[TOC]
Abs
一直在强调scaling up这个事情,带来一个疑问:效果的提升和现有架构的优势是不是和37B的参数量有关
Arch
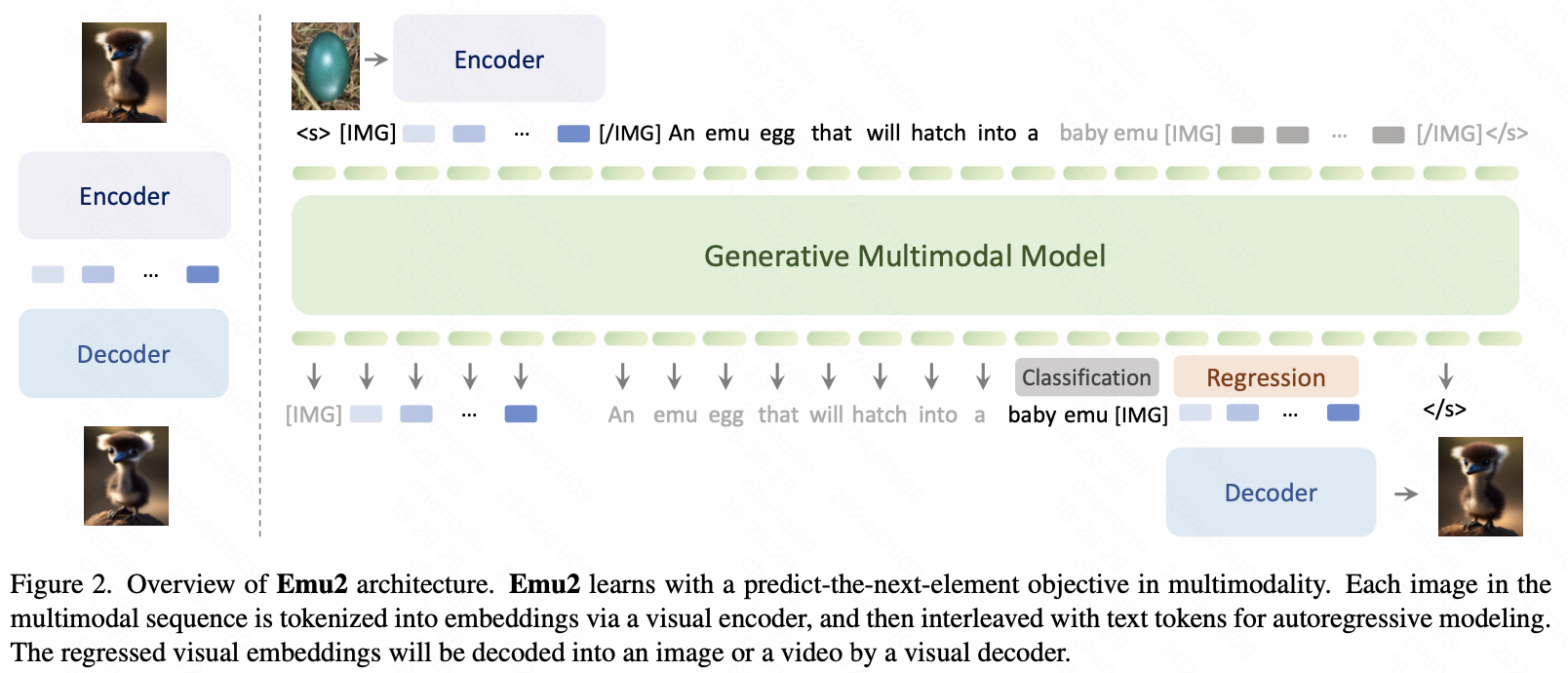
Training
1)first stage:
data:
data:image-text and video-text data
目标:captioning loss(文本loss)
参与训练:linear projection、Multimodel Modeling、Visual Encoder都参与训练
分辨率上先224x224,之后再448x448
2)second stage:
data:image-text interleaved data, video-text interleaved data, grounded image-text pair data, and language-only data
目标:text classification loss and image regression loss
参与训练:linear projection layer、Multimodel Modeling
分辨率448x448
Visual Decoder
use SDXL-base[59] as the initialization of our Visual De- coder, which is fully trained to solve the new task of au- toencoding.
use N visual embeddings as the condition input to the Visual Decoder and adjust the di- mension of the projection layers in cross-attention modules to match the dimension of visual embeddings.
这里的训练就是独立于LLM的了,相当于一个autoencode(training a detokenizer)
Rethink
为啥要搞一个统一多模态的LM?
训练数据上?(感觉说不通),因为vision encoder和decoder本质上都要拿图文对来学习
跨模态融合上!
challenge:训练的困难
回到一种efficient的架构创新