[TOC]
5 Jul 2023, https://arxiv.org/abs/2307.02628
Abs
Bg: early-exit strategies reduce computational cost
Challenges: 现有的方法难以和batch inferencing and Key-Value caching 结合
Method:
- It overcomes prior constraints by setting up a singular exit point for every token in a batch at each sequence position. => 保证不出现KV cache重计算的问题
Intro
early stopping的本质:allowing tokens to cease computation as soon as their hidden states reach saturation [17]
但是现有的研究有两个challenge:
- batch起来之后single sample的退出会提高给scheduling带来挑战
- 依赖于ML分类器的token-level exit strategies不能保证worst case
- 涉及到KV cache重计算问题
insights:
- 约往后的token预测的难度越低 => 可能需求的计算量越小
words towards the end of a sequence are generally easier to predict due to more contextual information.
proposed:
- 单调递减的 exit point
- 为了不浪费previous tokens计算到KV,会选择skip较低的层
SkipDecode
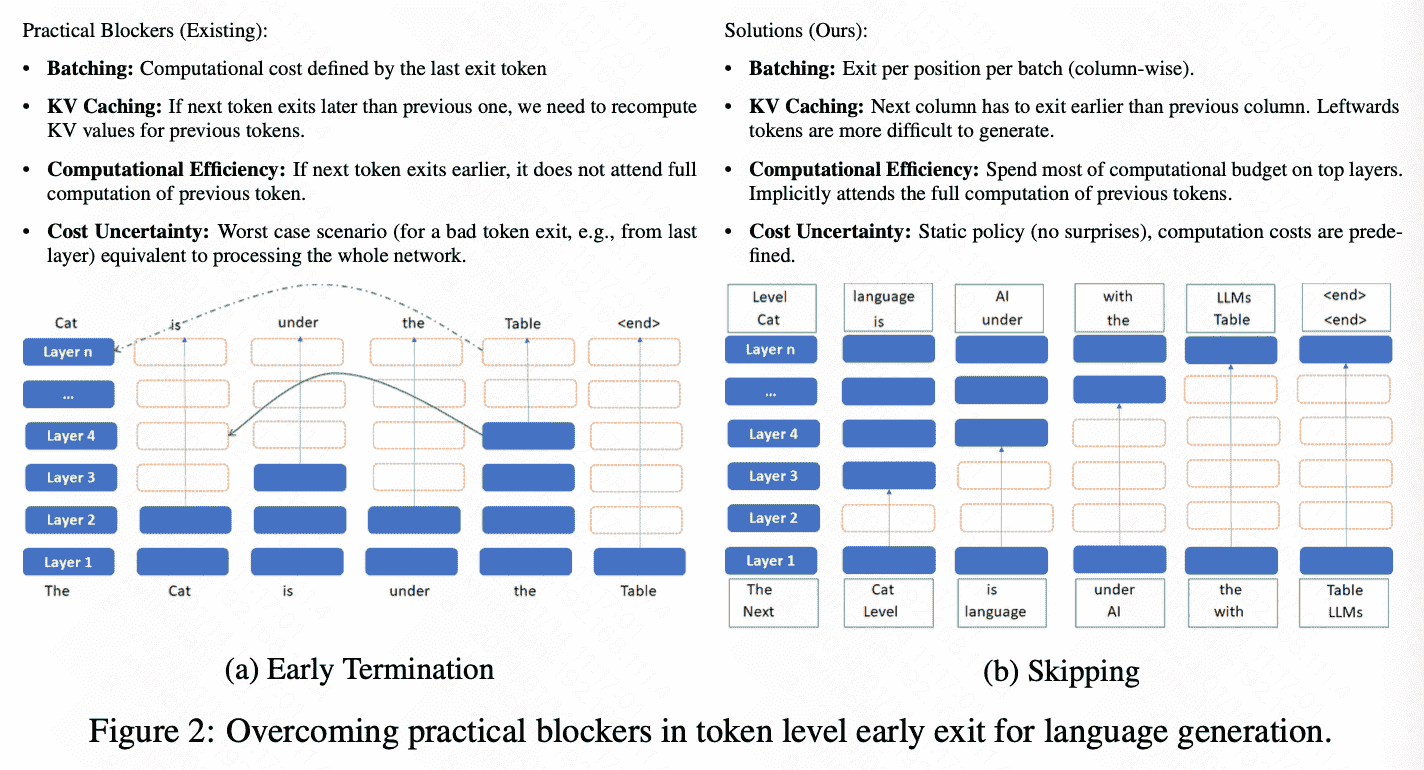
如何指定exit layer
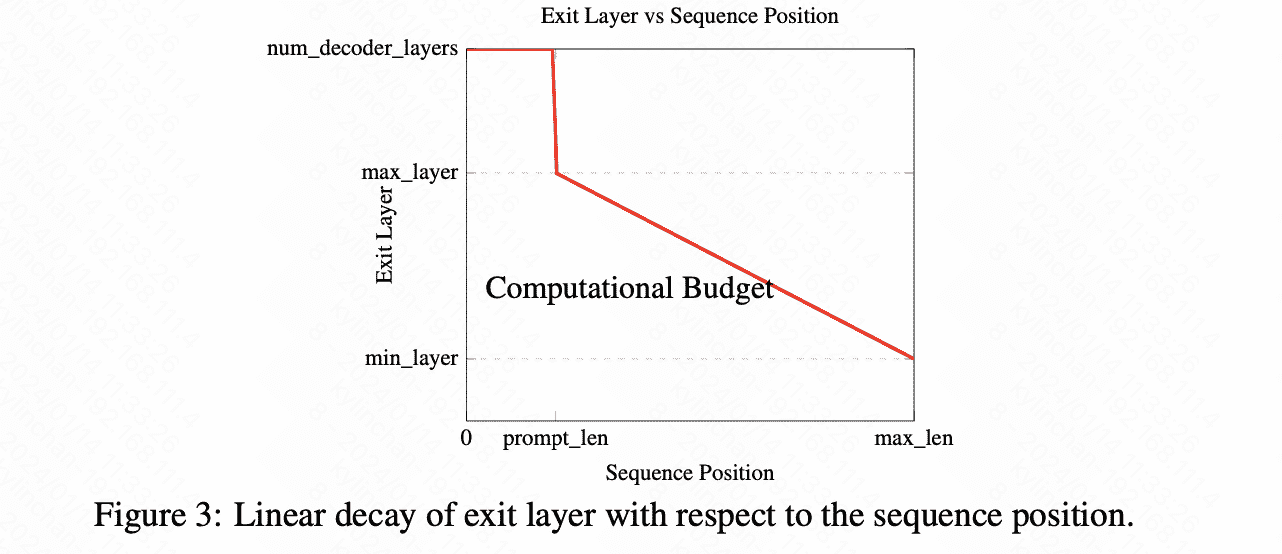
就是一个单调递减线性函数,其中最大层最小层自己指定。文中说future work可以探究一下用不同函数,比如power-law