[TOC]
Model Architecture
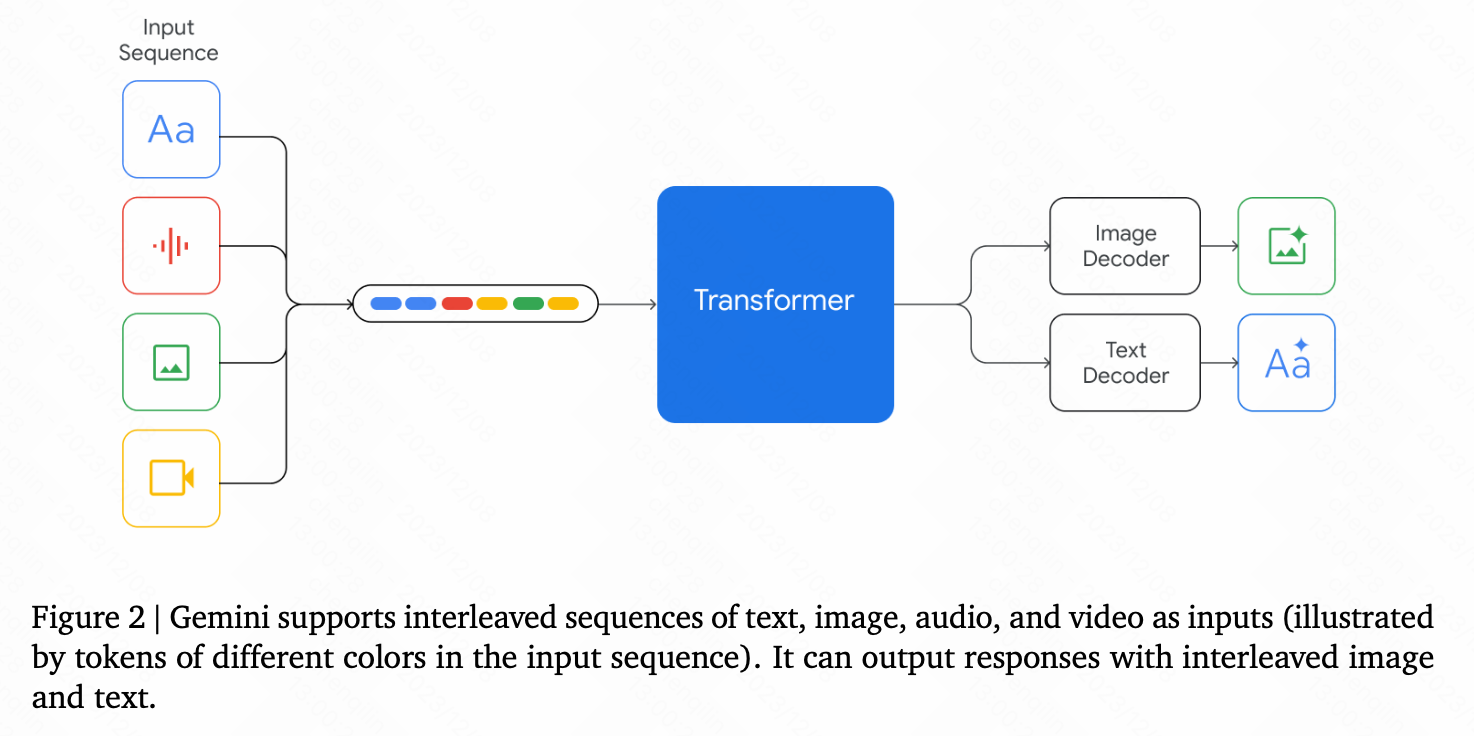
若干技术细节:
- decoder-only 结构
- multi-query attention
- interleaved multi-modal input data
- text and image output data
- visual encoder:Flamingo,CoCa,PaLI(with the important distinction that the models are multimodal from the beginning and can natively output images using discrete image tokens)
- visual decoder:discrete image tokens 12
- video understanding:encoding the video as a sequence of frames,video frames or images can be interleaved naturally with text or audio as part of the model input
- audio understanding:can understand signals from Universal Speech Model (USM)