[TOC]
Any-to-Any Generation via Composable Diffusion
NeurlPS 23
Abs
- 支持模态自由组合
CoDi is free on input modality combination, even if they are not present in the training data.
- Highly customizable and flexible, CoDi achieves strong joint-modality generation quality, and outperforms or is on par with the unimodal state-of-the-art for single-modality synthesis.
与单模态生成相当甚至超过
Intro
现有的多模态模型使用场景受限(e.g., text-to-text, text-to-image, image-to-text),虽然可以进行multi-step或者multi-module的拼接,但是这样的过程 (1) cumbersome and slow、并且 (2) 在输出流上表现出不连续性(post-processing的多模态方案)。
如果要训一个这种any composable-to-any composable的模型,有两个challenge:(1) 组合modality产生巨量计算数据需求;(2) 满足多种模态交叉的数据实际上很少。
CoDi的方案:
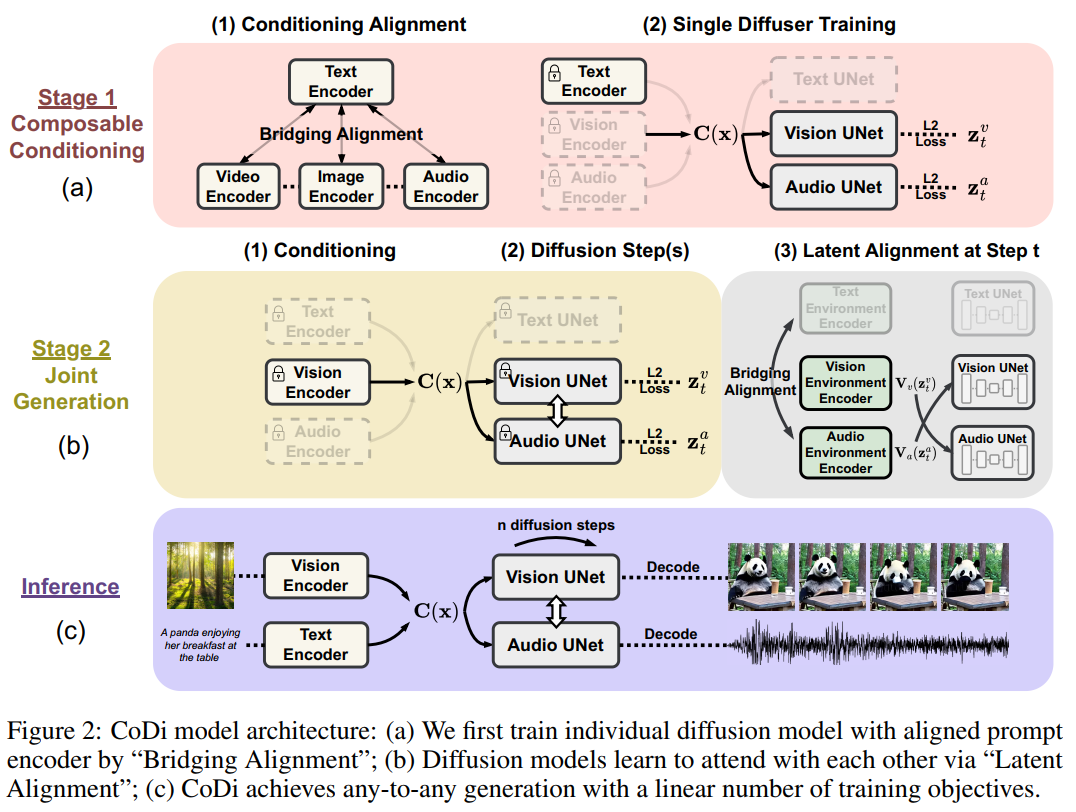
- we train a latent diffusion model (LDM) for each modality,其实就是把输入对齐在一个shared feature space,这个步骤保证了单模态的生成质量
- 为了保证输出simultaneous的特性,要对齐给每一个diffuser加一个cross-attention module和environment encoder V,这两个组件project the latent variable of different LDMs into a shared latent space
Method
Bg
Multimodal modeling: 构建多模态在与构建统一表示,作用在于跨模态理解
researchers striving to build uniform representations of multiple modalities using a single model to achieve more comprehensive cross-modal understanding.
看下这几个reference:Aligning data from different modalities is an active research area [12, 38], with promising applications in cross-modality retrieval and building uniform multimodal representations [33, 35, 41].
12: Clap: Learning audio concepts from natural language supervision. arXiv preprint arXiv:2206.04769, 2022.
38: Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
33: Audioldm: Text-to-audio generation with latent diffusion models. arXiv preprint arXiv:2301.12503, 2023.
35: Clipcap: Clip prefix for image captioning. arXiv preprint arXiv:2111.09734, 2021.
41: High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022.
Method
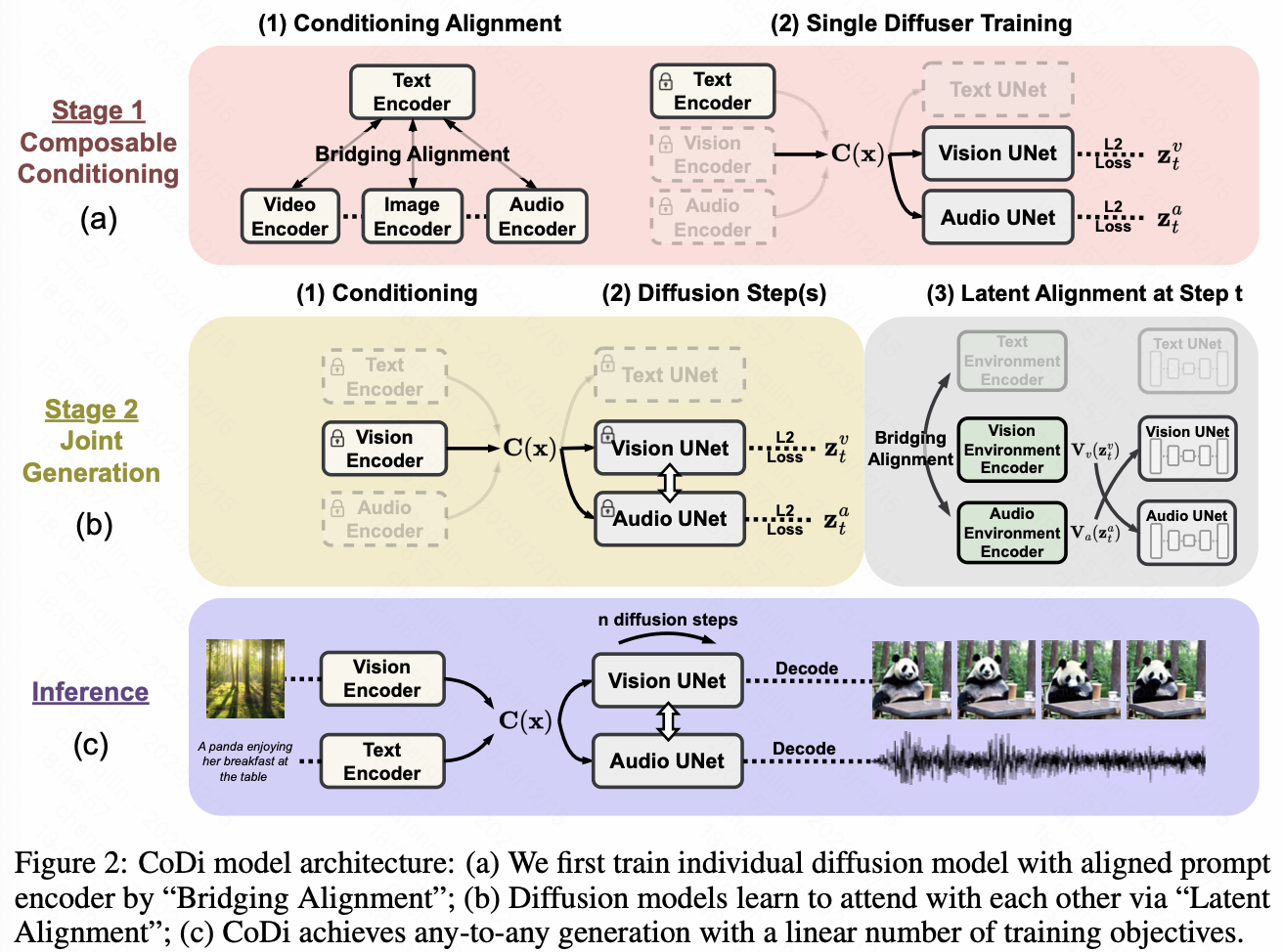
Composable Multimodal Conditioning
-
(a)(1) 为了防止多个模态之间任意组合带来的$O(n^2)$复杂度、以及这样任二组合带来的数据稀缺,Bridging ALignment 用一个pretrain 的CLIP VIT(frozen),其他几个模态也用text-xxx这样的结构contrastive learning,保证其他几个模态的encoder输出表示在一个latent space
-
(a)(2) 为了用多输入模态训练单一diffuser,我们对condition加权了,之后就放在一个里面独立训练就可以。
Composable Diffusion
-
Image Diffusion Model:reuse Stable Diffusion 1.5
- Video Diffusion Model:extending the image diffuser with temporal modules,latent shift method [2] that performs temporal-spatial shifts on latent features in accordance with temporal attention.
- Audio Diffusion Model:similar architecture to vision diffusers;mel-spectrogram can be naturally viewed as an image with 1 channel;VAE encoder;vocoder[27] generates the audio sample from the mel-spectrogram;
- Text Diffusion Model:VAE:OPTIMUS[29];encoder and decoder are [9] and GPT-2 [39];
这个研究用的text decoder是GPT2,还有另外一个encoder。我觉得我们得想想这样多模态的结构要怎么用在decoder-only里面,还有为什么要用一个很大的LLM,优势是在哪里?