[TOC]
Abs
challenge: KV cache内存消耗大,现有方法保留max length的KV cache => 导致 bs 小 => GPU利用率不高
insight: 预测output length,并根据这个predictions进行scheduling
Intro
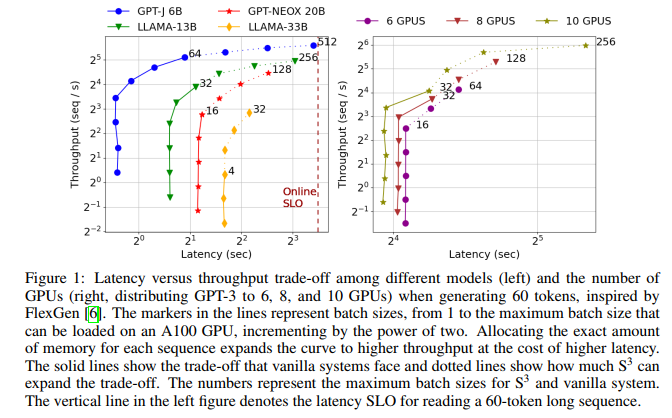
这个图说明的是throughput和latency的权衡,虽然我们希望通过牺牲latency提高throughput(即增大bs),可是GPU Memory不允许,而图中虚线代表了S^3能提供给系统的拓展(本质上是允许了更大的bs)
两种LLM适用场景:Online和Offline
There are two types of LLM deployment scenarios: online and offline:
- Online scenarios such as chatbots require service providers to generate a sequence within a tight latency service level objective (SLO) constraint.
- Offline scenarios include applications such as scoring 1 or data wrangling 2, and have loose latency SLOs, emphasizing throughput over end-to-end latency.
S3认为在SLO之下,继续优化latency意义不大,而是要达到最优化throughput
Solutions
-
训练一个 Distillbert 从prompt去预测生成长度
-
fault handling,mechanism to recover from mispredictions. S3 preempts sequences that exceed their allocated memory and retrain the predictor to learn from its mistakes
Bg&Moti
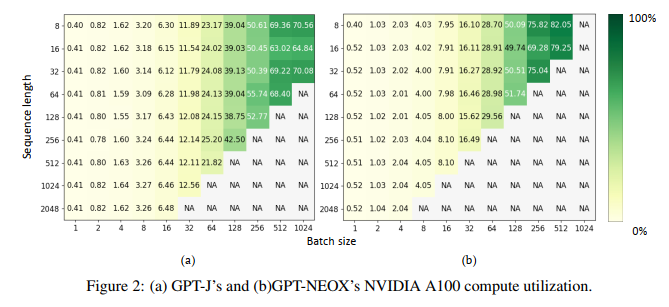
通过这个图可以看出,增加bs有利于提高利用率
从两图对比上看(GPT-J模型小于GPT-NEOX),memory cliff对于更大的模型(更紧张的内存使用)更容易出现
两个baseline:
- HF transformer:逐块分配KV cache,但是分配时候会pending计算
- FasterTransformer:最大KV cache分配
Motivation:baseline的问题在于不知道output length,所以我们给预测一下
S3
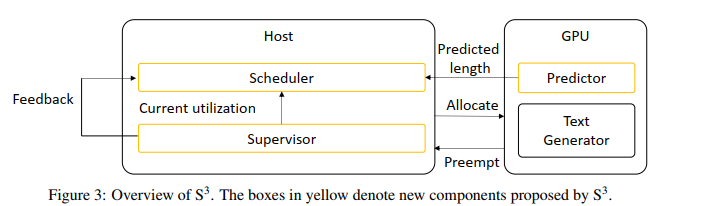
Output sequence length predictor
fine-tune a Distilbert 3 model that was trained for sequence classification to classify which length bucket the output sequence length falls into.
We bucketize the sequence lengthes since it is known that machine learning models are not as capable of the “last mile” search compared to narrowing the candidates down to the last mile. Each bucket is allocated the range of $max_sequence_length / number_of_buckets$ and we use 10 buckets.
Reference
-
“Holistic Evaluation of Language Models,” arXiv e-prints, p. arXiv:2211.09110, Nov. 2022. ↩
-
A. Narayan, I. Chami, L. Orr, S. Arora, and C. Re,“Can Foundation Models Wrangle Your Data?” arXiv e-prints, p. arXiv:2205.09911, May 2022. ↩
-
V. Sanh, L. Debut, J. Chaumond, and T. Wolf, “DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter,” arXiv e-prints, p. arXiv:1910.01108, Oct. 2019. ↩