[TOC]
https://arxiv.org/abs/2312.15234
Challenge
LLM deployment: computational intensity, memory consumption
- 两个需求都很大 => 减少需求(量化、稀疏剪枝)
- 考虑到具体硬件设备上,两个需求不平衡(调度,任务划分)
serving scenarios: low latency, high throughput.
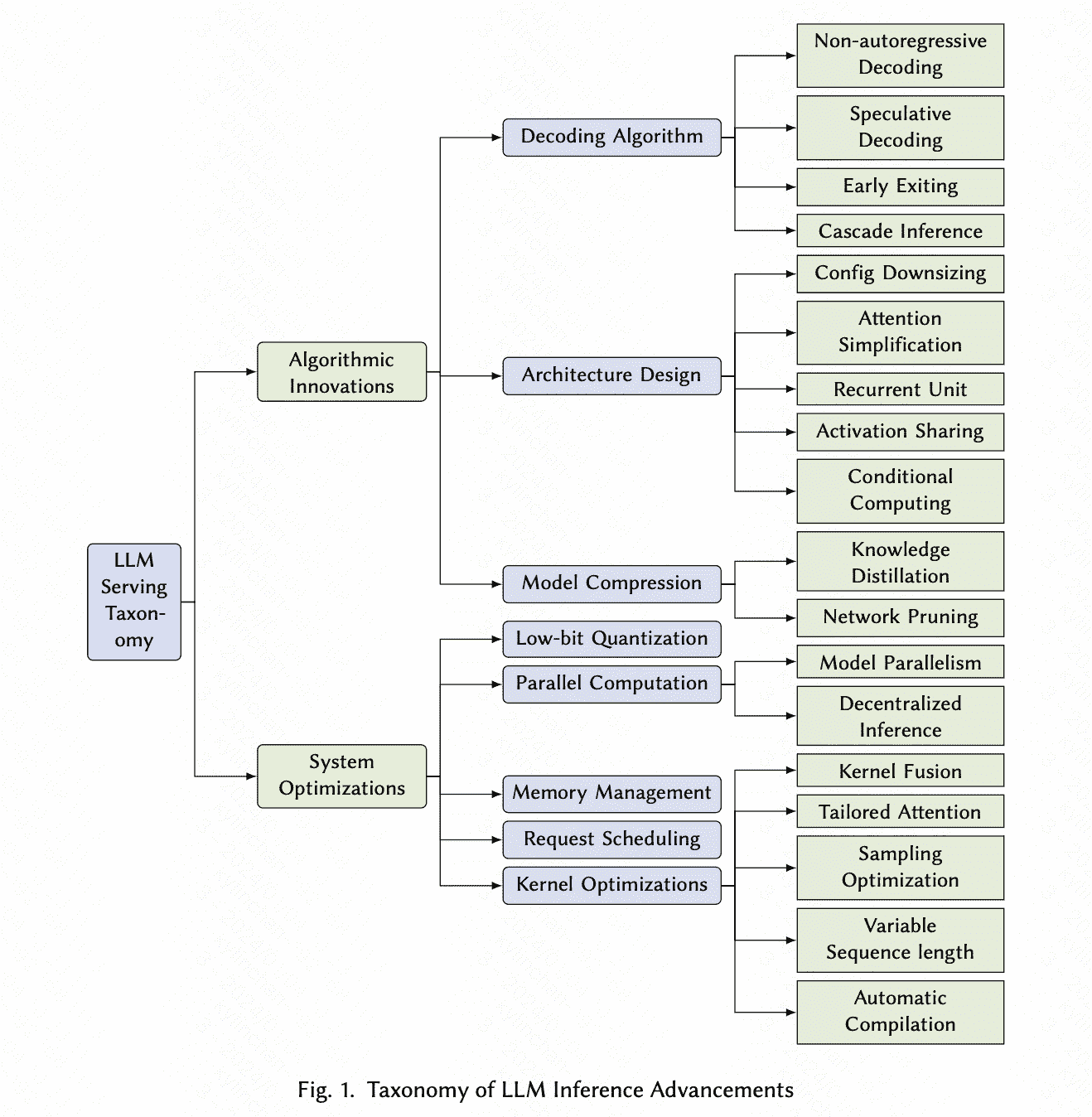
Optimization Techniques
algorithmic innovations
xxx
system optimizations
Low-bit Quantization
xxx
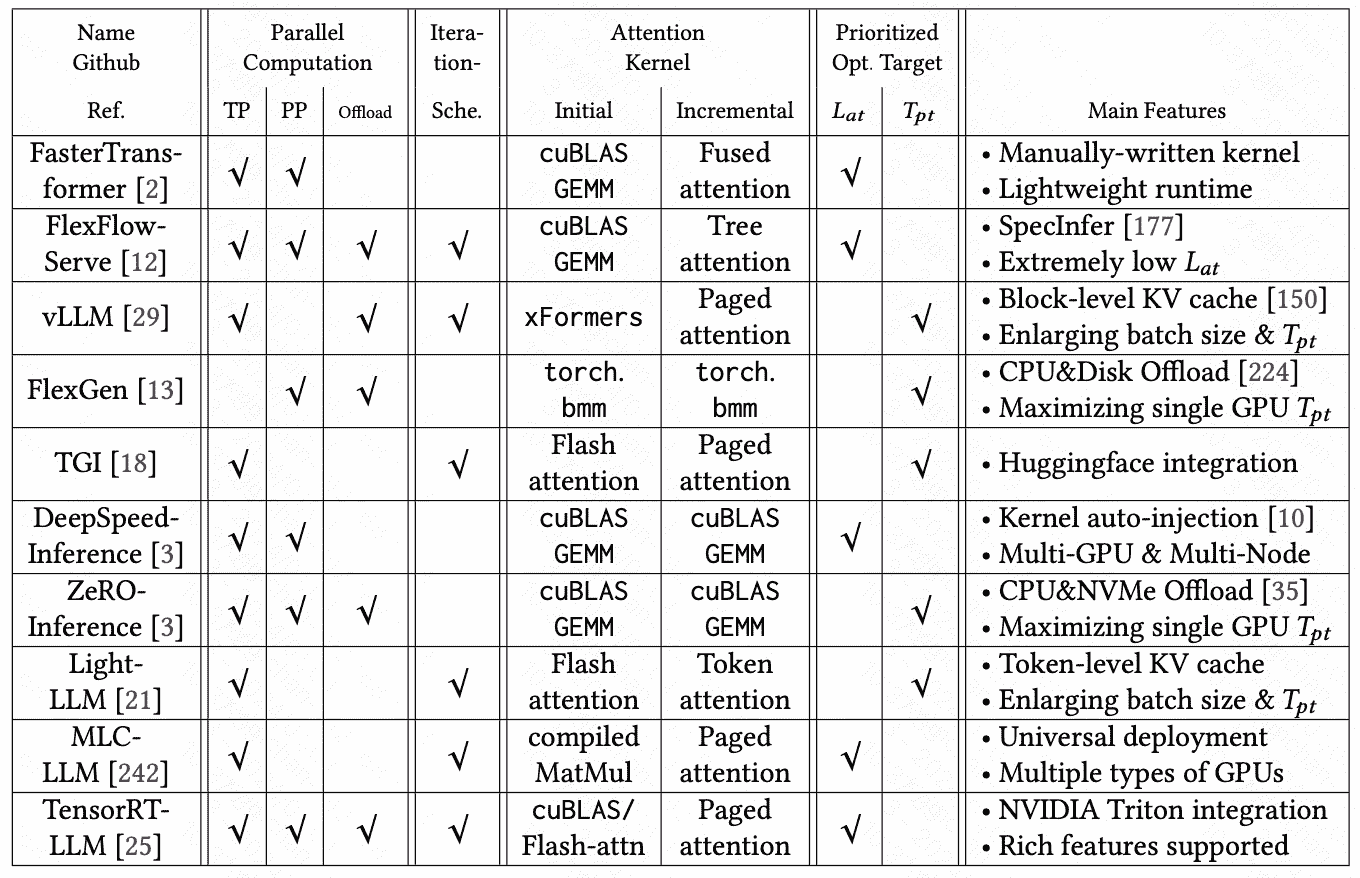
Parallel Computation
- Model Parallel
PP、TP继承自传统的DNN模型优化,Sequence parallelism (SP)1 splitting the processing of long sequences across multiple GPUs along the sequence length dimension
Automatic parallelism: distributed training (e.g., Alpa, FlexFlow, Galvatron)
replacing their cost model to fit the predictable runtime of auto-regressive inference2, it’s easy to apply previous automatic searching algorithms (e.g., dynamic programming, integer linear programming) to LLM serving (e.g., AlpaServe, FlexFlow-Serve, SpotServe)
- Decentralized inference
Petals serves a BLOOM- 176B model using collaborated commodity GPUs over the Internet.
suffers from several practical challenges: device heterogeneity3、limited computational and memory capacity、low-bandwidth network4、fault tolerance、privacy protection5.
Memory Management
传统的方法(FasterTransformer):prompt不一样长、decoding不一样长
vLLM proposes paged attention that partitions the KV cache into non-contiguous memory blocks and significantly improves the batch size as well as throughput.
SpecInfer6 proposes tree attention and depth-first tree traversal to eliminate redundant KV cache allocation for multiple output sequences sharing the same prefix.
LightLLM7 takes a more granular token-level memory management mechanism to further diminish memory usage.
- challenge:
1)其他optimization方法大多专注于提高batchsize(比如带offloading那些),因此细粒度的内存管理可能会带来额外开销&增大serving延迟来换取batchsize。
Especially for cases where other optimizations are employed to boost the batch size, these fine-grained memory management methods might offer only marginal throughput benefits while substantially amplifying the inference latency.
2)可能之适用于特定工作负载&优化方法
3)内存效率和计算性能的平衡
Request Scheduling
调度在传统模型serving中就已经存在,涉及 aspects:dynamic batching8 (dynamic batching 最开始是来自于一个serveless的工作), preemption, priority, swapping, model selection 9 (集成模型选择,需要满足调度和准确率约束), cost efficiency, load balancing and resource allocation.
LLM中特有的challenges:massive model size、iterative autoregressive decoding mechanism、unknown variable output length、state management for context information
Early LLM serving systems (e.g., FasterTransformer over NVIDIA Triton):request-level 调度
Orca:iteration-level scheduling、selective-batching
vLLM and RayLLM:continuous batching
TensorRT-LLM:inflight batching
SpecInfer*(有点关联但是不多):iteratively selecting a batch of requests to perform one iteration of speculative inference and verification
FastServe:关注job completion time (JCT),并且根据input length进行抢占调度
SARATHI:关注GPU利用率和减少气泡,adopted by DeepSpeed-FastGen called Dynamic SplitFuse 10
S^3 9 involves an output sequence length predictor and helps to schedule more concurrent requests within the GPU memory constraint for larger batch size and higher inference throughput.
Kernel Optimization
xxx,不要碰kernel
Baselines/Frameworks
future directions
Hardware Accelerators Co-design
integrating memory closer to processing units (NVIDIA’s Hopper architecture11 ) or optimizing chip architectures to better align with the data flow of LLM algorithms (FlatAttention12)
Deployment in Complex Environments
cloud computing:traditional
edge computing:allows for faster response times and reduced bandwidth usage by processing data closer to the source, but it also poses challenges in terms of limited computational resources and storage capacity.
*** hybrid computing (combining cloud and edge computing) 13:balanced approach but requires advanced management to distribute computational tasks efficiently. 结合隐私数据的 hybrid computing。
decentralized computing:Decentralized computing presents a promising avenue for crowdsourcing computational resources, but it also brings additional considerations regarding data privacy and security 1415.
spot instances (基于市场供需定价的实例,serving over preemptive resources)16: can significantly reduce monetary costs but requires fault tolerance mechanisms to handle their inherent unpredictability and variability, ensuring consistent performance and system reliability.
Decoding Algorithms
vast knowledge encapsulated within LLMs, 但是需要一种 resource-efficient ways => explore alternative approaches to the traditional auto-regressive methods:unlock the generation speed for real-time applications, maintaining the decoding quality.

要生成一个n tokens的句子,从 5^n 中搜索最大的生成概率资源消耗极大,替代使用greedy或者其他sampling策略
- Beam Search:
- 针对算法的系统设计,比如 PagedAttention,decoding 路径分页储存
- generalized speculative inference:
- 一个大LLM和小LLM,小LLM生成candidates,大LLM verifying candidates
- …
可以考虑对一种普遍应用的算法做系统层面的适配
Long Context/Sequence Scenarios Optimization
长文本带来的挑战:
- 算法层面:
- 系统层面:
- memory consumption and access of KV cache
- quadratic increasing computational complexity of self-attention
Alternative Architectures
- attention-free methods20
Specific Requirements
such as parameter-efficient fine-tuning
retrieval from external vector storage
online learning
Reference
-
Hao Liu, Matei Zaharia, and Pieter Abbeel. 2023. Ring Attention with Blockwise Transformers for Near-Infinite Context. arXiv preprint arXiv:2310.01889 (2023). ↩
-
DeepakNarayanan, KeshavSanthanam, PeterHenderson, RishiBommasani, TonyLee, andPercyLiang. 2023.Cheaply Estimating Inference Efficiency Metrics for Autoregressive Transformer Models. In Thirty-seventh Conference on Neural Information Processing Systems. ↩
-
Youhe Jiang, Ran Yan, Xiaozhe Yao, Beidi Chen, and Binhang Yuan. 2023. HexGen: Generative Inference of Foundation Model over Heterogeneous Decentralized Environment. arXiv preprint arXiv:2311.11514 (2023). ↩
-
Alexander Borzunov, Max Ryabinin, Artem Chumachenko, Dmitry Baranchuk, Tim Dettmers, Younes Belkada, PavelSamygin, and Colin Raffel. 2023. Distributed Inference and Fine-tuning of Large Language Models Over The Internet. arXiv preprint arXiv:2312.08361 (2023). ↩
-
Zhenheng Tang, Yuxin Wang, Xin He, Longteng Zhang, Xinglin Pan, Qiang Wang, Rongfei Zeng, Kaiyong Zhao, Shaohuai Shi, Bingsheng He, et al. 2023. FusionAI: Decentralized Training and Deploying LLMs with Massive Consumer-Level GPUs. arXiv preprint arXiv:2309.01172 (2023). ↩
-
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Rae Ying Yee Wong, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, and Zhihao Jia. 2023. SpecInfer: Accelerating Generative LLM Serving with Speculative Inference and Token Tree Verification. arXiv preprint arXiv:2305.09781 (2023). ↩
-
LightLLM. https://github.com/ModelTC/lightllm. Commit: 84671a7, Accessed on: 2023-11-25. ↩
-
Ahsan Ali, Riccardo Pinciroli, Feng Yan, and Evgenia Smirni. 2020. Batch: machine learning inference serving on serverless platforms with adaptive batching. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 1–15. ↩
-
Yunho Jin, Chun-Feng Wu, David Brooks, and Gu-Yeon Wei. 2023. S3: Increasing GPU Utilization during Generative Inference for Higher Throughput. arXiv preprint arXiv:2306.06000 (2023). ↩ ↩2
-
DeepSpeed-FastGen. https://github.com/microsoft/DeepSpeed/tree/master/blogs/deepspeed-fastgen. Accessed on: 2023-11-25. ↩
-
NVIDIA H100 Tensor Core GPU Architecture. https://resources.nvidia.com/en-us-tensor-core/gtc22-whitepaper-hopper. Accessed on: 2023-11-25. ↩
-
Kao, Sheng-Chun, et al. “FLAT: An Optimized Dataflow for Mitigating Attention Bottlenecks.” Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 2023. ↩
-
Qualcomm. 2023. The future of AI is hybrid. https://www.qualcomm.com/content/dam/qcomm-martech/dm- assets/documents/Whitepaper-The-future-of-AI-is-hybrid-Part-2-Qualcomm-is-uniquely-positioned-to-scale- hybrid-AI.pdf. Accessed on: 2023-11-25. ↩
-
Wen-jie Lu, Zhicong Huang, Zhen Gu, Jingyu Li, Jian Liu, Kui Ren, Cheng Hong, Tao Wei, and WenGuang Chen. 2023. BumbleBee: Secure Two-party Inference Framework for Large Transformers. Cryptology ePrint Archive (2023). ↩
-
Mengke Zhang, Tianxing He, Tianle Wang, Fatemehsadat Mireshghallah, Binyi Chen, Hao Wang, and Yulia Tsvetkov. 2023. LatticeGen: A Cooperative Framework which Hides Generated Text in a Lattice for Privacy-Aware Generation on Cloud. arXiv preprint arXiv:2309.17157 (2023). ↩
-
Xupeng Miao, Chunan Shi, Jiangfei Duan, Xiaoli Xi, Dahua Lin, Bin Cui, and Zhihao Jia. 2024. SpotServe: Serving Generative Large Language Models on Preemptible Instances. Proceedings of ASPLOS Conference (2024). ↩
-
In Gim, Guojun Chen, Seung-seob Lee, Nikhil Sarda, Anurag Khandelwal, and Lin Zhong. 2023. Prompt Cache: Modular Attention Reuse for Low-Latency Inference. arXiv preprint arXiv:2311.04934 (2023). ↩
-
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2023. LongLLM- Lingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression. arXiv preprint arXiv:2310.06839 (2023). ↩
-
PengXu, WeiPing, XianchaoWu, LawrenceMcAfee, ChenZhu, ZihanLiu, SandeepSubramanian, EvelinaBakhturina, Mohammad Shoeybi, and Bryan Catanzaro. 2023. Retrieval meets Long Context Large Language Models. arXiv preprint arXiv:2310.03025 (2023). ↩
-
Vukasin Bozic, Danilo Dordevic, Daniele Coppola, and Joseph Thommes. 2023. Rethinking Attention: Exploring Shallow Feed-Forward Neural Networks as an Alternative to Attention Layers in Transformers. arXiv preprint arXiv:2311.10642 (2023). ↩