[TOC]
基础篇
1、为什么主流LLM都是Decoder-Only的?1 (Meituan-1)
先横向比较下,再说为什么:
LLM架构主要分为三类:
Encoder-Only、Encoder-Decoder、Decoder-Only
首先纯Encoder+MLM的模型(bert)只适合做NLU,不适合做生成。
现在做Encoder-Decoder、Decoder-Only的比较:
1)decoder-Only的zero-shot效果更好,因为decoder-Only不会出现低秩问题,建模难度更大
2)in-context learning:Decoder-Only更好适应,因为其prompt会更直接作用于decoder参数
但是LLM架构问题和Language Modeling是紧密相关的,其实就是在于用什么样的mask和什么样的objective:
用non-casual modeling的模型在进行malti-task ft之后zero-shot效果是最好的。
至于为什么现在decoder-only比较火,其实有一点历史原因。
2、GPT-2参数量怎么计算?(ByteDance-1)
参考2
3、Lora原理?Lora的参数量计算?Lora参数是包含Attention还是MLP?Lora参数的初始化?为什么这样初始化?(ByteDance-1)(Damo-1)(Ele-1)
参考3
Lora为什么会起作用:低秩分解3
Armen Aghajanyan4等⼈在探究微调内在原理中提出,越⼤的模型有越小的内在维度,微调这个内在维度和在全参数空间中微调能起到相同的效果。
Lora初始化:初始化的时候,⽤随机⾼斯分布初始化A,⽤零矩阵初始化B。然后模型训练变成了更新AB的参数。
微调那一部分:Wq、Wv效果是最好的5
Lora微调参数:r秩, alpha学习率放大, dropout
4、LLM预训练参数的初始化?
1)随机初始化:均匀分布,高斯分布
2)方差缩放(保证每个神经元的输入和输出方差一致,防止梯度消失或者爆炸):Xavier初始化、Kaiming初始化
为什么不能全零初始化?或全相同值初始化?
对称失效:无论经过多少次网络训练,相同网络层内的参数值都是相同的,这会导致网络在学习时没有重点,对所有的特征处理相同,这很可能导致模型无法收敛训练失败。这种现象被称为对称失效。
5、Attention有哪几种?位置编码有哪几种?(ByteDance-2)
参考6
6、Speculative Decoding 原文是怎么执行的?正确性保证?(ByteDance-3)
参考7
7、BPE算法
8、扩充词表(ByteDance-2)
参考10
优点:提高编解码效率、提高上下文长度(因为中文的平均token表示中文字符数提高了)、提高中文能力(存疑)
步骤:
1)扩充词表: 直接sentencePiece加上就可以(要做去重)
2)Embedding初始化:
- 随机初始化
- 用原词表的均值扩充
9、ROPE、相对位置编码的好处(ByteDance-1)(Gaode-1)
参考8
10、特殊token
BERT、DistilBERT架构
- “[PAD]”:Padding Token。用于将所有句子或输入序列填充到相同的长度,以便模型能够批量处理它们。在处理不同长度的输入时,较短的输入会被这个token填充以达到批中最长序列的长度。
- “[UNK]”:Unknown Token。用于表示未知的单词或无法识别的字符。在预处理数据时,如果遇到词汇表(vocabulary)之外的单词,会用这个token替换。
- “[CLS]”:Classifier Token。在BERT及其变种中,这个token被添加到每个输入序列的开头。在句子分类或其他需要整体序列表示的任务中,”[CLS]” token的最终隐藏状态会被用作整个输入序列的聚合表示。
- “[SEP]”:Separator Token。用作分隔符,它可以分隔两个句子或标记序列的结束。在处理句子对的任务中,比如问答或句子关系模型中,”[SEP]”被用来分隔句子对。
- “[MASK]”:Masking Token。在进行遮蔽语言模型(Masked Language Model, MLM)训练时使用。某些单词会被这个token替换,模型的任务是预测原始的单词。这是BERT训练过程中的一个关键步骤,使得模型能够学习到丰富的语言表示。
RoBERTa、GPT、GPT2,BLOOM,Llama,Falcon
- “[PAD]”(Padding Token):与之前解释的相同,用于将序列填充到相同的长度,以便模型能够以批处理的方式处理它们。
- “[UNK]”(Unknown Token):也与之前相同,用于表示未知的单词或无法识别的字符,即不在模型的词汇表中的词。
- “[BOS]”(Beginning Of Sentence Token):表示句子开始的token。它在模型处理序列数据时用来标记句子的开始位置。在某些模型中,”[BOS]”被用来提示模型开始生成文本或处理一个新的输入序列。
- “[EOS]”(End Of Sentence Token):表示句子结束的token。它用于标记序列的结束,让模型知道一个句子或输入序列在哪里结束。在文本生成任务中,当模型生成了”[EOS]”token时,通常意味着完成了生成任务。
11、Bert用作分类问题细节?(Meituan-1)
参考11
12、介绍Speculative Decoding、vLLM、FlashAttention(Damo-1)
13、Pre-train和SFT的区别
参考12
数据格式:
1、preprocess_pretrain_dataset处理PreTraining阶段的数据
-
数据组成形式:
-
- 输入input:
X1 X2 X3 - 标签labels:X1 X2 X3 </s>
- 输入input:
- 典型的Decoder架构的数据训练方式;
2、preprocess_supervised_dataset处理SFT阶段的数据
-
数据组成形式:
-
- 输入input:
prompt response - 标签labels: -100 … -100 response </s>
- 输入input:
- 这里面labels的重点在于prompt部分的被-100所填充,主要作用在下面会介绍到。
Loss:
都是算cross entropy
但是SFT只计算response部分的loss
14、手写transformer
主要几个部分:MHA、FFN、Positional Embedding、Encoder&Decoder
import torch
import torch.nn as nn
import torch.nn.functional as F
import match
MHA
class MultiHeadAttention(nn.Module):
def __init__(self, embed_size, heads):
super(MultiHeadAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size//heads
assert (self.head_dim*self.heads==self.embed_size), "embed_dim need to be diveded by heads"
self.k = nn.Liner(self.head_dim, self.head_dim, bias=False)
self.q = nn.Liner(self.head_dim, self.head_dim, bias=False)
self.v = nn.Liner(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Liner(self.heads*self.head_dim, self.embed_size)
def forward(self, value, key, query, mask):
b = query.shape[0]
value_len, key_len, query_len = value.shape[1], key.shape[1], query.shape[1]
# Split the embedding into self.heads different pieces
query = query.reshape(b,query_len,self.heads,self.head_dim)
key = key.reshape(b,key,self.heads,self.head_dim)
value = value.reshape(b,value_len,self.heads,self.head_dim)
q,k,v = self.q(query),self.k(key),self.v(value)
# Einsum does matrix multiplication for query*keys for each training example
# with every other key, then scale, mask, and apply softmax
attention = torch.einsum("bqhd,bkhd->bhqk",[q,k])
if mask is not None:
attention = attention.masked_fill(mask==0,float("-1e20"))
attention = F.softmax(attention/mathsqrt(self.head_dim),dim=3)
out = torch.einsum("bhqk,bkhd->bqhd",[attention,v]).reshape(b,query_len,self.heads*self.head_dim)
out = self.fc_out(out)
return out
Transformer Block
class TransformerBlock(nn.Module):
def __init__(self,embed_size,heads,dropout,inner_dim):
super(TransformerBlock,self).__init__()
self.attention = MultiHeadAttention(embed_size,heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = nn.Sequential(
nn.Linear(embed_size,inner_dim),
nn.ReLU(),
nn.Linear(inner_dim,embed_size)
)
self.dropout = nn.Dropout(dropout)
def forward(self,v,k,q,mask):
attention = self.attention(v,k,q,mask)
# Add skip connection,followed by laver normalization
x = self.dropout(self.norm1(attention+q))
forward = self.feed_forward(x)
# Add skip connection, followed by layer normalization
out = self.dropout(self.norm1(forward+x))
return out
Positional Embedding
class PositionalEncoding(nn.Module):
def __init__(self,embed_size,max_len,device):
super(PositionalEmbedding,self).__init__()
self.encoding = torch.zeros(max_len,embed_size).to(device)
self.encoding.requires_grad = False # We do not want to update this during training
pos = torch.arange(0,max_len).unsqueeze(1).float().to(device)
_2i = torch.arange(0,embed_size,step=2).float().to(device)
self.encoding[:,0::2] = torch.sin(pos/(10000**(_2i/embed_size)))
self.encoding[:,1::2] = torch.cos(pos/(10000**(_2i/embed_size)))
def forward(self,x):
# Add positional encoding to the input embeddings
seq_len = x.shape[1]
x = x+self.encoding[:seq_len,:]
return x
Encoder
class Encoder(nn.Module):
def __init__(self,
vocal_size,
embed_size,
num_layers,
heads,
device,
inner_dim,
drop_out,
max_len):
super(Encoder,self).__init__()
self.embed_size = embed_size
self.device = device
self.embedding = nn.Embedding(vocal_size,embed_size)
self.positional_encoding = PositionalEncoding(embed_size,amx_length,device)
self.layers = nn.ModuleList([
TransformerBlock(
embed_size,
heads,
dropout = dropout,
inner_dim=inner_dim
) for _ in range(num_layers)
])
self.dropout = nn.Dropout(dropout)
def forward(self,x,mask):
out = self.dropout(self.word_embedding(x))
out = self.positional_encoding(out)
for layer in self.layers:
out = layer(out,out,out,mask)
return out
Decoder Block
class DecoderBlock(nn.Module):
def __init__(self, embed_size,heads,inner_dim,dropout,device):
super(DecoderBlock,self).__init__()
self.attention = MultiHeadAttention(embed_size,heads)
self.norm = nn.LayerNorm(embed_size)
self.transformer_block = TransformerBlock(
embed_size,heads,dropout,inner_dim
)
self.dropout = nn.Dropout(dropout)
def forward(self,x,value,key,src_mask,trg_mask):
attention = self.atrtention(x,x,x,trg_mask)
query = self.dropout(self.norm(attention+x))
out = self.transformer_block(value,key,query,src_mask)
return out
Decoder
class Decoder(nn.Module):
def __init__(self,
vocal_size,
embed_size,
num_layers,
heads,
device,
inner_dim,
drop_out,
max_len):
super(Decoder,self).__init__()
self.device = device
self.embedding = nn.Embedding(vocal_size,embed_size)
self.positional_encoding = PositionalEncoding(embed_size,amx_length,device)
self.layers = nn.ModuleList([
DecoderBlock(
embed_size,
heads,
dropout = dropout,
inner_dim=inner_dim
) for _ in range(num_layers)
])
self.dropout = nn.Dropout(dropout)
self.fc_out = nn.Linear(embed_size,vocal_size)
def forward(self,x,enc_out,src_mask,trg_mask):
x = self.dropout(self.word_embedding(x))
x = self.positional_encoding(x)
for layer in self.layers:
x = layer(x,enc_out,enc_out,src_mask,trg_mask)
out = self.fc_out(x)
return out
Transformer
class Transformer(nn.Module):
def __init__(self,
src_vocab_size,
trg_vocab_size,
src_pad_idx,
trg_pad_idx,
embed_size=256,
num_1ayers=6,
inner_dim=1024,
heads=8,
dropout=0,
device="cuda",
max_length=100):
super(Transformer, self).__init_()
self.encoder = Encoder(
src_vocab_size,
embed_size,
num_layers,
heads,
device,
inner_dim,
dropout,
max_1ength
)
self.decoder = Decoder(
trg_vocab_size,
embed _size,
num_1ayers,
heads,
forward_expansion,
dropout,
device,
max_length
)
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
self.device = device
def make_src_mask(self,src):
src_mask = (src!=self.src_pad_idx).unsqueeze(1).unsqueeze(2)
return src_mask.to(self.device)
def make_trg mask(self, trg):
N, trg_len = trg.shape
trg_mask = torch.tril(torch.ones((trg_len, trg_len))).expand(
N, 1, trg_len, trg_len
)
return trg_mask.to(self.device)
def forward(self, src, trg):
src_mask = self.make_src_mask(src)
trg_mask = self.make_trg_mask(trg)
enc_src = self.encoder(src, src_mask)
out = self.decoder(trg, enc_src, src_mask, trg_mask)
return out
Test
# Initialize a transformer
modeldevice = torch.device("cuda" if torch.cuda. is_available() else "cpu")
src_vocab_size = 10000
trg_vocab_size = 10000
src_pad_idx = 0
trg_pad_idx =0
model = Transformer(src_vocab_size, trg_vocab_size, src_pad_idx, trg_pad_idx) .to(device)
# prepare some sample data (batch size = 1, sequence length = 10)
src = torch.tensor([[1, 5, 6, 2, 0, 0, 0, 0, 0, 0]], device=device)
trg = torch.tensor([[1, 7, 4, 3, 2, 0, 0, 0, 0, 0]], device=device)
# perform a forward pass
out = model(src, trg[:, :-1])
print(out.shape) # Expected shape: (batch_size, trg_seg_length - 1, trg vocab_ size)
14、DeepSpeed Zero三个阶段?(Ant-1)
DeepSpeed Basic
- ZeRO优化器:ZeRO(Zero Redundancy Optimizer)是DeepSpeed中的关键组件之一,它通过优化模型状态的存储和通信来大幅减少所需的内存占用,使得可以在有限的资源下训练更大的模型。
- 分片参数:ZeRO通过对参数、梯度和优化器状态进行分片,将它们平均分配到所有的GPU中,这样每个GPU只存储一部分数据,从而减少了单个设备的内存需求。
ZeRO-1、ZeRO-2和ZeRO-3的区别
ZeRO分为三个优化级别:ZeRO-1、ZeRO-2和ZeRO-3,每个级别都在前一个级别的基础上进一步减少内存占用。
15、 prenorm / postnorm区别(Ele-1)
前比较明确的结论是:同一设置之下,Pre Norm结构往往更容易训练,但最终效果通常不如Post Norm13。(迁移性能,就是sft之后在下游的性能)
Pre Norm: $\quad \boldsymbol{x}{t+1}=\boldsymbol{x}_t+F_t\left(\operatorname{Norm}\left(\boldsymbol{x}_t\right)\right)$ Post Norm: $\quad \boldsymbol{x}{t+1}=\operatorname{Norm}\left(\boldsymbol{x}_t+F_t\left(\boldsymbol{x}_t\right)\right)$
简单来说,就是prenorm有退化,在transfomer layers比较多的情况下,其等效于宽网络,造成退化。postnorm削弱了恒等分支(残差连接),因为postnorm是在residual之后norm的,所以训练任务更难,但是也更不容易收敛。
16、量化(感知训练、后训练)/ 稀疏化(Ele-1)
17、外推能力?(Ele-1)
18、Pretrain方法(Ele-1)
19、为什么训练时候Transformer的Decoder生成不是从bos开始的?
在Transformer模型中,使用encoder-decoder结构时,目标序列(trg)的输入确实具有初始长度。这是因为在训练过程中,Transformer模型采用了一种称为“教师强制”(Teacher Forcing)的技术。让我来解释一下这个过程和它背后的原因:
教师强制(Teacher Forcing)
- 目的:教师强制技术的目的是加速和稳定训练过程。通过直接提供真实的目标序列(或其部分)给解码器,模型可以更有效地学习如何预测下一个正确的输出。
- 过程:在训练阶段,解码器在每个时间步接收到的输入是前一个时间步的真实输出,而不是模型的预测输出。这样做可以防止训练过程中的错误累积,并帮助模型更快地学习到准确的输出序列。
- 序列长度:你提到的
trg序列有初始长度的原因是,我们在训练时已经知道目标序列的完整内容。因此,可以将整个或部分正确的目标序列作为输入提供给解码器,以指导其预测过程。这是与生成任务不同的地方,在生成任务中,我们确实是从零开始,逐步生成整个序列。
解码阶段的生成
在实际的解码或推理阶段,当我们希望模型生成新的序列时,是从一个初始令牌(如起始令牌)开始,然后基于模型当前的输出来决定下一个输入令牌,直到序列生成完成(例如,直到模型输出一个结束令牌)。这个过程与训练时使用的教师强制有所不同,因为它依赖于模型自身的预测来逐步构建输出序列。
20、Batch Norm/Layer Norm
原文极好16
手撕layernorm(幻方)
import torch
import torch.nn as nn
class LayerNorm(nn.Module):
"""Layer Normalization class"""
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.gamma = nn.Parameter(torch.ones(features))
self.beta = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True, unbiased=False)
return self.gamma * (x - mean) / (std + self.eps) + self.beta
# Example usage
features = 768 # Typical BERT hidden size
layer_norm = LayerNorm(features)
# Dummy input tensor (batch_size, seq_length, features)
x = torch.randn(10, 20, features)
normalized_x = layer_norm(x)
print(normalized_x)
21、为什么transformer成为主流方案?是否有替代方案?(Damo-2)
- 从AI上来说,行之有效的架构:
attention + mlp (memory network);
一些研究文章认为它优化上等同SVM,原理上等同GNN,并行度上优于RNN
- 从system上来说,架构适用于GPU计算,并行训练是十分高效的
- 训练范式上是自监督,无需数据标注,大规模预训练与scaling law
替代方案17
Transformer 的不可能三角
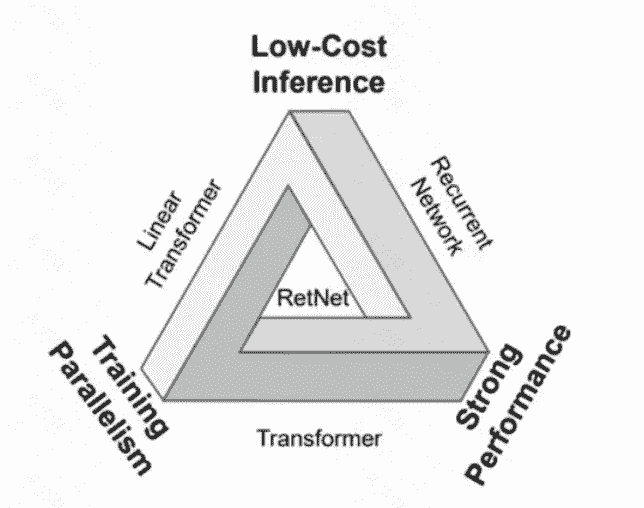
RWKV:节约内存和计算
RetNet:并行计算循环推理
Mamba:
22、transfomer的K、Q、V可以使用同一个值吗?
参考18
K和Q的点乘是为了得到一个attention score 矩阵,用来对V进行提纯。K和Q使用了不同的W_k, W_q来计算,可以理解为是在不同空间上的投影。正因为有了这种不同空间的投影,增加了表达能力,这样计算得到的attention score矩阵的泛化能力更高。这里解释下我理解的泛化能力,因为K和Q使用了不同的W_k, W_Q来计算,得到的也是两个完全不同的矩阵,所以表达能力更强。
但是如果不用Q,直接拿K和K点乘的话,你会发现 attention score 矩阵是一个对称矩阵。因为是同样一个矩阵,都投影到了同样一个空间,所以泛化能力很差。
attention score不需要是对称的原因:词和词的修饰不是对称的,比如“我是一个男孩”这句话,男孩对修饰我的重要性应该要高于我修饰男孩的重要性。
23、手写attention(numpy的两种写法)
- np.matmul
def softmax(x):
e_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return e_x / e_x.sum(axis=-1, keepdims=True)
def user_multi_head_attention_forward(query, key, value, embd_dim, num_heads, in_proj_weight, out_proj_weight):
w_q,w_k,w_v = in_proj_weight[:embd_dim,:],in_proj_weight[embd_dim:2*embd_dim,:],in_proj_weight[2*embd_dim:,:]
q = np.matmul(query, w_q)
k = np.matmul(key, w_k)
v = np.matmul(value, w_v)
batch_size, seq_length, embed_dim = q.shape
head_dim = embed_dim // num_heads
q = q.reshape(batch_size, seq_length, num_heads, head_dim)
k = k.reshape(batch_size, seq_length, num_heads, head_dim)
v = v.reshape(batch_size, seq_length, num_heads, head_dim)
# Using np.einsum to compute the scores
scores = np.einsum('bqhd,bkhd->bhqk', q, k) / np.sqrt(head_dim)
weights = softmax(scores)
# Using np.einsum to compute the weighted sum of values
att_output = np.einsum('bhqk,bkhd->bqhd', weights, v).reshape(batch_size, seq_length, embed_dim)
output = np.matmul(att_output, out_proj_weight)
return output
- np.einsum
def softmax(x):
e_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return e_x / e_x.sum(axis=-1, keepdims=True)
def user_multi_head_attention_forward(query, key, value, embd_dim, num_heads, in_proj_weight, out_proj_weight):
w_q,w_k,w_v = in_proj_weight[:embd_dim,:],in_proj_weight[embd_dim:2*embd_dim,:],in_proj_weight[2*embd_dim:,:]
q = np.matmul(query, w_q)
k = np.matmul(key, w_k)
v = np.matmul(value, w_v)
batch_size, seq_length, embed_dim = q.shape
head_dim = embed_dim // num_heads
q = q.reshape(batch_size, seq_length, num_heads, head_dim).transpose(0, 2, 1, 3)
k = k.reshape(batch_size, seq_length, num_heads, head_dim).transpose(0, 2, 3, 1)
v = v.reshape(batch_size, seq_length, num_heads, head_dim).transpose(0, 2, 1, 3)
scores = np.matmul(q, k) / np.sqrt(head_dim)
weights = softmax(scores)
att_output = np.matmul(weights, v).transpose(0, 2, 1, 3).reshape(batch_size, seq_length, embed_dim)
output = np.matmul(att_output, out_proj_weight)
return output
- 测试脚本
import numpy as np
from typing import Callable
import torch
batch_size, seq_len, embd_dim, num_heads = [int(_) for _ in input().split()]
np.random.seed(batch_size + seq_len + embd_dim + num_heads)
query = np.random.randn(batch_size, seq_len, embd_dim).astype(np.float32)
key = np.random.randn(batch_size, seq_len, embd_dim).astype(np.float32)
value = np.random.randn(batch_size, seq_len, embd_dim).astype(np.float32)
def softmax(x):
e_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return e_x / e_x.sum(axis=-1, keepdims=True)
def user_multi_head_attention_forward(query, key, value, embd_dim, num_heads, in_proj_weight, out_proj_weight):
w_q,w_k,w_v = in_proj_weight[:embd_dim,:],in_proj_weight[embd_dim:2*embd_dim,:],in_proj_weight[2*embd_dim:,:]
q = np.matmul(query, w_q)
k = np.matmul(key, w_k)
v = np.matmul(value, w_v)
batch_size, seq_length, embed_dim = q.shape
head_dim = embed_dim // num_heads
q = q.reshape(batch_size, seq_length, num_heads, head_dim)
k = k.reshape(batch_size, seq_length, num_heads, head_dim)
v = v.reshape(batch_size, seq_length, num_heads, head_dim)
# Using np.einsum to compute the scores
scores = np.einsum('bqhd,bkhd->bhqk', q, k) / np.sqrt(head_dim)
weights = softmax(scores)
# Using np.einsum to compute the weighted sum of values
att_output = np.einsum('bhqk,bkhd->bqhd', weights, v).reshape(batch_size, seq_length, embed_dim)
output = np.matmul(att_output, out_proj_weight)
return output
# 以下为测试代码
def xavier_uniform_(tensor, gain=1.): # 方阵的 xavier 初始化
a = gain * np.sqrt(3 / tensor.shape[0])
res = np.random.uniform(low=-a, high=a, size=tensor.shape)
return (res + res.T) / 2 # 把矩阵变成对称的,不用考虑实现时要不要转置
def test_multi_head_attention_forward(mha_impl_func: Callable, in_proj_weight: np.ndarray, out_proj_weight: np.ndarray):
# Run mha
user_impl_out = mha_impl_func(query, key, value, embd_dim, num_heads,
in_proj_weight, out_proj_weight)
import torch
import torch.nn as nn
# 可以和 torch 的实现做对比
mha = nn.MultiheadAttention(embd_dim, num_heads, bias=False, dropout=0)
with torch.no_grad():
mha.in_proj_weight.copy_(torch.from_numpy(in_proj_weight))
mha.out_proj.weight.copy_(torch.from_numpy(out_proj_weight))
mha_out, _ = mha(torch.from_numpy(query).transpose(0, 1), torch.from_numpy(key).transpose(0, 1),
torch.from_numpy(value).transpose(0, 1))
mha_out = mha_out.transpose(0, 1).numpy()
assert np.allclose(user_impl_out, mha_out, atol=1e-6), "Outputs do not match!"
weights = [xavier_uniform_(np.random.randn(embd_dim, embd_dim)).astype(np.float32) for _ in range(4)]
in_proj_weight = np.concatenate(weights[:3], axis=0)
out_proj_weight = weights[-1]
# 为方便调试,你可以用下面这个测试函数在本地验证自己实现的 user_multi_head_attention_forward() 的正确性。
# 但在提交代码到系统时务必注释掉这行代码,否则会因为找不到 torch 模块而报错。
# test_multi_head_attention_forward(user_multi_head_attention_forward, in_proj_weight, out_proj_weight)
result = user_multi_head_attention_forward(query, key, value, embd_dim, num_heads, in_proj_weight, out_proj_weight)
print(f'{int(np.linalg.norm(result.ravel()) * 100_000)}') # 把结果摊平成一维数组,求范数然后保留 5 位小数
多模态篇
1、为什么MLLM普遍都是2阶段训练,而不是1阶段?(ByteDance-1)
主要是从数据上来考虑,pretrain阶段的数据是多样的,而instructionTuning阶段的数据只是特定任务的(i.e., 评论生成)
2、为什么不将ViT加入到MLLM训练过程中?ViT的参数量以及显存占用量?(ByteDance-1)
ViT是通过CLIP进行对比学习得到的,有跨模态理解能力和zero-shot的能力。
3、几种MLLM的架构极其特点?优势?(ByteDance-1)
参考19
4、clip细节:数据怎么构造、怎么训练、怎么设计loss(Gaode-1)
参考20
Reference
-
Mainstream architecture of LLMs https://kylinchen.cn/2023/12/04/whichLLM/ ↩
-
GPT2参数量准确计算. https://kylinchen.cn/2024/01/22/LLMcompute/ ↩
-
⾼效参数微调PEFT――LORA. https://zhuanlan.zhihu.com/p/665407489?utm_id=0 ↩ ↩2
-
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning https://arxiv.org/abs/2012.13255 ↩
-
LoRA: Low-Rank Adaptation of Large Language Models https://arxiv.org/abs/2106.09685 ↩
-
各种位置编码. https://blog.csdn.net/weixin_41862755/article/details/134289843 ↩
-
Speculative Decoding 的 Sampling 误解浅析. https://kylinchen.cn/2024/02/28/SpeculativeDecoding/ ↩
-
Transformer中的位置编码(Position Encoding). https://0809zheng.github.io/2022/07/01/posencode.html ↩ ↩2
-
LLM大语言模型之Tokenization分词方法(WordPiece,Byte-Pair Encoding (BPE),Byte-level BPE(BBPE)原理及其代码实现). https://zhuanlan.zhihu.com/p/652520262 ↩
-
LLM大模型之基于SentencePiece扩充LLaMa中文词表实践. https://zhuanlan.zhihu.com/p/655281268 ↩
-
pytorch bert源码. https://github.com/hichenway/CodeShare/blob/master/bert_pytorch_source_code/modeling.py ↩
-
剖析大模型Pretrain和SFT阶段的Loss差异. https://zhuanlan.zhihu.com/p/652657011 ↩
-
为什么Pre Norm的效果不如Post Norm?https://kexue.fm/archives/9009 ↩
-
BERT用的LayerNorm可能不是你认为的那个Layer Norm?https://cloud.tencent.com/developer/article/2159390 ↩
-
https://pytorch.org/docs/stable/generated/torch.nn.LayerNorm.html#torch.nn.LayerNorm ↩
-
https://stackoverflow.com/questions/70065235/understanding-torch-nn-layernorm-in-nlp ↩
-
LLM(廿四):Transformer 的结构改进与替代方案. https://zhuanlan.zhihu.com/p/673781418 ↩
-
Transformer中K 、Q、V的设置以及为什么不能使用同一个值. https://www.cnblogs.com/jins-note/p/14508523.html ↩
-
MLLM 经典结构详解. https://kylinchen.cn/2024/01/22/MultiModalLLMStructure/ ↩
-
CodeReview for CLIP. https://kylinchen.cn/2024/03/11/CLIP/ ↩