[TOC]
Abs
Objective: PowerInfer is introduced as a high-speed LLM inference engine optimized for personal computers equipped with a single consumer-grade GPU.
Insight:
minority, hot neurons: consistently activated across inputs.
majority, cold neurons, vary based on specific inputs.
Innovation: The core innovation of PowerInfer is the exploitation of the high locality inherent in LLM inference, characterized by a power-law distribution in neuron activation. This leads to a novel GPU-CPU hybrid inference engine design.
Experiment:OPT-175B on a single NVIDIA RTX 4090 GPU, only 18% lower than that achieved by a top-tier server-grade A100 GPU.
Intro
按层进行model offload[14] 不是一个好方案,因为会造成 locality mismatch between hardware architecture and the characteristics of LLM inference:因为储存是按着data locality设计的层次化结构,但是layer-wise的划分不符合data locality设计。
而LLM本身是具有locality的。For example, in the OPT model, less than 10% of the elements in the activation map are non-zero, and these can be predicted with more than 93% accuracy at runtime 1。
基于这个insight,PowerInfer认为我们可以把hot neurons和cold neurons进行预处理分层。但是存在以下三个挑战:
- 构建的predictor会占用一部分GPU内存=>自适应的predictor(稀疏、高偏度的predictor可以缩小)
- cuSPARSE 不适用 neuron-aware
- 初始化neuron placement是困难的,integer linear programming problem
Bg
Activation Sparsity
Recent studies have revealed that LLM inference shows a notable sparsity in neuron activa- tion 123
这种sparsity同时存在于 attention 和 MLP 中:
- attention中,一半的head处于minimal contributions
- MLP中,主要是ReLU使得negative的值被过滤,这部分稀疏性极大
因此可以提前预测:it is possible to predict neuron activations a few layers in advance within the ongoing model iteration
关键性研究:DejaVu 1, utilizes MLP-based predictors during inference, achieving a remarkable accuracy rate of at least 93% in pre- dicting neuron activation.
Offloading
GPU-centric
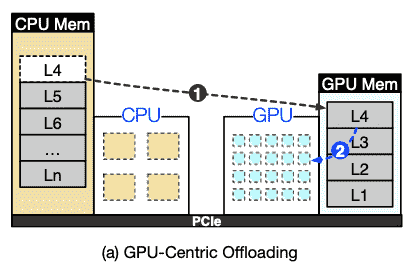
只使用GPU处理单元,需要的数据从CPU传输;典型就是FlexGen4,但是这种方式会牺牲latency换取throughput; DejaVu1利用了稀疏性,但是没有考虑offload
UM技术可以参考一下:Since DejaVu only works for GPU, we modified it by using NVIDIA Unified Memory (UM) 5 to fetch parameters from CPU memory.
Hybrid
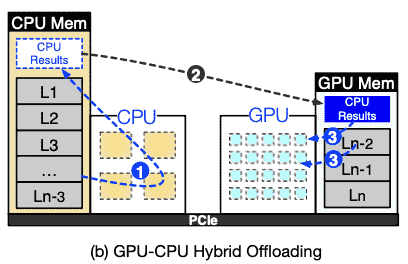
在CPU、GPU之间划分层;The CPU processes its layers first, then sends intermediate results to the GPU for token generation.
优点是缓解GPU、CPU带宽压力,因为传输的仅仅是activations;典型的是llama.cpp6
Insight
Insight1: Power-law Activation

少部分Neurons占有大部分Activation的贡献
Insight2: Fast In-CPU Computation

CPU也可以算的很快,相比传输到GPU计算;especially with the small number of activated neurons and the small batch sizes
PowerInfer
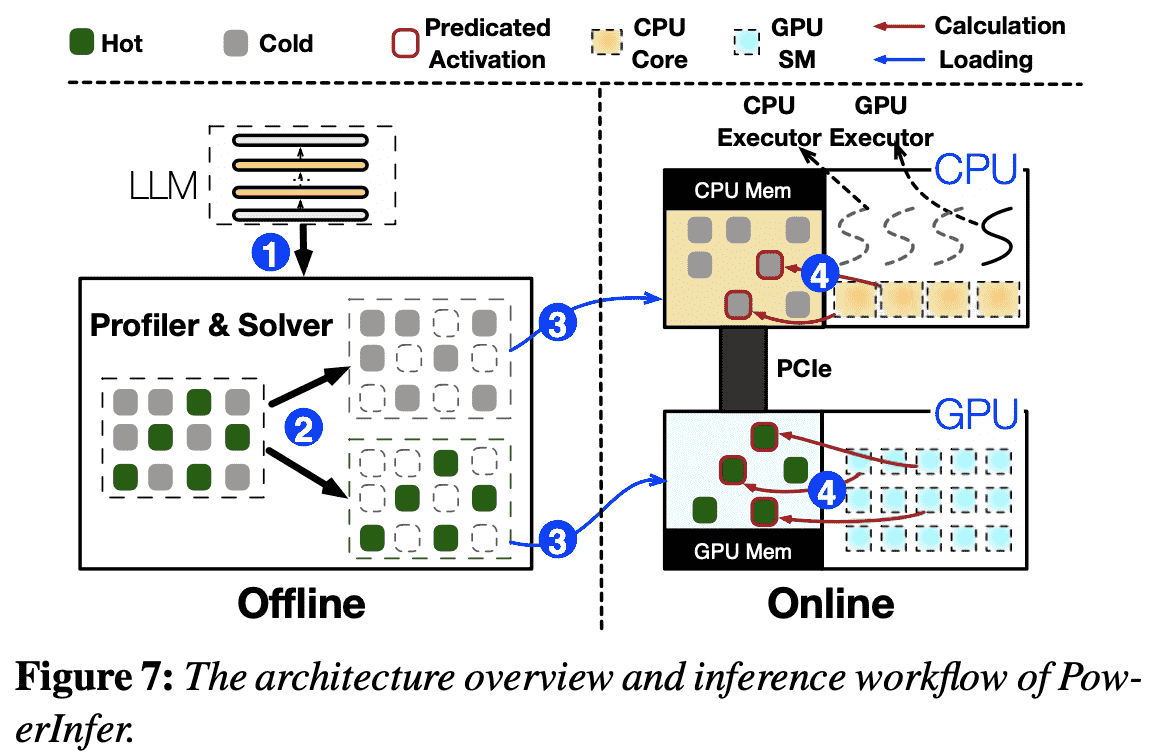
LLM Profiler and Policy Solver (Offline)
step1: 由于对不同的LLM其激活情况是不一样的,所以需要做profile,这一步会从数据集中sample请求
step2: 利用ILP解决cold&hot神经元分配的问题(maximize the GPU’s impact metric for neurons)
Neuron-aware LLM Inference Engine (Online)
step3: preload
step4: 预测激活并且各自执行,只有cpu计算得到的activation会传输。 engine predicts neuron activation and skips non-activated ones. Activated neurons preloaded in GPU memory are processed there, while the CPU calculates and transfers results for its neurons to the GPU for integra- tion.
Eva
baseline:llama.cpp、FlexGen、DejaVu
Metrics:latency
Reference
-
ZichangLiu,JueWang,TriDao,TianyiZhou,BinhangYuan, Zhao Song, Anshumali Shrivastava, Ce Zhang, Yuandong Tian, Christopher Re, and Beidi Chen. Deja vu: Contextual sparsity for efficient LLMs at inference time. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engel- hardt, Sivan Sabato, and Jonathan Scarlett, editors, Proceed- ings of the 40th International Conference on Machine Learn- ing, volume 202 of Proceedings of Machine Learning Re- search, pages 22137–22176. PMLR, 23–29 Jul 2023. ↩ ↩2 ↩3 ↩4
-
Zonglin Li, Chong You, Srinadh Bhojanapalli, Daliang Li, Ankit Singh Rawat, Sashank J Reddi, Ke Ye, Felix Chern, Felix Yu, Ruiqi Guo, et al. The lazy neuron phenomenon: On emergence of activation sparsity in transformers. In The Eleventh International Conference on Learning Representa- tions, 2022. ↩
-
ZhengyanZhang,YankaiLin,ZhiyuanLiu,PengLi,Maosong Sun, and Jie Zhou. MoEfication: Transformer feed-forward layers are mixtures of experts. In Findings of ACL 2022, 2022. ↩
-
YingSheng,LianminZheng,BinhangYuan,ZhuohanLi,Max Ryabinin, Beidi Chen, Percy Liang, Christopher Re, Ion Sto- ica, and Ce Zhang. Flexgen: High-throughput generative in- ference of large language models with a single gpu. 2023. ↩
-
NVIDIA. Unified memory programming. https://docs. nvidia.com/cuda/cuda-c-programming-guide/index. html#um-unified-memory-programming-hd, 2021. ↩
-
Georgi Gerganov. ggerganov/llama.cpp: Port of facebook’s llama model in c/c++. https://github.com/ggerganov/ llama.cpp, 2023. ↩