[TOC]
Flamingo1
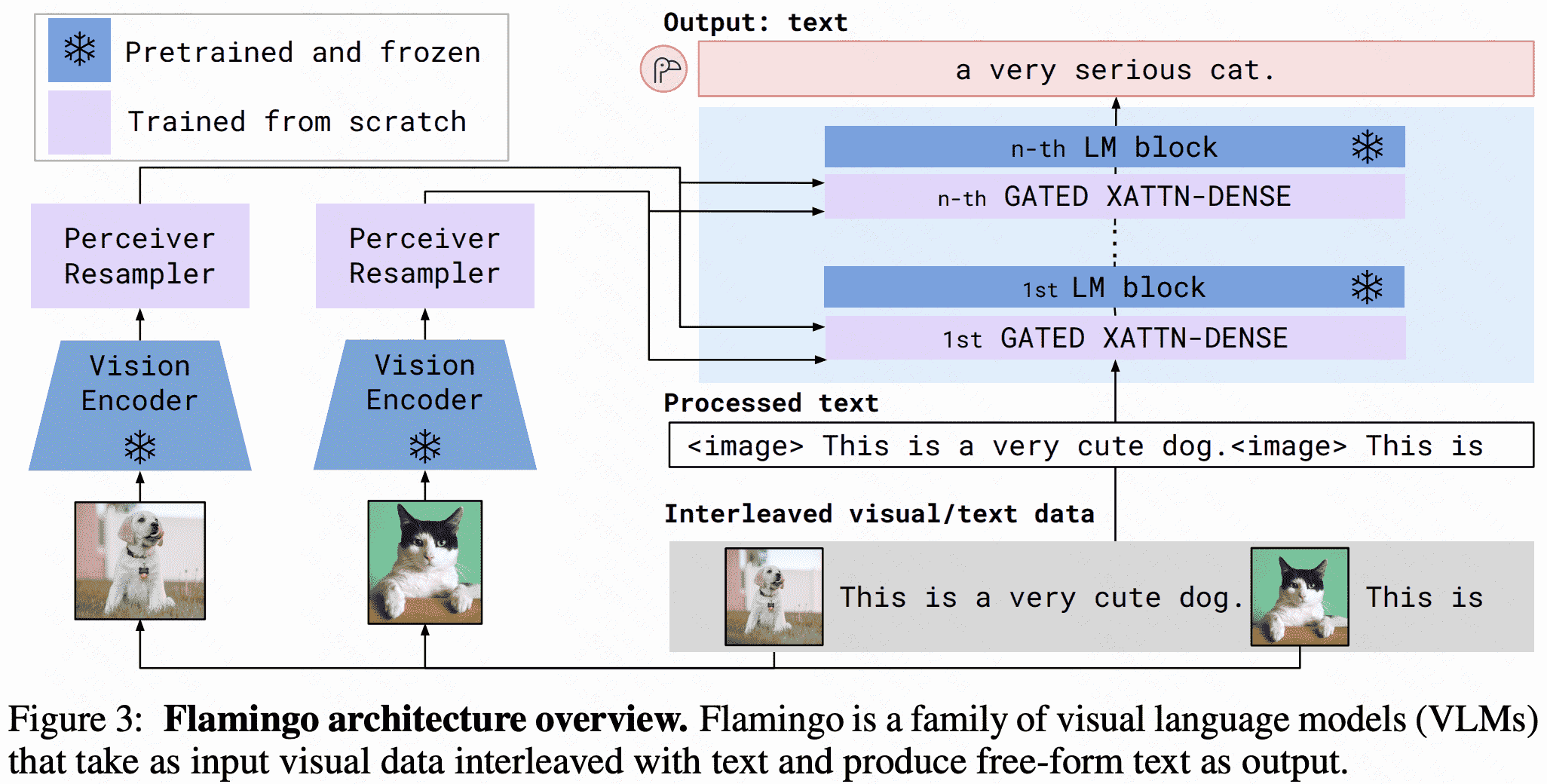
主要两个结构:
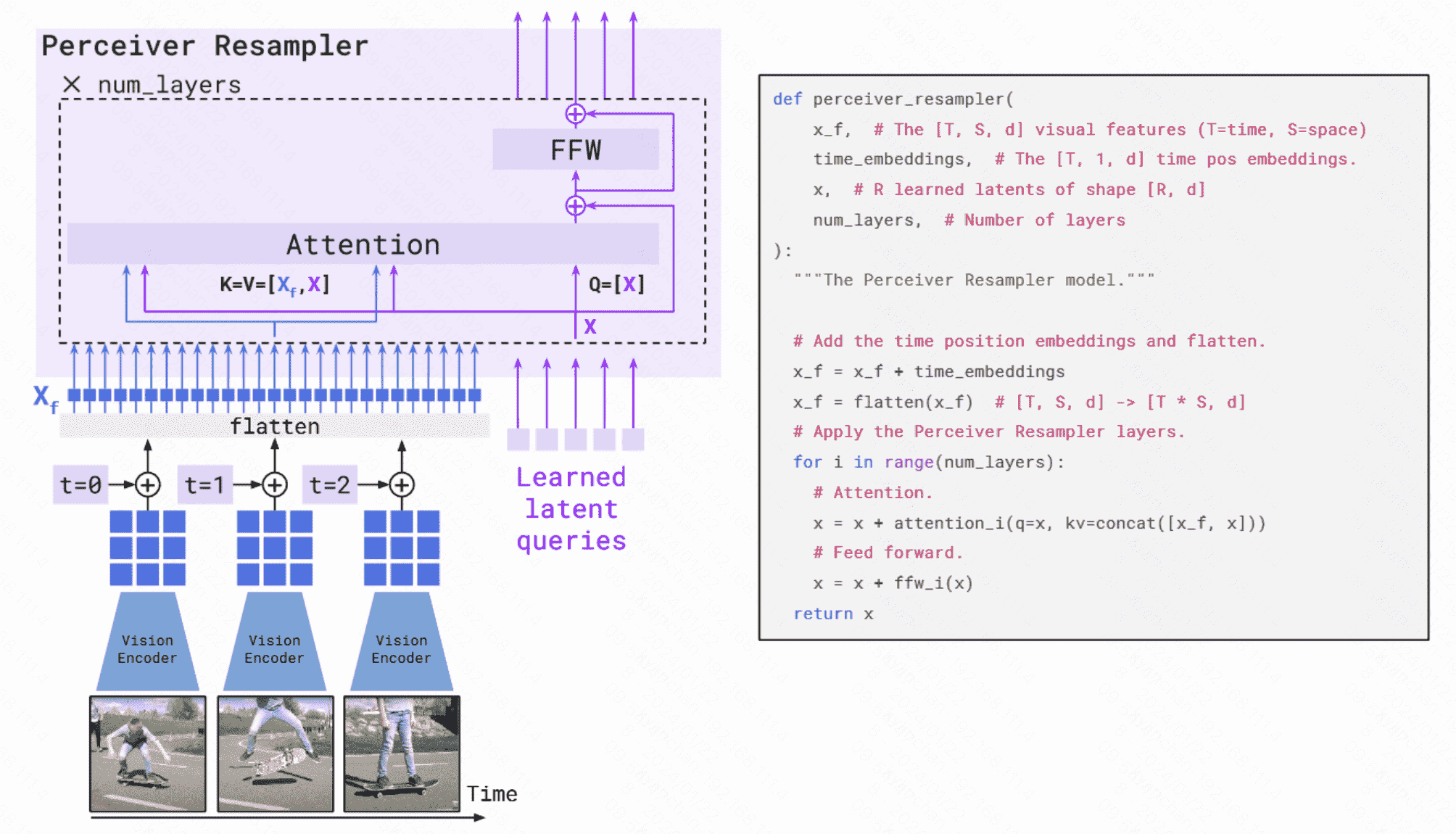
- perceiver resampler:类似DETR,通过设计多个Perceiver Resampler来生成64个固定长度的tokens,主要作用在于可以从图像中提取固定长度的特征向量,能够解决图像甚至多帧视频的feature map不一致的问题。
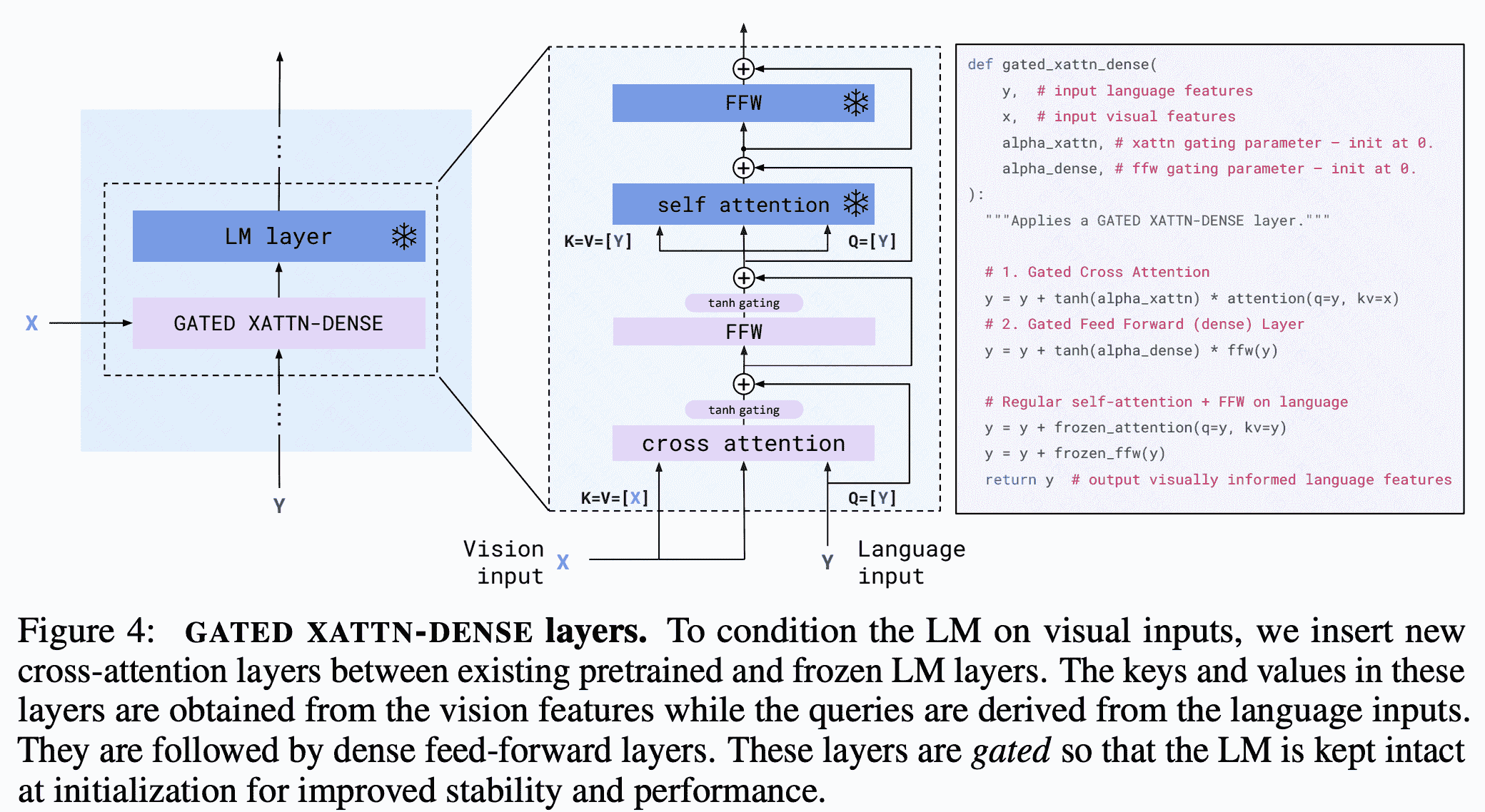
- XAttn-Dense:在每一层LLM上都会增加corss- attention以入到LLM中与视觉向量进行交互,融合多模态信息。
BLIP
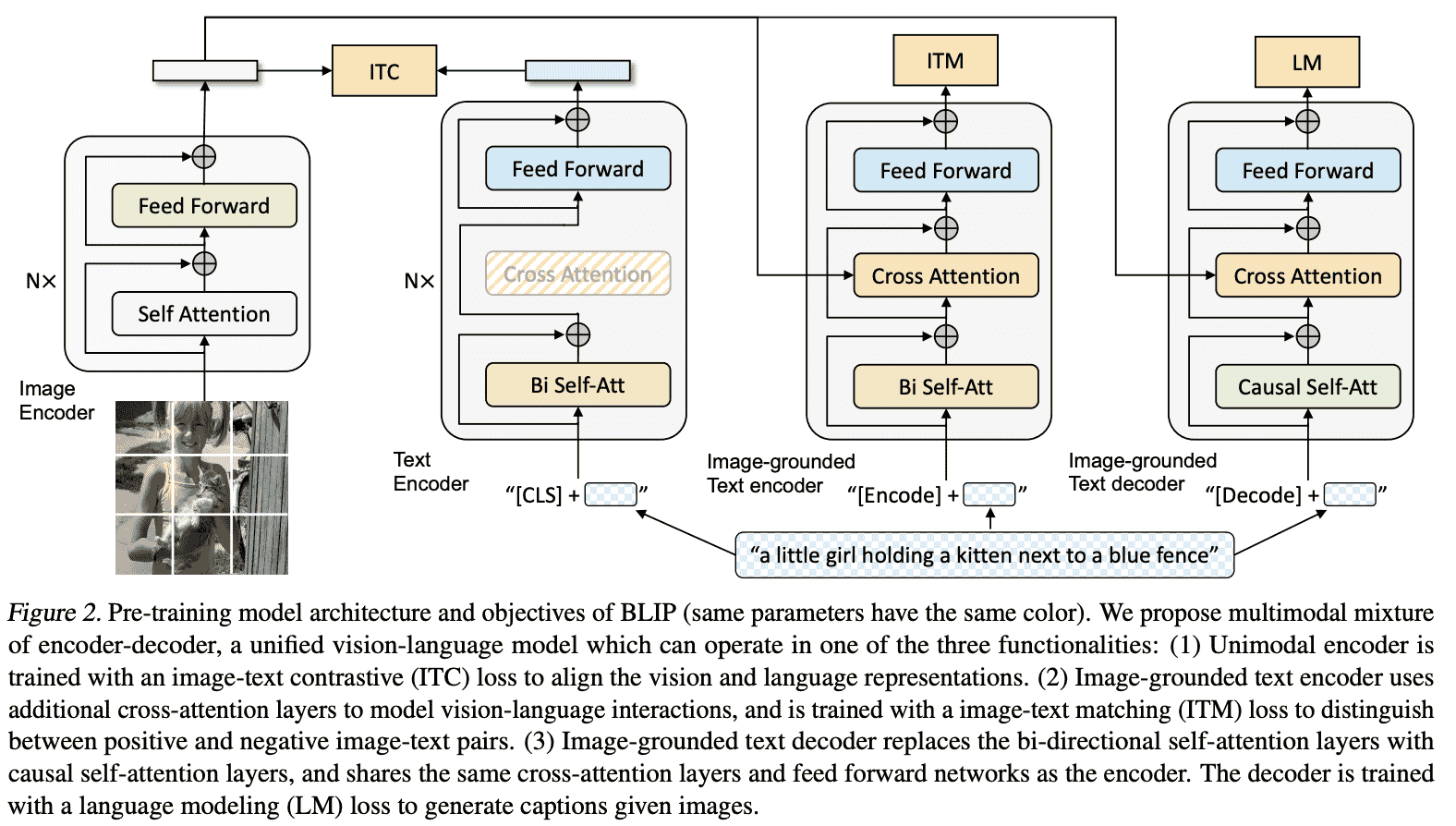
BLIP的主要特点是结合了encoder和decoder,即形成了统一理解和生成(Understanding&Generation)的多模态模型。统一的动机在于encoder模型如CLIP没有生成器无法做VQA等生成任务,而如果用encoder-decoder框架无法做retrieval任务。因此BLIP很大的贡献在于MED(mixture of encoder-decoder)模块。从而使该模型既可以有理解能力(encoder),又可以有生成能力(decoder)。
BLIP-223
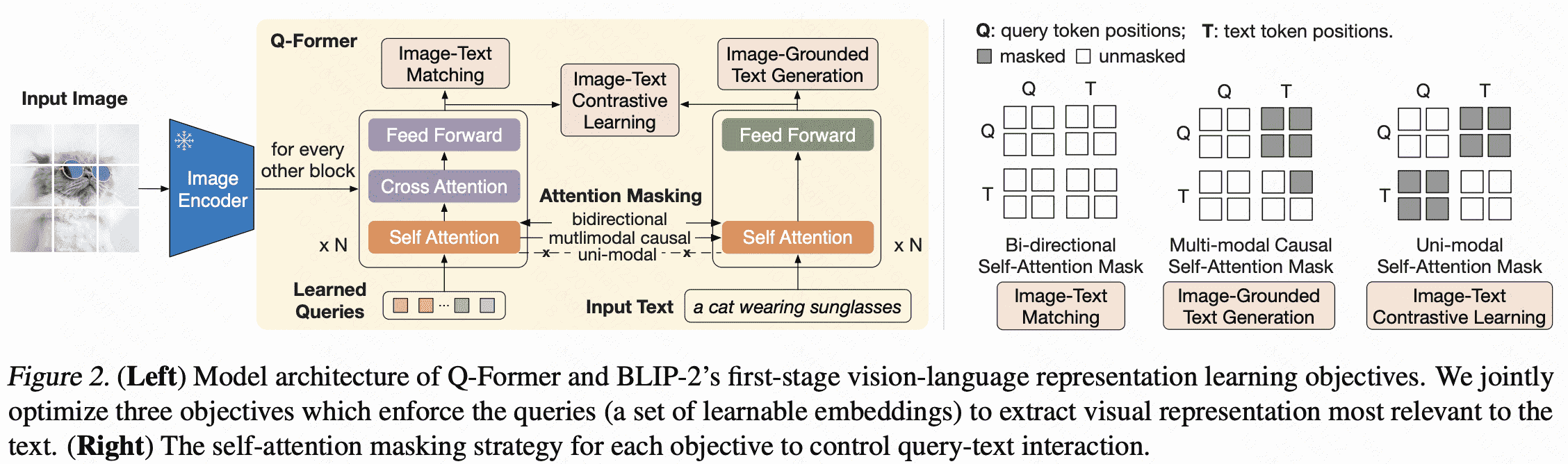
而BLIP-2和Flamingo一样,用一个Qformer来提取图像特征(等同与Flamingo的perceiver resampler),然后用cross- attention进行多模态交互,此时视觉编码器和LLM都会被冻结,只训练Qformer,而在下游任务微调时,可以再解锁视觉编码器,让它跟Qformer一起训练,如下图所示。
因此BLIP-2设计了两阶段的训练策略,以使视觉编码器能学会提取更关键的信息。
第一阶段:使用多种预训练任务,如Image-Text Contrastive Learning,Image-grounded Text Generation,Image-Text Matching让Qformer学会如何从视觉编码器中抽取文本相关的特征。 第二阶段,将Qformer插入到LLMs中,用language modeling进行训练。 BLIP2的训练数据包括MSCOCO,Visual Genome,CC15M,SBU,115M来自于LAION400M的图片以及BLIP在web images上生成的描述。不过BLIP-2没有使用Flamingo那种图文交错的数据,因此它没有太强的in-context learning能力。
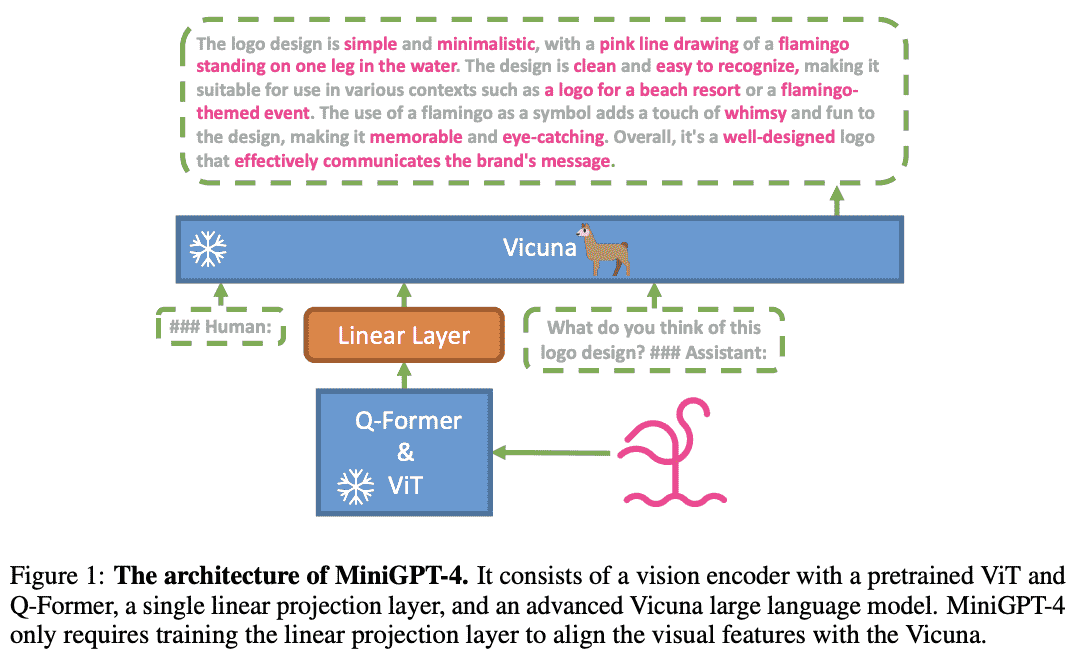
MiniGPT-44
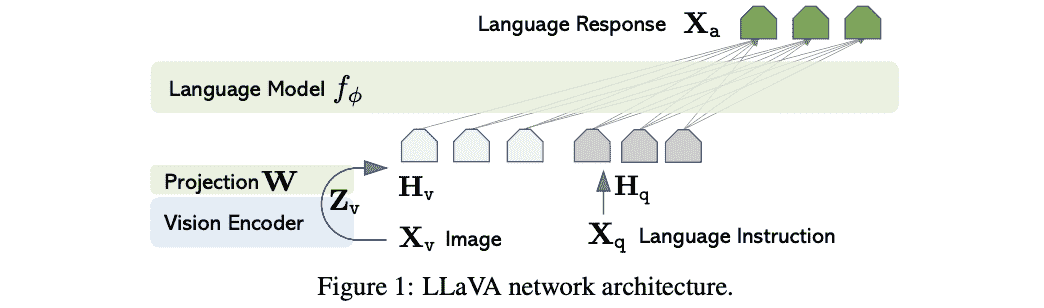
LLaVA5
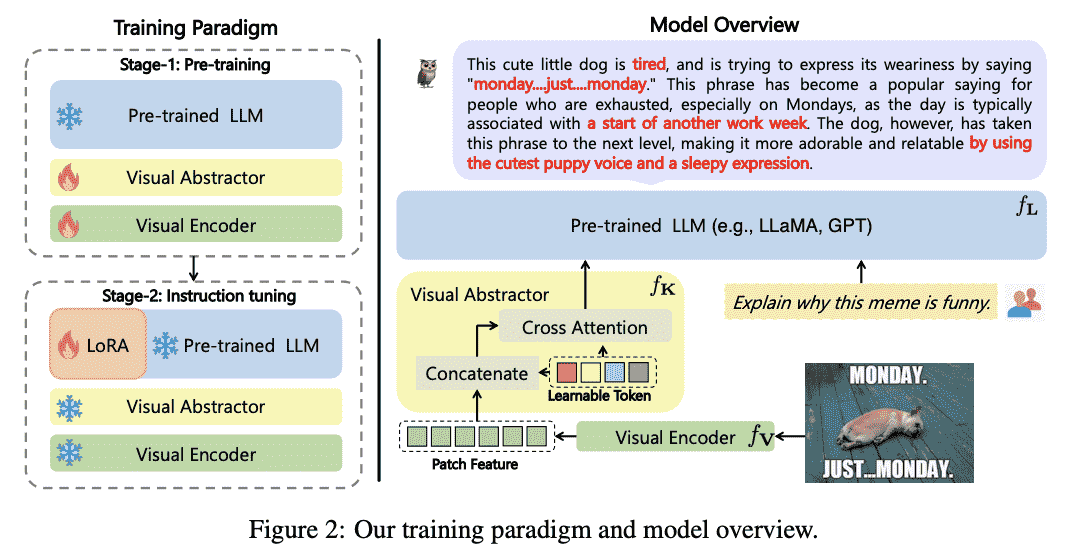
mPLUG-Owl6
code-review
| lora用于q_proj | v_proj,算了一下,参数量2M |
Reference
-
Alayrac, Jean-Baptiste, et al. “Flamingo: a visual language model for few-shot learning.” Advances in Neural Information Processing Systems 35 (2022): 23716-23736. ↩
-
Li, Junnan, et al. “Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models.” arXiv preprint arXiv:2301.12597 (2023). ↩
-
BLIP2中Q-former详解. https://blog.csdn.net/m0_37708614/article/details/134122314 ↩
-
Zhu, Deyao, et al. “Minigpt-4: Enhancing vision-language understanding with advanced large language models.” arXiv preprint arXiv:2304.10592 (2023). ↩
-
Liu, Haotian, et al. “Visual instruction tuning.” arXiv preprint arXiv:2304.08485 (2023). ↩
-
Ye, Qinghao, et al. “mplug-owl: Modularization empowers large language models with multimodality.” arXiv preprint arXiv:2304.14178 (2023). ↩