[TOC]
为什么用RL?
使用强化学习(而非监督学习)的方式更新语言模型,最大的优势是在于能够使得「模型更加自由的探索更新方向,从而突破监督学习的性能天花板」。
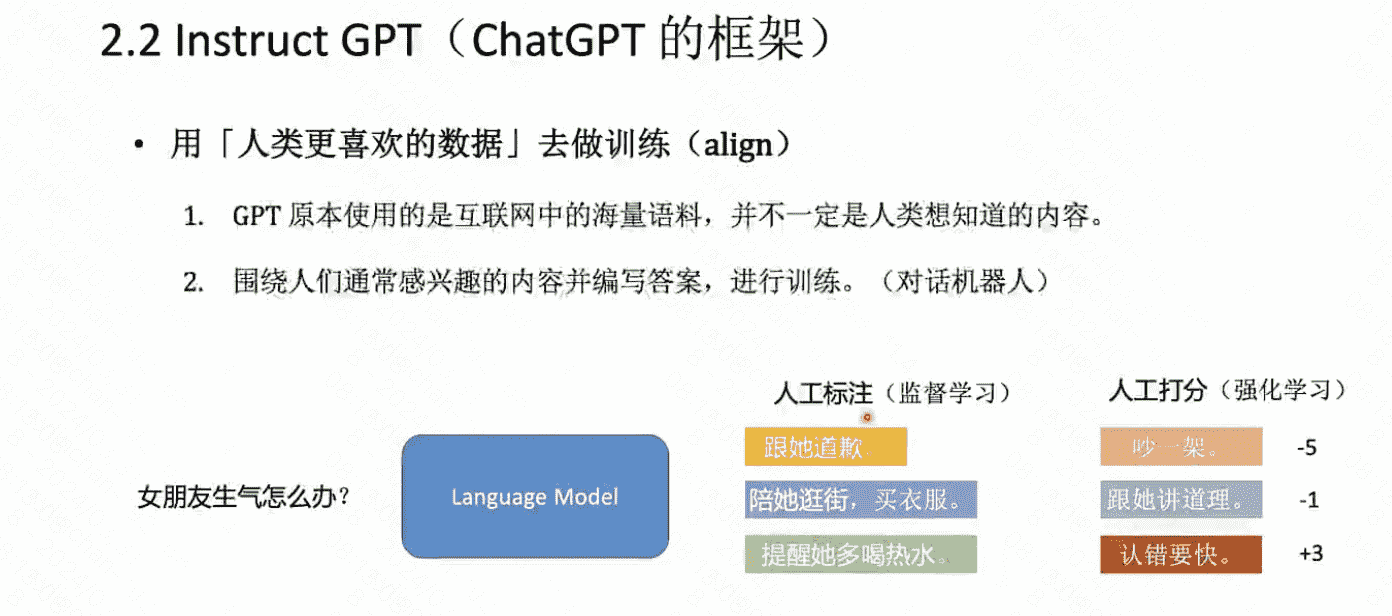
RLHF
整体流程
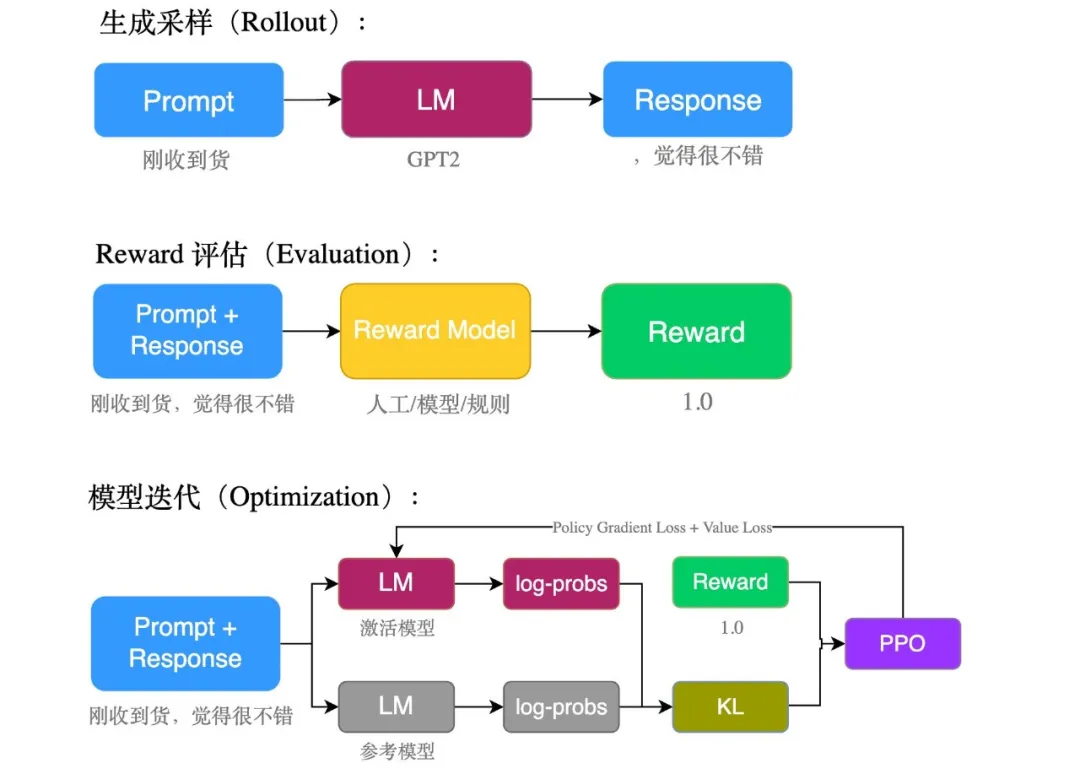
这里的reward我们使用判别模型输出,以降低人工成本
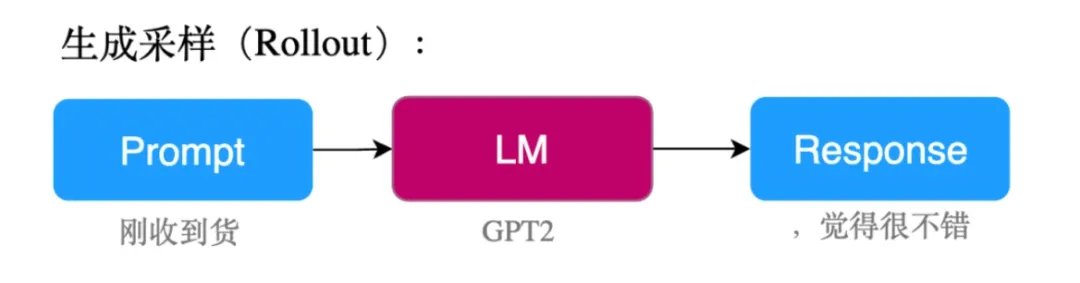
1) 生成采样(Rollout)
# prompt池
prompts = [
'刚收到货,感觉',
'这部电影很',
'说实话,真的很',
'这次购物总的来说体验很'
]
...
for _ in range(config['batch_size']):
random_prompt = random.choice(prompts) # 随机选择一个prompt
tokens = gpt2_tokenizer.encode(random_prompt)
batch['tokens'].append(tokens)
batch['query'].append(random_prompt)
query_tensors = [torch.tensor(t).long().to(device) for t in batch["tokens"]]
...
for i in range(config['batch_size']):
gen_len = config['gen_len']
response = gpt2_model.generate(query_tensors[i].unsqueeze(dim=0), # 利用当前选择的prompt生成句子
max_new_tokens=gen_len, **gen_kwargs)
response_tensors.append(response.squeeze()[-gen_len:])
为了保证生成句子的多样性,我们设定了一个 prompt 池,从中随机选择一个进行生成,获得多个模型的生成结果。
2)Reward 评估(Evaluation)
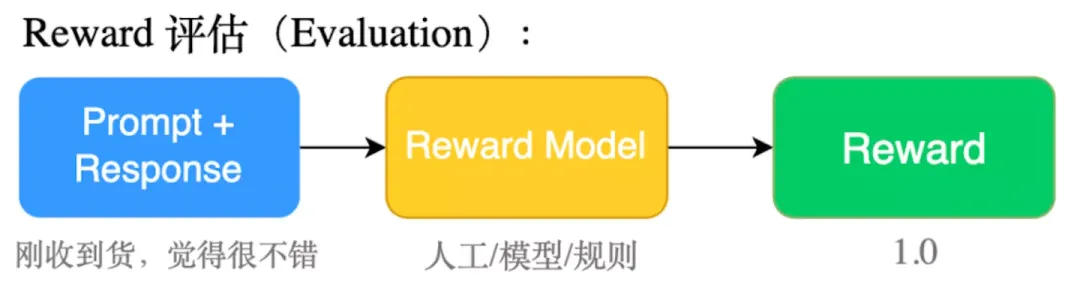
利用roberta进行情感分类打分
# 情绪识别模型初始化
senti_tokenizer = AutoTokenizer.from_pretrained('uer/roberta-base-finetuned-jd-binary-chinese')
senti_model = AutoModelForSequenceClassification.from_pretrained('uer/roberta-base-finetuned-jd-binary-chinese')
sentiment_pipe = pipeline('sentiment-analysis', model=senti_model, tokenizer=senti_tokenizer, device=pipe_device)
...
# 将 prompt 和生成的 response 做拼接
texts = [q + r for q,r in zip(batch['query'], batch['response'])]
pipe_outputs = sentiment_pipe(texts) # 计算正向/负向情感得分
3)模型迭代(Optimization)
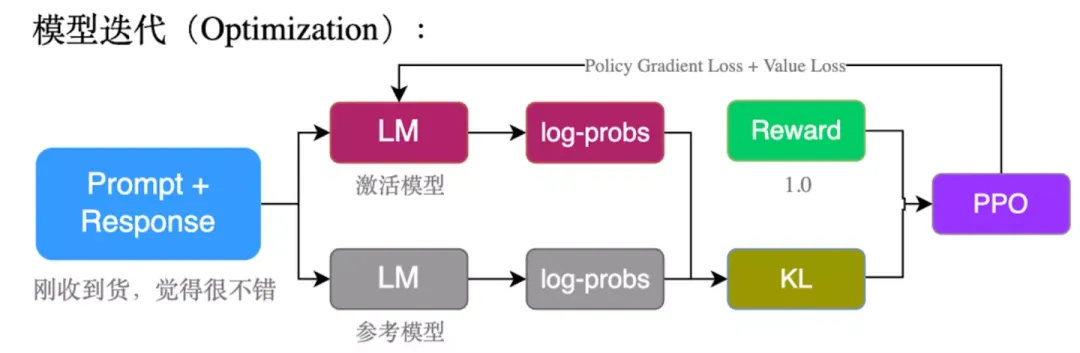
ppo_trainer.step(query_tensors, response_tensors, rewards) # PPO Update
PPO具体算法参考1
具体来说,PPO在更新时一共会计算 2 个 loss:pg_loss、value_loss:
loss_p, loss_v, train_stats = self.loss(logprobs, values, rewards, query, response, model_input)
loss = loss_p + loss_v
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
...
pg_loss
pg_loss 是 PPO 中 actor 的 loss 函数,其通过 discount reward 和 importance ratio 来计算当前 step 的 reward 应该是多少: \(l o s s_{p g}=\frac{P_{\pi_{\text {new }(t \text { token })}}}{P_{\pi_{\text {old }}(t o k e n)}}\left(r+\gamma V_{\text {next }}-V_{\text {current }}\right)\) 其中,importance ratio 是指产生同样的 token,在 active actor model 和 reference actor model 下的概率比值,这也是 PPO 模型中的 Importance Sampling 系数。
for t in reversed(range(gen_len)):
nextvalues = values[:, t + 1] if t < gen_len - 1 else 0.0
delta = rewards[:, t] + self.ppo_params['gamma'] * nextvalues - values[:, t] # 优势函数:r + Vnext - V
lastgaelam = delta + self.ppo_params['gamma'] * self.ppo_params['lam'] * lastgaelam # GAE, 用于平衡 bias 和 variance
advantages_reversed.append(lastgaelam)
advantages = torch.stack(advantages_reversed[::-1]).transpose(0, 1)
logits, _, vpred = self.model(model_input) # 跑一遍模型,得到句子中每个token被选择的概率
logprob = logprobs_from_logits(logits[:,:-1,:], model_input[:, 1:]) # 将概率取log对数
ratio = torch.exp(logprob - old_logprobs) # log相减,等同于概率相除
pg_losses = -advantages * ratio
value_loss
value_loss 是 PPO 中 critic 的 loss 函数,其目的在于评判每一个 token 被生成后的 value 是多少。
这是因为在 PPO 中需要有一个 critic 网络,为了实现这个效果,我们需要对 GPT 模型进行改造。
我们在 GPT 中加入一个 Value Head,用于将 hidden_size 向量映射到一个 1 维的 value 向量:
class GPT2HeadWithValueModel(GPT2PreTrainedModel):
"""The GPT2HeadWithValueModel class implements a GPT2 language model with a secondary, scalar head."""
def __init__(self, config):
super().__init__(config)
config.num_labels = 1
self.transformer = GPT2Model(config)
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
self.v_head = ValueHead(config) # 添加 Value Head
self.init_weights()
...
class ValueHead(nn.Module):
"""The ValueHead class implements a head for GPT2 that returns a scalar for each output token."""
def __init__(self, config):
super().__init__()
self.summary = nn.Linear(config.hidden_size, 1) # (hidden_size -> 1)
...
value_loss 就应该等于 Value Head 产生的预测值 v_pred 和真实值 r + v_next 之间的差值: \(\text { loss }_{\text {value }}=\left\|V_{\text {pred }}-\left(r+V_{\text {next }}\right)\right\|\)
returns = advantages + values # r + v_next - v + v => r + v_next
logits, _, vpred = self.model(model_input) # 跑一遍语言模型,得到每个 token 的 v_pred
vf_losses1 = (vpred - returns) ** 2 # MSE
Reward Model
ChatGPT 中,奖励模型是通过人工标注的「排序序列」来进行训练的:
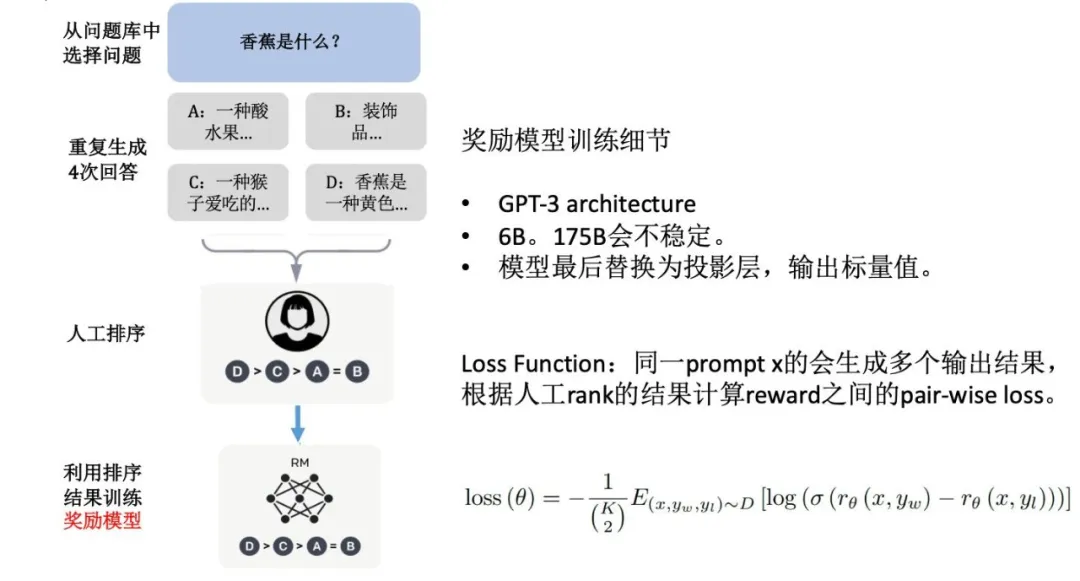
把任务转为一个排序问题,以规避主观绝对分数标准不确定的问题:
假定现在有一个排好的序列:A > B > C >D。
我们需要训练一个打分模型,模型给四句话打出来的分要满足 r(A) > r(B) > r(C) > r(D)。
那么,我们可以使用下面这个损失函数: \(\operatorname{loss}(\theta)=-\frac{1}{\left(\begin{array}{c} K \\ 2 \end{array}\right)} E_{\left(x, y_w, y_l\right) \sim D}\left[\log \left(\sigma\left(r_\theta\left(x, y_w\right)-r_\theta\left(x, y_l\right)\right)\right)\right]\) 用上述例子(A > B > C > D)来讲,loss 应该等于:
loss = r(A) - r(B) + r(A) - r(C) + r(A) - r(D) + r(B) - r(C) + ... + r(C) - r(D)
loss = -loss
为了更好的归一化差值,我们对每两项差值都过一个 sigmoid 函数将值拉到 0 ~ 1 之间。可以看到,loss 的值等于排序列表中所有「排在前面项的reward」减去「排在后面项的reward」的和。
而我们希望模型能够「最大化」这个「好句子得分」和「坏句子得分」差值,而梯度下降是做的「最小化」操作。因此,我们需要对 loss 取负数,就能实现「最大化差值」的效果了。
class RewardModel(nn.Module):
def __init__(self, encoder):
"""
init func.
Args:
encoder (transformers.AutoModel): backbone, 默认使用 ernie 3.0
"""
super().__init__()
self.encoder = encoder
self.reward_layer = nn.Linear(768, 1) # reward layer 用于映射到 1 维 reward
def forward(
self,
input_ids: torch.tensor,
token_type_ids: torch.tensor,
attention_mask=None,
pos_ids=None,
) -> torch.tensor:
"""
forward 函数,返回每句话的得分值。
Args:
input_ids (torch.tensor): (batch, seq_len)
token_type_ids (torch.tensor): (batch, seq_len)
attention_mask (torch.tensor): (batch, seq_len)
pos_ids (torch.tensor): (batch, seq_len)
Returns:
reward: (batch, 1)
"""
pooler_output = self.encoder(
input_ids=input_ids,
token_type_ids=token_type_ids,
position_ids=pos_ids,
attention_mask=attention_mask,
)["pooler_output"] # (batch, hidden_size)
reward = self.reward_layer(pooler_output) # (batch, 1)
return reward
计算 rank_loss 函数如下,因为样本里的句子已经默认按从高到低得分排好,因此我们只需要遍历的求前后项的得分差值加起来即可:
def compute_rank_list_loss(rank_rewards_list: List[List[torch.tensor]], device='cpu') -> torch.Tensor:
"""
通过给定的有序(从高到低)的ranklist的reward列表,计算rank loss。
所有排序高的句子的得分减去排序低的句子的得分差的总和,并取负。
Args:
rank_rewards_list (torch.tensor): 有序(从高到低)排序句子的reward列表,e.g. ->
[
[torch.tensor([0.3588]), torch.tensor([0.2481]), ...],
[torch.tensor([0.5343]), torch.tensor([0.2442]), ...],
...
]
device (str): 使用设备
Returns:
loss (torch.tensor): tensor([0.4891], grad_fn=<DivBackward0>)
"""
if type(rank_rewards_list) != list:
raise TypeError(f'@param rank_rewards expected "list", received {type(rank_rewards)}.')
loss, add_count = torch.tensor([0]).to(device), 0
for rank_rewards in rank_rewards_list:
for i in range(len(rank_rewards)-1): # 遍历所有前项-后项的得分差
for j in range(i+1, len(rank_rewards)):
diff = F.sigmoid(rank_rewards[i] - rank_rewards[j]) # sigmoid到0~1之间
loss = loss + diff
add_count += 1
loss = loss / add_count
return -loss
Further Strategy
Reference
-
强化学习之PPO算法. https://zhuanlan.zhihu.com/p/468828804 ↩