[TOC]
CLIP
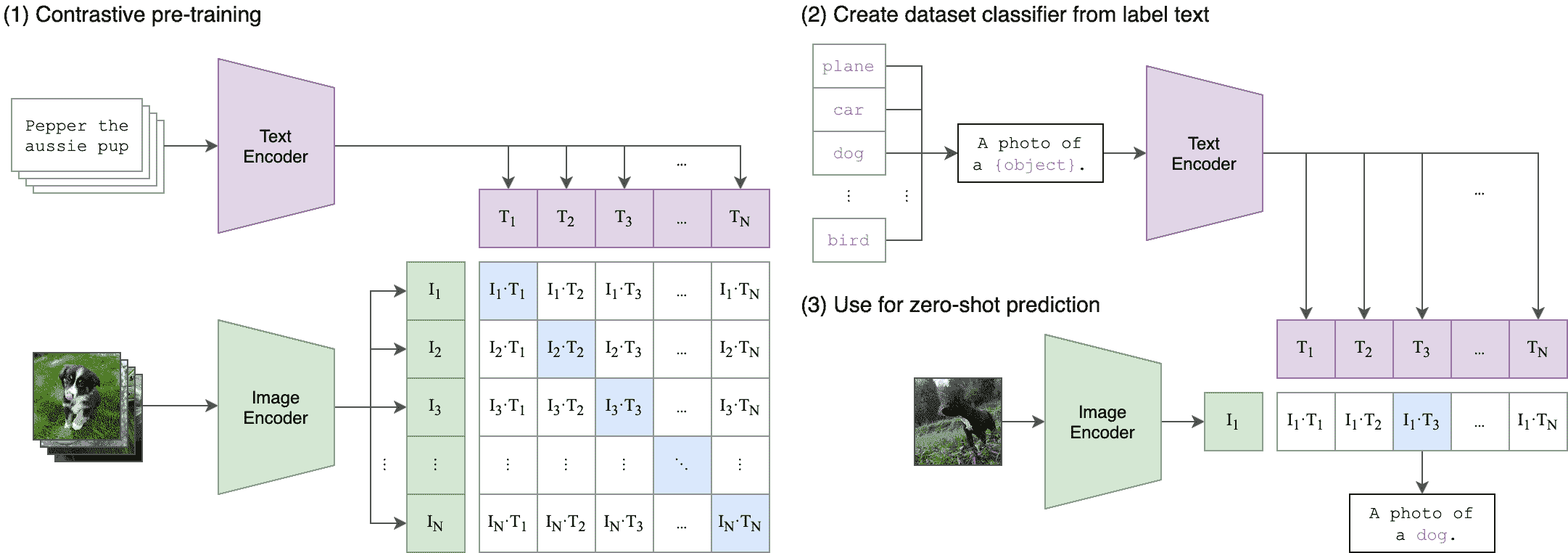
ViT
(1)patch embedding:假如输入图片大小为224x224,patch大小为16x16,则每张图像会生成224x224/16x16=196个patch,即输入序列长度为196,每个patch维度16x16x3=768,即一共有196个token,每个token的维度是768。这里还需要加上一个特殊字符cls,因此最终的维度是197x768。
(2)positional embedding:位置编码就是将以上的197个token按着bert的绝对位置编码来进行设置。
class VisionTransformer(nn.Module):
def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
super().__init__()
self.input_resolution = input_resolution
self.output_dim = output_dim
self.conv1 = nn.Conv2d(in_channels=3, out_channels=width, kernel_size=patch_size, stride=patch_size, bias=False)
scale = width ** -0.5
self.class_embedding = nn.Parameter(scale * torch.randn(width))
self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width))
self.ln_pre = LayerNorm(width)
self.transformer = Transformer(width, layers, heads)
self.ln_post = LayerNorm(width)
self.proj = nn.Parameter(scale * torch.randn(width, output_dim))
def forward(self, x: torch.Tensor):
x = self.conv1(x) # shape = [*, width, grid, grid]
x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2]
x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width]
x = torch.cat([self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1) # shape = [*, grid ** 2 + 1, width]
x = x + self.positional_embedding.to(x.dtype)
x = self.ln_pre(x)
x = x.permute(1, 0, 2) # NLD -> LND
x = self.transformer(x)
x = x.permute(1, 0, 2) # LND -> NLD
# 取x的L这个维度的第一个向量 x.shape=[batch_size, width]
x = self.ln_post(x[:, 0, :])
if self.proj is not None:
x = x @ self.proj
# shape = [batch_size, output_dim]
return x
CLIP
class CLIP(nn.Module):
def __init__(self,
embed_dim: int,
# vision
image_resolution: int,
vision_layers: Union[Tuple[int, int, int, int], int],
vision_width: int,
vision_patch_size: int,
# text
context_length: int,
vocab_size: int,
transformer_width: int,
transformer_heads: int,
transformer_layers: int
):
super().__init__()
self.context_length = context_length
if isinstance(vision_layers, (tuple, list)):
vision_heads = vision_width * 32 // 64
self.visual = ModifiedResNet(
layers=vision_layers,
output_dim=embed_dim,
heads=vision_heads,
input_resolution=image_resolution,
width=vision_width
)
else:
vision_heads = vision_width // 64
self.visual = VisionTransformer(
input_resolution=image_resolution,
patch_size=vision_patch_size,
width=vision_width,
layers=vision_layers,
heads=vision_heads,
output_dim=embed_dim
)
self.transformer = Transformer(
width=transformer_width,
layers=transformer_layers,
heads=transformer_heads,
attn_mask=self.build_attention_mask()
)
self.vocab_size = vocab_size
self.token_embedding = nn.Embedding(vocab_size, transformer_width)
self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width))
self.ln_final = LayerNorm(transformer_width)
self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim))
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
self.initialize_parameters()
def encode_image(self, image):
return self.visual(image.type(self.dtype))
def encode_text(self, text):
x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model]
x = x + self.positional_embedding.type(self.dtype)
x = x.permute(1, 0, 2) # NLD -> LND
x = self.transformer(x)
x = x.permute(1, 0, 2) # LND -> NLD
x = self.ln_final(x).type(self.dtype)
# x.shape = [batch_size, n_ctx, transformer.width]
# take features from the eot embedding (eot_token is the highest number in each sequence)
x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
return x
def forward(self, image, text):
image_features = self.encode_image(image)
text_features = self.encode_text(text)
# normalized features
image_features = image_features / image_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
# 此两个tensor的维度shape = [batch_size, embed_dim]
return image_features, text_features
- Loss1
def train():
model = CLIP(
embed_dim,
image_resolution, vision_layers, vision_width, vision_patch_size,
context_length, vocab_size, transformer_width, transformer_heads, transformer_layers
)
image_features, text_features = model(image, text)
# logits.shape=[Batch,Batch]
logits = (text_features @ image_features.T)
images_similarity = image_features @ image_features.T
texts_similarity = text_features @ text_features.T
logits = F.softmax(logits, dim=-1)
targets = F.softmax(
(images_similarity + texts_similarity) / 2, dim=-1
)
loss = (-targets * logits).sum(1) # shape: (batch_size)
return loss.mean()
论文中的原始计算方式2:
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
ViT参数量计算3
参数量参考表4
ViT-B:
图片大小为224x224,patch大小为16x16
layers=12,hidden_size=768,MLP_size=3072,heads=12,params=86M
- Patch embedding
patch_dim = 16*16*3, dim = hidden_size = 768 所以参数量为768*768
注意这里这个层用conv和linear其实是一样的
- Attention
w_q,w_k.w_v,w_o
dim*dim*4*layers = 768*768*4*12
- FFN
dim*MLP_size*2*layers=768*3072*2*12
- LN
dim*2*2*layer=768*2*2*12
mlp_head: dim*2=768*2
注意有一个单独分类的mlp_head
Reference
-
CLIP 核心代码解读. https://zhuanlan.zhihu.com/p/643033091 ↩
-
Learning Transferable Visual Models From Natural Language Supervision. https://arxiv.org/pdf/2103.00020.pdf ↩
-
ViT-B参数量计算. https://blog.csdn.net/zkxhlbt/article/details/115471463 ↩
-
Vision Transformer. https://zyc.ai/transformer/vision_transformer/#_2 ↩