[TOC]
VQGAN (2020) & VQVAE (2017)
Framework
VQGAN1 和上古时代的 VQVAE2都是两阶段的图像生成方法,并且出现时间早于diffusion models。
- 训练阶段:训练一个图像压缩模型(包括编码器和解码器两个子模型),再训练一个生成压缩图像的模型。
- 生成阶段:先用第二个模型生成出一个压缩图像,再用第一个模型复原成真实图像。
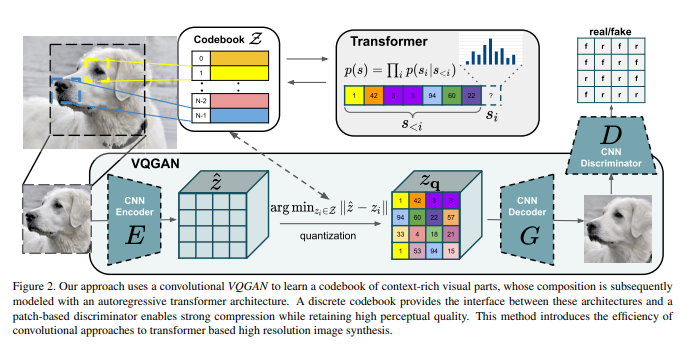
VQ (Vector Quantised)
经过压缩CNN之后的压缩图像是离散的,因此用一个learnable嵌入空间(codebook)去表示每一个压缩像素,这既有利于CNN decoder解压缩(VQVAE&VQGAN),更方便于transformer仿照离散token建模(VQGAN)。
Transformer-based Image Generation
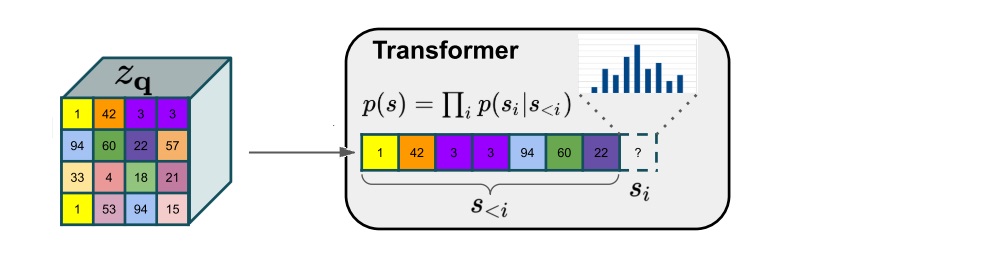
这部分十分粗暴,直接把压缩图像flatten之后就放到transformer中预测恢复图像(next token)
但是有两个技术:
- 带约束的图像生成:这个好办,重新训一个VQGAN,把条件图片(e.g., 语义分割图)离散编码之后放在prompt位置。
- 生成高清图像:用了一个滑动窗口策略,把第一次生成图片用滑动窗口逐步再次生成,扩展细节。
ViT-VQGAN3 (2021)
Framework
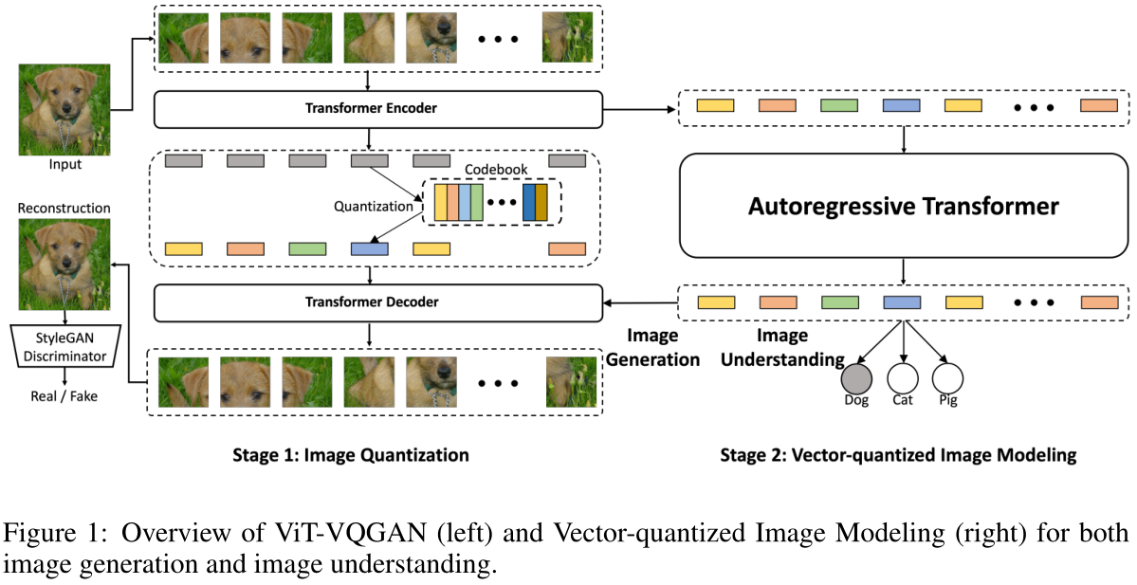
训练分为两个阶段:
- 给定分辨率为256×256的图像,基于Vit的VQGAN将其编码为32×32离散潜码(discretized latent codes),其中codebook大小为8192。
- 训练一个Transformer模型来自回归预测栅格化32×32 = 1024图像标记,其中图像标记由学习的Stage 1 Vit-VQGAN编码。对于无条件图像合成或无监督学习,预先训练一个仅解码器的Transformer模型来预测下一个令牌。为评估无监督学习的质量,平均中间Transformer特征,并学习一个linear head来预测类的logit(也就是linear-probe)。
Parti 中使用的就是这个训练codebook的技术。
ViT-VQGAN is trained end-to-end on image-only data with combined objective functions of logit-laplace loss, l2 loss, adversar- ial loss and perceptual loss (Johnson et al., 2016; Zhang et al., 2018).
Parti4 (2022)
Framework
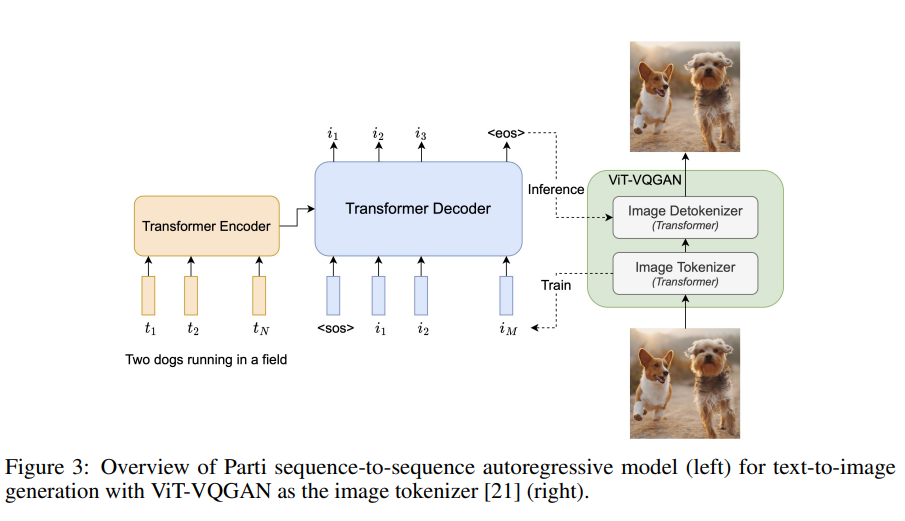
这个框架很自然的把文本Token(Encoder端)和图片Token(Decoder端)分开了。
训练分为两个阶段:
- 用image data训练一个ViT-VQGAN3模型,这个模型可以把image映射到8000多种不同的visual token上。
- 固定ViT-VQGAN,初始化一个Transformer Encoder和一个Transformer Decoder(其中可以用text corpus和image-text pairs先pre-train一下)。然后开始用Sequence-to-Sequence Autoregression来训练encoder和decoder。这个过程类似于machine translation。其中text起到一个可以帮助初始化第一个token(
-> i_1)和后续的Sequence-to-Sequence学习过程。
推理过程:体的流程是text -> Transformer Encoder -> Transformer Decoder -> visual token sequence -> Image Detokenizer in ViT-VQGAN -> low-resolution desired image (256x256) -> SR module -> high-resolution desired image (1024x1024)。
Experiments
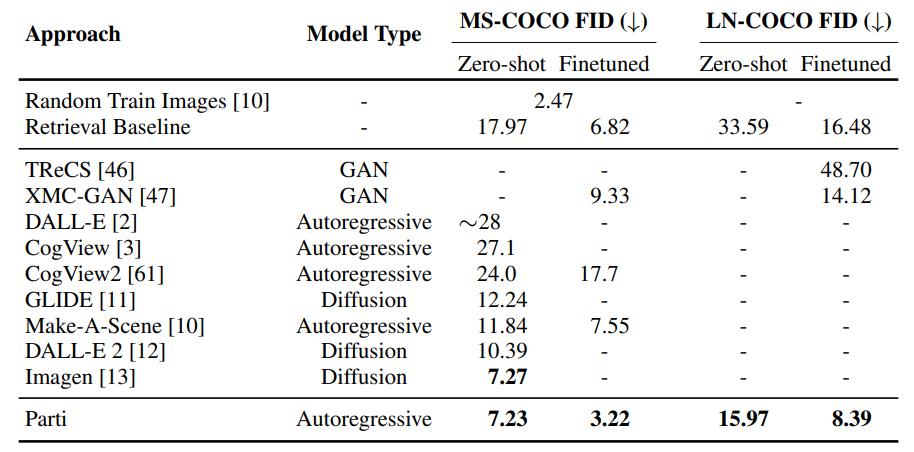
实验部分对比了regressive和diffusion方式的方法(按时间先后排序)
Reference
-
Esser, Patrick, Robin Rombach, and Bjorn Ommer. “Taming transformers for high-resolution image synthesis.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021. ↩
-
Oord, Aaron van den, Oriol Vinyals, and Koray Kavukcuoglu. “Neural discrete representation learning.” arXiv preprint arXiv:1711.00937 (2017). ↩
-
Yu, Jiahui, et al. “Vector-quantized image modeling with improved vqgan.” arXiv preprint arXiv:2110.04627 (2021). ↩ ↩2
-
Yu, Jiahui, et al. “Scaling autoregressive models for content-rich text-to-image generation.” arXiv preprint arXiv:2206.10789 2.3 (2022): 5. ↩