[TOC]
Speculative Decoding12 初探
按照Huggingface公众号3、以及Tianqi Chen4 的综述,会产生一个误解:Speculative Decoding就是小模型Inference一次,大模型Verifying一次,并在最后一个不一致Token位置,用大模型的答案进行修正。

但是仔细看了原论文之后,发现原论文的思想和上面不太一样。上面的说法只是在使用greedy解码时候的特殊情况,但是考虑到解码会使用到sampling算法,所以原论文12是从sampling角度去解决一个问题:如何实现在第一个reject位置采样得到正确Token的概率与groundtruth模型(较大模型)采样概率无偏。
并且实际上,原论文并没有对较大模型的logits进行采样!
Speculative Decoding Sampling
Deepmind版伪代码如下:

主要步骤:
(1)小模型自回归;(2)大模型forward验证

(3)Sampling:
- case 1: if q(x)>=p(x), accept.
- case 2: if q(x)<p(x):
- accept with probability q(x)/p(x)
- Reject and resample from norm(max(0,q(x)-p(x)))

值得注意的是,如果全部tokens都accept了,那么直接从q(x)进行采样
为什么从 (q(x)-p(x))+ 重采样5?
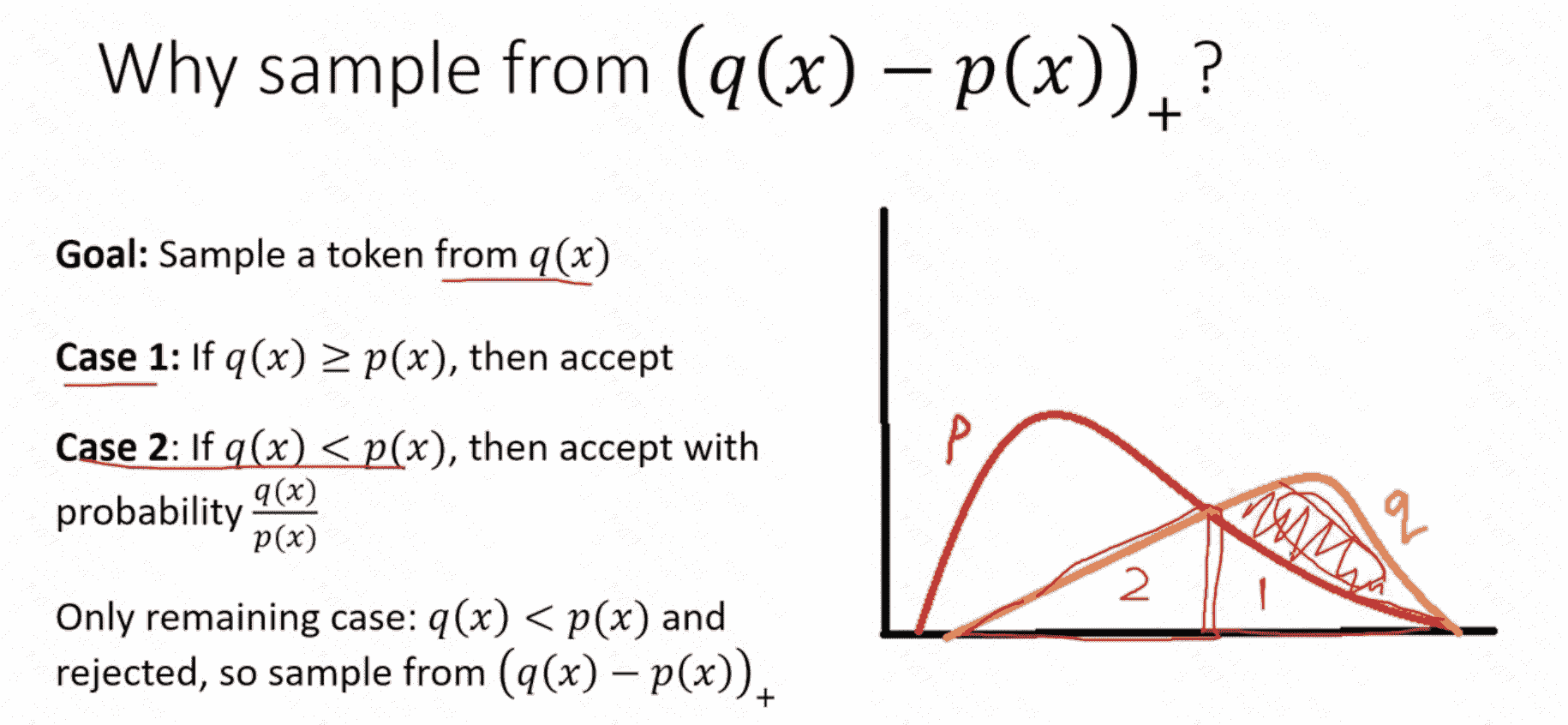
始终记得,我们的目标就是要补全q分布。这个概率分布图中,可以看到2区域被reject之后,要补全全部q分布,需要的那一部分就是(q(x)-p(x))+
Reference
-
Leviathan, Yaniv, Matan Kalman, and Yossi Matias. “Fast inference from transformers via speculative decoding.” International Conference on Machine Learning. PMLR, 2023. ↩ ↩2
-
Chen, Charlie, et al. “Accelerating large language model decoding with speculative sampling.” arXiv preprint arXiv:2302.01318 (2023). ↩ ↩2
-
使用推测解码 (Speculative Decoding) 使 Whisper 实现 2 倍的推理加速 https://mp.weixin.qq.com/s/JIAmnPO8gZFcwu5dW-oFdw ↩
-
Miao, Xupeng, et al. “Towards efficient generative large language model serving: A survey from algorithms to systems.” arXiv preprint arXiv:2312.15234 (2023). ↩
-
Speculative Decoding: When Two LLMs are Faster than One https://www.youtube.com/watch?v=S-8yr_RibJ4 ↩