[TOC]
3.20 一面
项目
- Lora原理?Lora的参数量计算?Lora参数是包含Attention还是MLP?Lora参数的初始化?为什么这样初始化?
- 介绍Speculative Decoding、vLLM、FlashAttention
- 以上三个工作结合起来有什么创新
- transfomer的计算瓶颈到底是在哪?
不同的论文不同视角,从LLM的prefill-decode两阶段来看,是attention的长decode造成计算效率不高;
但是从计算时间长度上看,FFN其实占比最长
- 多模态大模型具体是怎么做的
- 聊项目
3.25 二面
- 讲讲理解的learning rate 和 batch size?怎么调优?bs是越大越好吗
批大小增大可能需要相应增加学习率,太大的batchsize可能会使得模型陷入局部最优
- learning rate和优化器有关吗?了解哪些优化器?了解SGD吗?
不同的优化器可能会以不同的方式使用学习率,包括固定学习率、递减学习率、或者是自适应调整学习率。
- 过拟合有什么解决办法
- dropout了解吗(我听成了job out)
- sora架构
- diffusion架构了解吗?
- controlNet了解吗?
- transformer为什么能够成为主流架构?了解其他替代吗?了解mamba吗
参考1
- peft有哪几种?讲讲细节?(adaptor,prefix tuning,lora)
- qlora了解吗?
- 多模态大模型,比如mplug是怎么做到不同模态融合的?
- 为什么decoder-only主流?
- 项目:Kwai、Paper
手撕
Bg:
- 线性差值
- 双线性插值
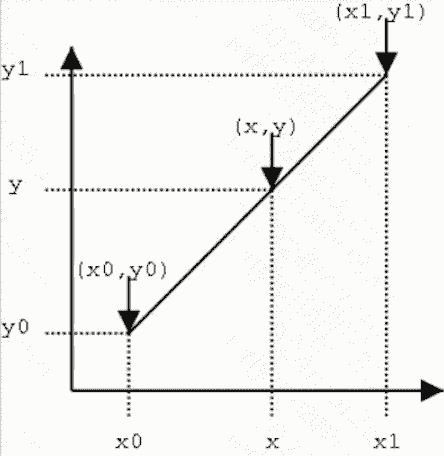
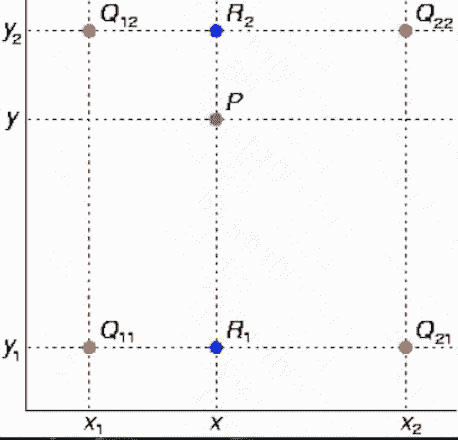

‘’‘
img: 输入图片 256 * 256
scale: 放大系数 2
output: 输出图片 512 * 512
从img得到放大后到输出图片
’‘’
def find(x,y):
x1,y1,x2,y2 = x//scale,y//scale,x//scale+1,y//scale+1
fq11=image[x1][y1]
fq12=image[x1][y2]
fq21=image[x2][y1]
fq22=image[x2][y2]
new_x1,new_y1,new_x2,new_y2=
x1*scale,y1*scale,x2*scale,y2*scale
fxy1=(new_x2-x)/(new_x2-new_x1)*fq11+
(x-new_x1)/(new_x2-new_x1)*fq21
fxy2=(new_x2-x)/(new_x2-new_x1)*fq12+
(x-new_x1)/(new_x2-new_x1)*fq22
return (new_y2-y)/(new_y2-new_y1)*fxy1+
(y-new_y1)/(new_y2-new_y1)*fxy2
h,w = image.height,image.width
new_h,new_w=h*scale,w*scale
output=[[0]*new_w for _ in range(new_h)]
for i in range(new_w):
for j in range(new_h):
output[i][j]=find(i,j)
proint(output)
Reference
-
LLM(廿四):Transformer 的结构改进与替代方案. https://zhuanlan.zhihu.com/p/673781418 ↩