[TOC]
Abs
challenge: considering LLM inference, KV cache scaling linearly with the sequence length and batch size.
insight: a small portion of tokens contributes most of the value when computing attention scores.
solution: Heavy Hitter Oracle (H2O), a KV cache eviction policy that dynamically retains a balance of recent and Heavy Hitters (H2) tokens.
Introduction
ideal KV cache 应该有三个特征:
- a small cache size to reduce memory footprint
- a low miss rate to maintain the performance and long-content generation ability of LLMs
- a low-cost eviction policy to reduce the wall-clock time during generation
但是有3个challenge:
- it is not immediately clear whether the size of the KV cache can be restricted—each decoding step might, in principle, require access to all previous attention keys and values.
- identifying an optimal eviction policy that maintains generation accuracy is a combinatorial problem【Belady’s Algorithm is optimal for standard cache, but not necessarily for KV cache】.
- even if an optimal policy can be brute-forced, it is infeasible for deployment on real-world applications
论文的preliminary实验的三个observations:
-
Sparsity for small cache size: only 5% of the KV cache is sufficient for decoding the same output token at each generation step
-
Heavy-Hitters for low miss rate: We discover that the accumulated attention scores of all tokens in attention blocks adhere to a power-law distribution.
H2O provides an opportunity to step away from the combinatorial search problem and identify an eviction policy that maintains accuracy
-
Greedy algorithm for low-cost policy: greedy 保留最后几个tokens是有意义的
without缩写成w.o.
所以螺纹的思路就是:
1)证明H2现象的存在
2)H2可以被greedy的办法模拟(最后感觉可以做成一个类似体系结构cache的概念)
Problem Formulation


Insights
- Sparsity for Small Cache Size
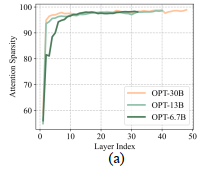
- Heavy-Hitters for Low Miss Rate
其实就是讲幂率分布,少部分token决定大部分attention
Heavy-Hitter Oracle

Experiment
Baselines
- FlexGen(H2O就是在FlexGen基础上实现的)
- DeepSpeed Zero-Inference
- Hugging Face Accelerate
maintaining generation quality across a broad spectrum of domains and tasks.