[TOC]
InternLM-XComposer2
- ViT和LLM的连接部分
self.vit = build_vision_tower() # 其实就是ViT,但是处理的权重的pos_emb,能适应不同尺寸图片
self.vision_proj = build_vision_projector()
其实就是用三个线性层进行映射:
def build_vision_projector():
projector_type = 'mlp2x_gelu'
mm_hidden_size = 1024
hidden_size = 4096
mlp_gelu_match = re.match(r'^mlp(\d+)x_gelu$', projector_type)
if mlp_gelu_match:
mlp_depth = int(mlp_gelu_match.group(1))
modules = [nn.Linear(mm_hidden_size, hidden_size)]
for _ in range(1, mlp_depth):
modules.append(nn.GELU())
modules.append(nn.Linear(hidden_size, hidden_size))
return nn.Sequential(*modules)
if projector_type == 'identity':
return IdentityMap()
raise ValueError(f'Unknown projector type: {projector_type}')
- InternLM2 (专门为xcomposer魔改版)
1)Attention模块之间用PLoRA代替了线性层(atten_c,atten_o),其中包含了Plora和一个原本的线性层
class InternLM2Attention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper."""
def __init__(self, config: InternLM2Config):
......
self.wqkv = PLoRA(
self.hidden_size,
(self.num_heads + 2 * self.num_key_value_heads) * self.head_dim,
bias=config.bias,
lora_r=256,
lora_alpha=256,
lora_len=576)
self.wo = PLoRA(
self.num_heads * self.head_dim,
self.hidden_size,
bias=config.bias,
lora_r=256,
lora_alpha=256,
lora_len=576)
2)这个FFN也是用Plora实现的:
class InternLM2MLP(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.intermediate_size = config.intermediate_size
self.w1 = PLoRA(
self.hidden_size,
self.intermediate_size,
bias=False,
lora_r=256,
lora_alpha=256,
lora_len=576)
self.w3 = PLoRA(
self.hidden_size,
self.intermediate_size,
bias=False,
lora_r=256,
lora_alpha=256,
lora_len=576)
self.w2 = PLoRA(
self.intermediate_size,
self.hidden_size,
bias=False,
lora_r=256,
lora_alpha=256,
lora_len=576)
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x, im_mask):
down_proj = self.w2(
self.act_fn(self.w1(x, im_mask)) * self.w3(x, im_mask), im_mask)
return down_proj
- PLora:vision embedding 和 text embedding 分别处理

公式是这样写的,很清晰:
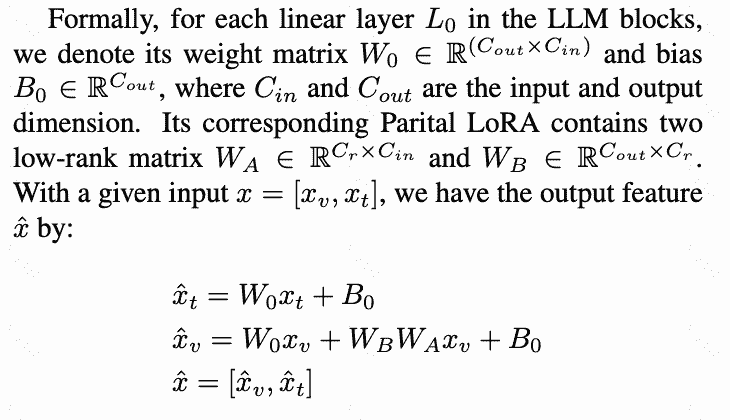

PLora的forward代码是这样写的(先降采样再升采样):
super().__init__(in_features, out_features, bias, device, dtype)
......
self.Plora_A = nn.Linear(
in_features, self.lora_r, bias=False, device=device, dtype=dtype)
self.Plora_B = nn.Linear(
self.lora_r, out_features, bias=False, device=device, dtype=dtype)
......
def forward(self, x, im_mask=None):
res = super().forward(x)
if im_mask is not None:
if torch.sum(im_mask) > 0:
part_x = x[im_mask]
res[im_mask] += self.Plora_B(
self.Plora_A(
self.lora_dropout(part_x))) * self.lora_scaling
else:
part_x = x[:, :1]
res[:, :1] += self.Plora_B(
self.Plora_A(self.lora_dropout(part_x))) * 0
return res
Advances:主要是自监督了视觉信号,这在传统的MLLM中不常见
Training
Pretraining
During the pre-training phase, the LLM remains constant while both the vision encoder and Partial LoRA are fine- tuned to align the visual tokens with the LLM.
SFT
During this stage, we jointly fine- tune the vision encoder, LLM, and Partial LoRA.