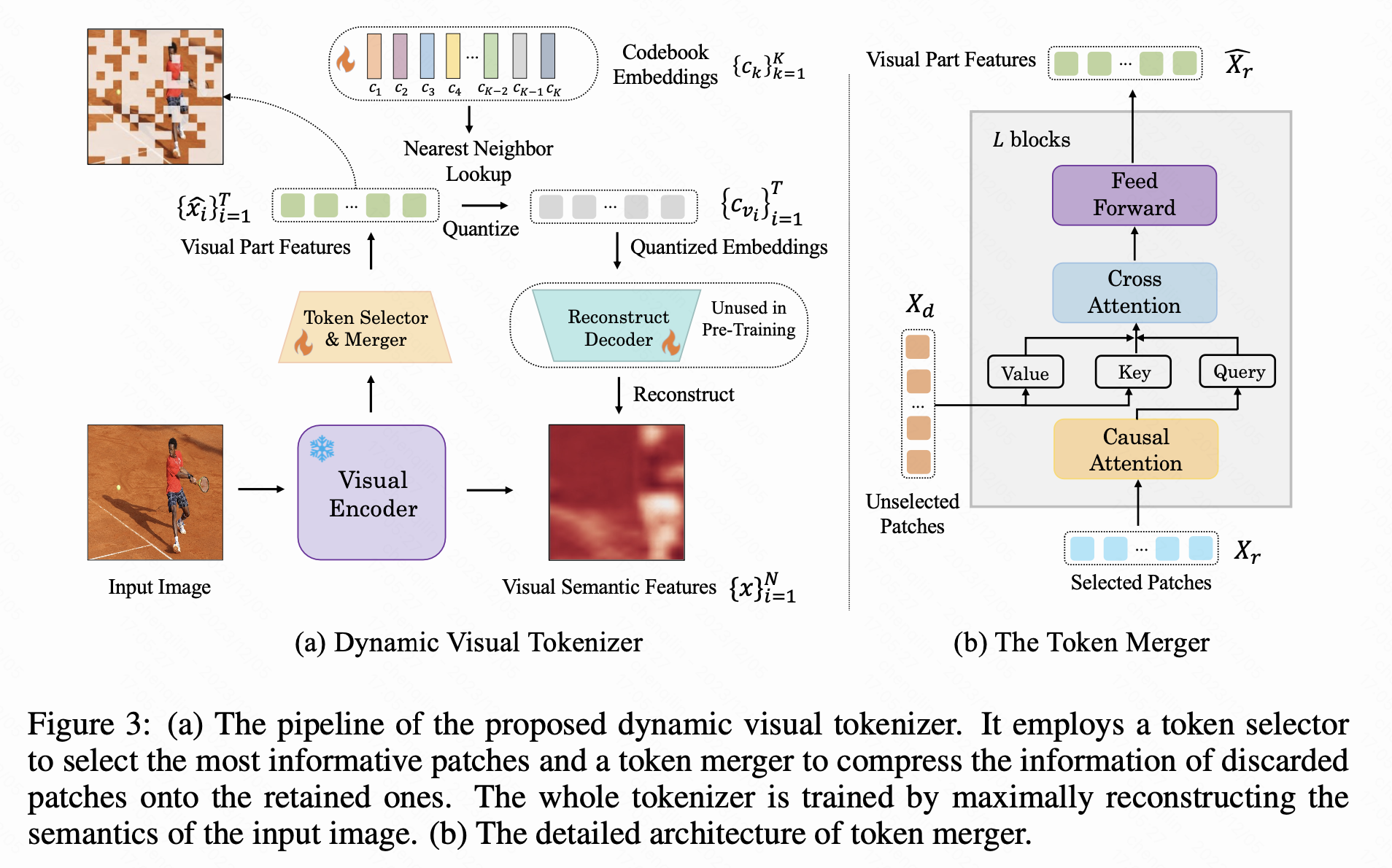
Dynamic Discrete Visual Tokenization
总体框架如下,和emu相似,关键在于怎么设计图片的编码和解码了。
相比于emu分别处理图片、文字的方法,DDVT想能不能给图片也整一个离散tokenizer,这样的话objective逻辑就真正一致了,所以有了下面图示这个方法,同时训练一个动态、离散tokenizer和对应的detokenizer:
- Dynamic是由Token Selector&Merger做到的,这个结构感觉参考了Blip2的cross attention,目标就是压缩一下无关的patch。
- Discrete是由Codebook Embedding做到的。
- Reconstruction Decoder在这一步监督训练,但是只在infer中使用,解码出condition
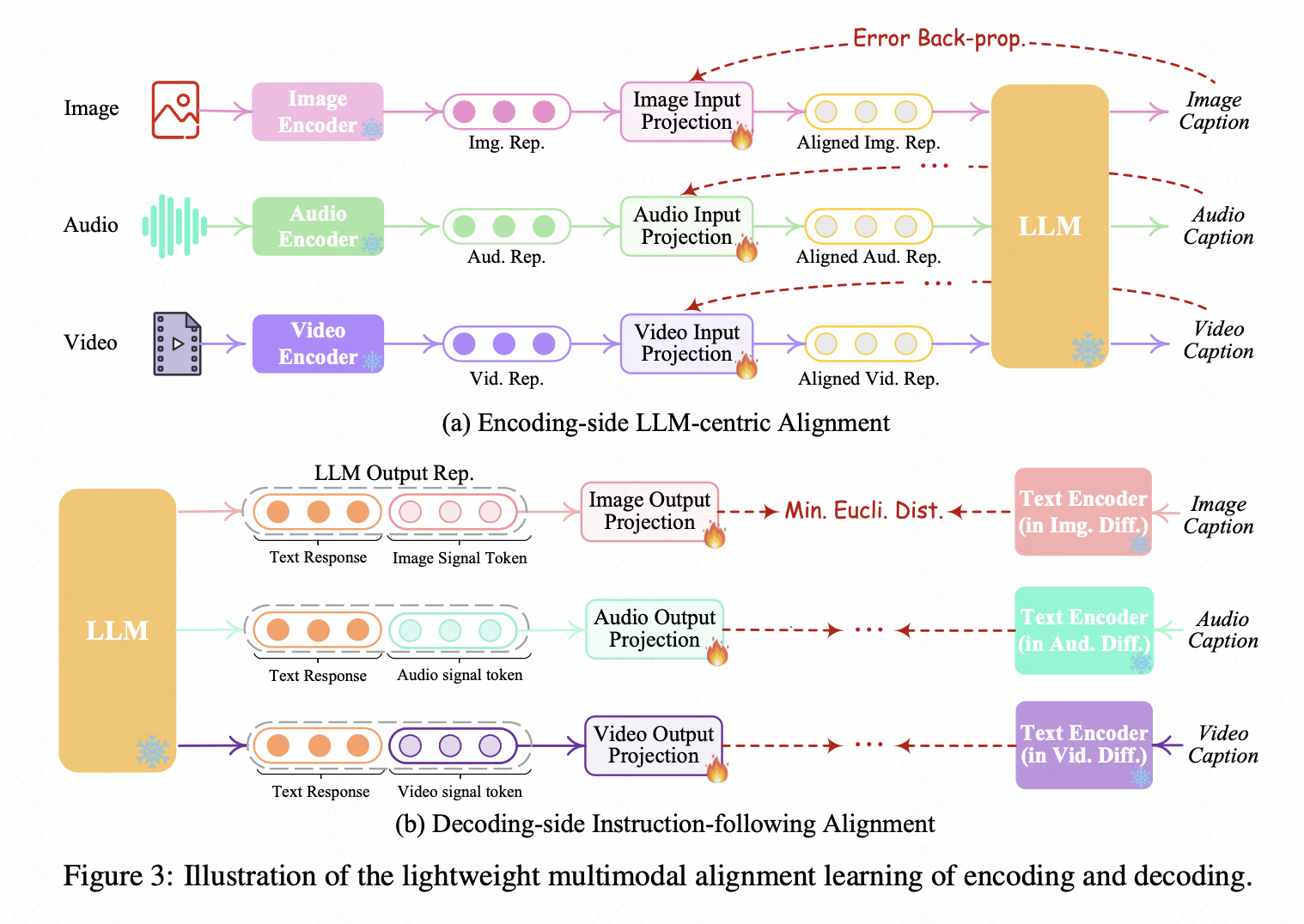
NExT-GPT
总体框架十分简单,就是用了6个projection layer(projection layer用的是transformer layer)。并且这里的projection只是发生在embedding层面上,看下面alignment的原理就可以看出来。

CoDi-2
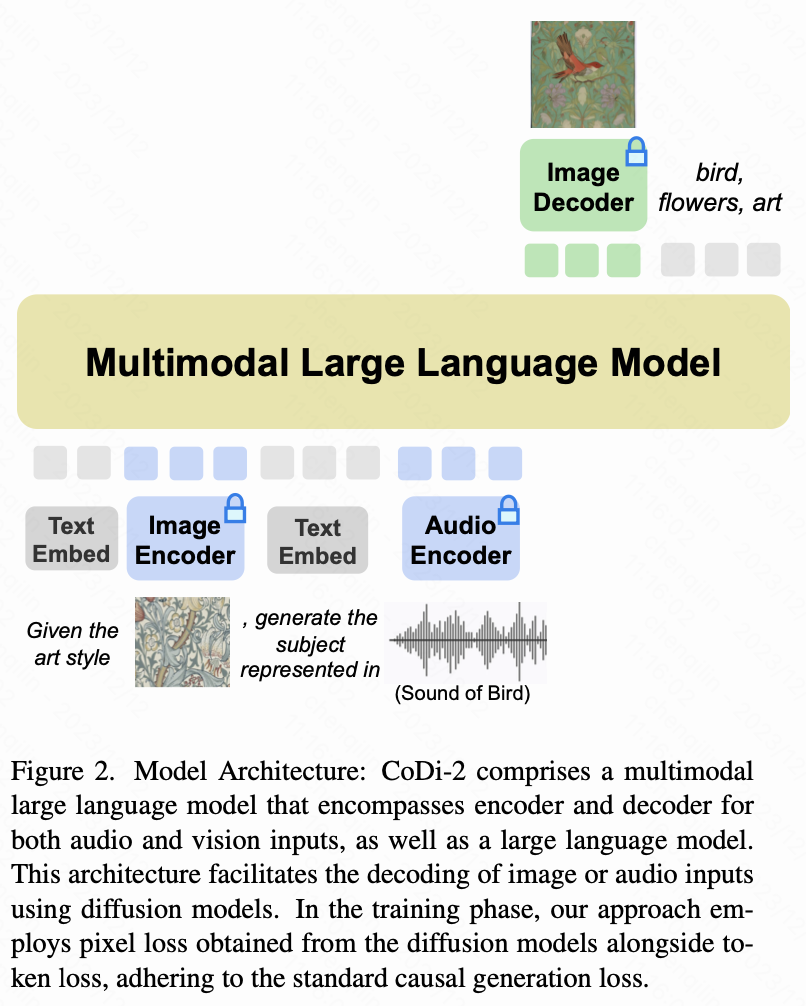
Challenge: In previous multimodal generative models, the backbone is mostly diffusion models (DMs) which are good at generation but intrinsically lack the capability to perform in-context understanding
SD是参与Loss计算的:In training CoDi-2, the gradient obtained from the diffusion models’ generation loss also directly back-propagates to the LLM which can enhance the perceptual faithfulness to the inputs including images or audio.
输入端多模态
Fuyu11
It’s designed from the ground up for digital agents, so it can support arbitrary image resolutions, answer questions about graphs and diagrams, answer UI-based questions, and do fine-grained localization on screen images.
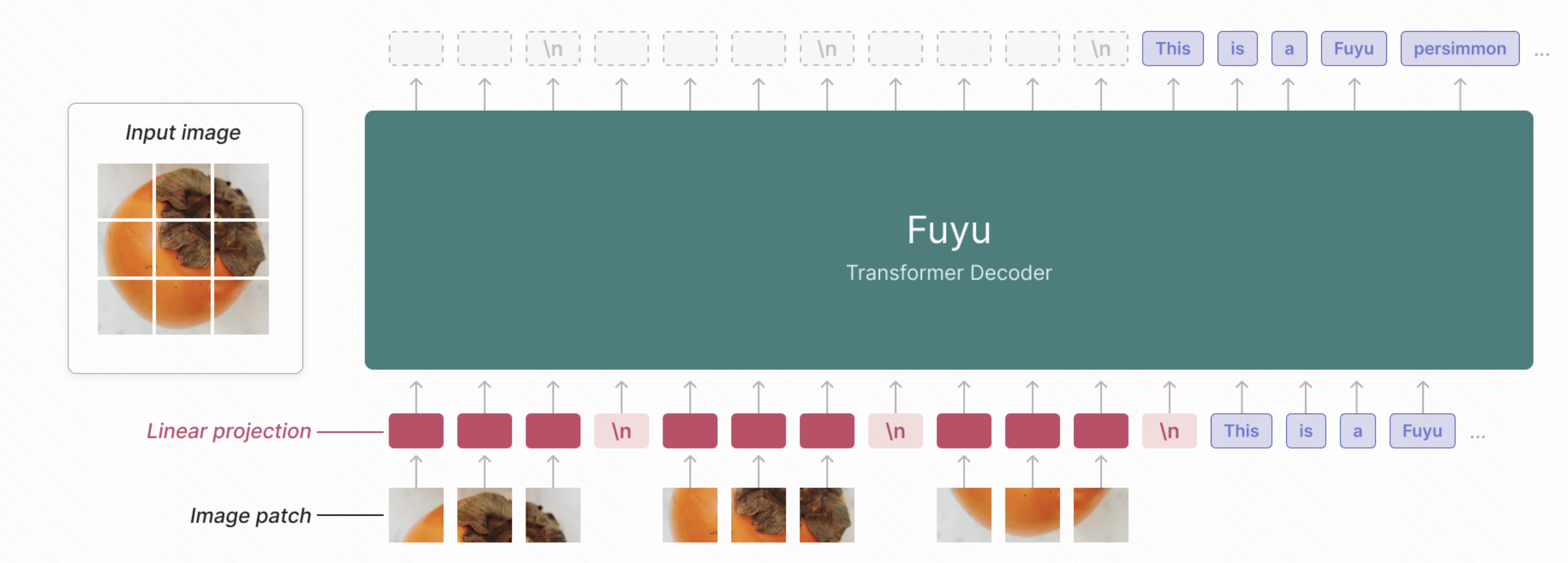
Fuyu的几个特点:
- with no specialized image encoder
- Image patches are linearly projected(without codebook)
- remove image-specific position embeddings and feed in as many image tokens as necessary in raster-scan order. To tell the model when a line has broken, we simply use a special image-newline character.
oneLLM
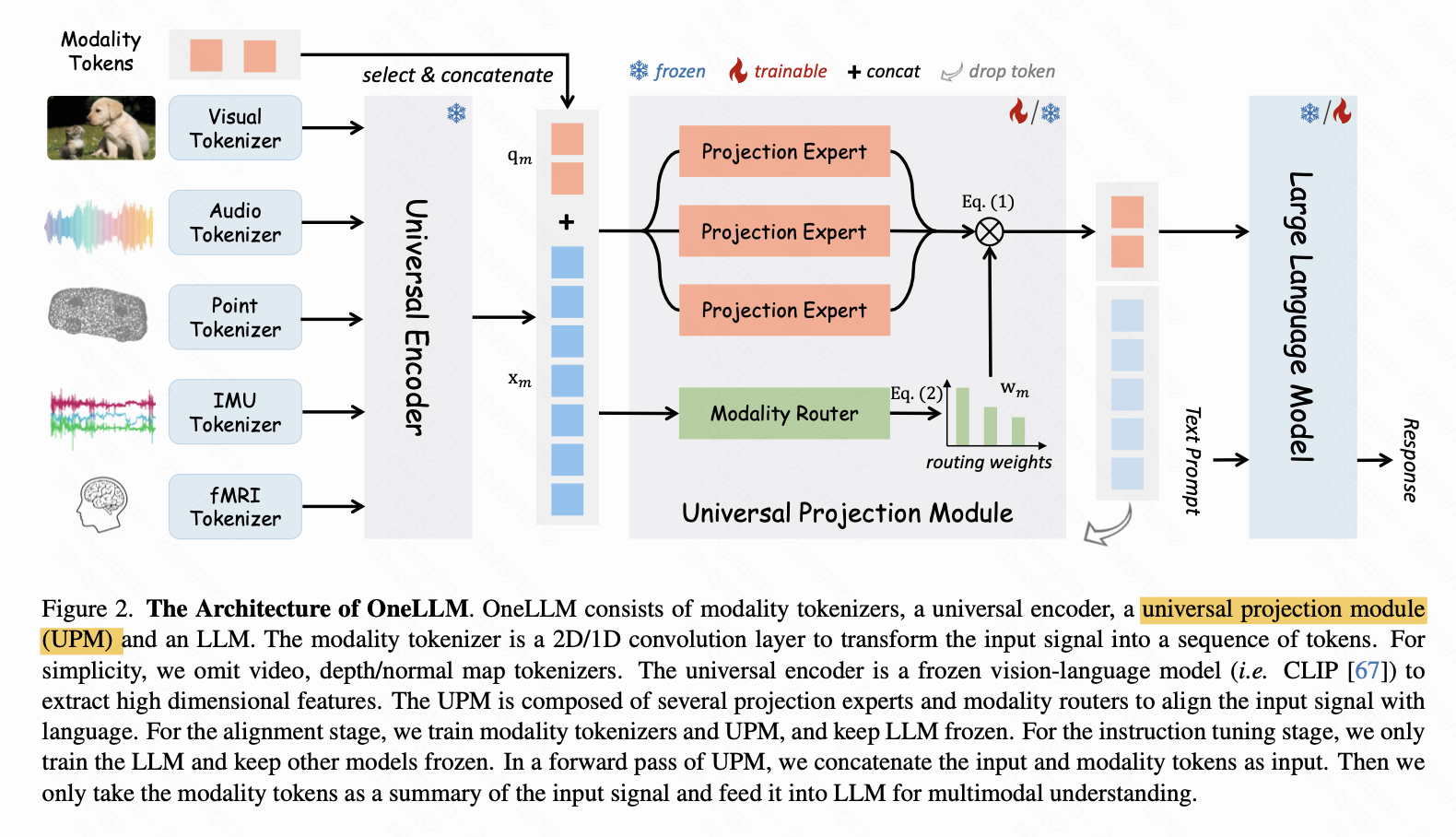
主要思想:用一个vision-language model去提取各个模态的特征,之后用一个learnable、固定长度的modality tokens通过一个带激活的projection去学习(或者说接收)映射得到的特征。
Reference
-
Jin, Yang, et al. “Unified language-vision pretraining with dynamic discrete visual tokenization.” arXiv preprint arXiv:2309.04669 (2023). ↩ ↩2
-
Alayrac J B, Donahue J, Luc P, et al. Flamingo: a visual language model for few-shot learning[J]. Advances in Neural Information Processing Systems, 2022, 35: 23716-23736. ↩ ↩2
-
Liu H, Li C, Wu Q, et al. Visual instruction tuning[J]. arXiv preprint arXiv:2304.08485, 2023. ↩
-
Li J, Li D, Savarese S, et al. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models[J]. arXiv preprint arXiv:2301.12597, 2023. ↩
-
Peng Z, Wang W, Dong L, et al. Kosmos-2: Grounding Multimodal Large Language Models to the World[J]. arXiv preprint arXiv:2306.14824, 2023. ↩
-
Yu L, Shi B, Pasunuru R, et al. Scaling autoregressive multi-modal models: Pretraining and instruction tuning[J]. arXiv preprint arXiv:2309.02591, 2023. ↩
-
Aghajanyan A, Huang B, Ross C, et al. Cm3: A causal masked multimodal model of the internet[J]. arXiv preprint arXiv:2201.07520, 2022. ↩
-
Gafni O, Polyak A, Ashual O, et al. Make-a-scene: Scene-based text-to-image generation with human priors[C]//European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022: 89-106. ↩
-
Ramesh, Aditya, et al. “Zero-shot text-to-image generation.” International Conference on Machine Learning. PMLR, 2021. ↩
-
Yu, Jiahui, et al. “Scaling autoregressive models for content-rich text-to-image generation.” arXiv preprint arXiv:2206.10789 2.3 (2022): 5. ↩
-
Fuyu-8B: A Multimodal Architecture for AI Agents https://www.adept.ai/blog/fuyu-8b. ↩