[TOC]
Abstract
这个模型是any-to-any的
we propose to utilize an additional visual encoder for high-resolution refinement without increasing the visual token count.
Intro
- 输入端:
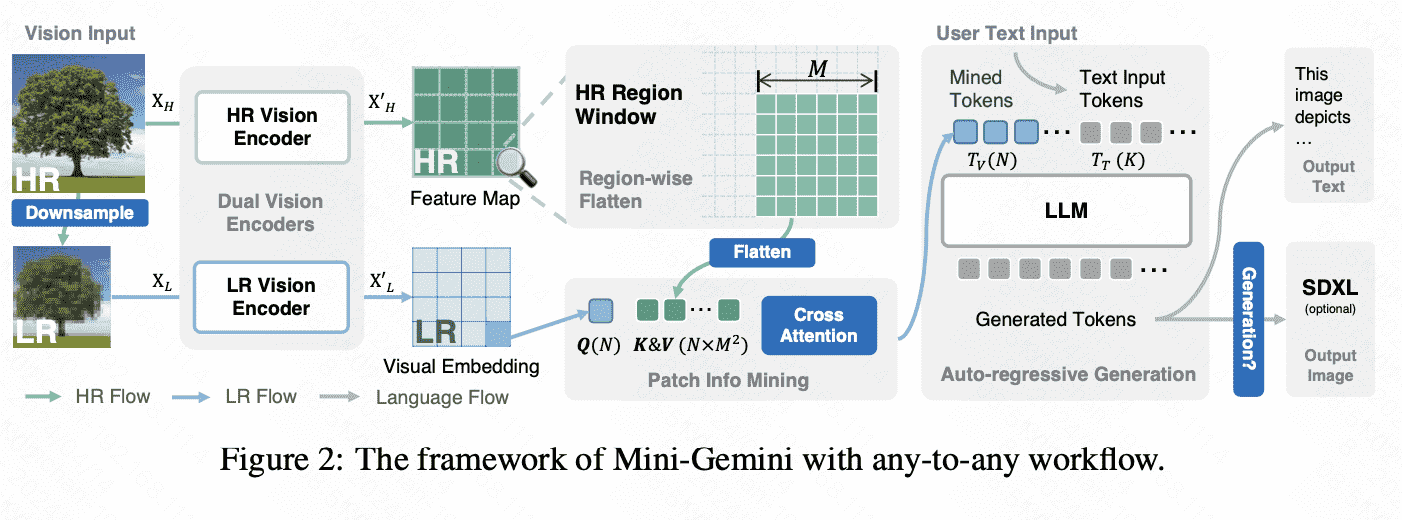
模型视觉输入端是dual-encoder结构:one for high-resolution images and the other for low-resolution visual embedding(据说是模仿Gemini的结构)
During inference, they work in an attention mechanism, where the low-resolution one generates visual queries, and the high-resolution counterpart provides candidate keys and values for reference.
- 输出端:
利用LLM生成的句子去知道SD做生成:It leverages VLM guidance for image generation by providing the generated text from LLMs.
Related Work
这里有一段截止2024年3月27日的,LLM输出端多模态能力研究的总结:Combining LLMs with image outputs has emerged as a pivotal area in recent multimodal research. Methods like InternLM-XComposer [44, 45] utilize image retrieval to produce interleaved text and image outputs, bypassing direct generation. Conversely, auto-regressive token prediction approaches, exemplified by EMU [46, 47] and SEED [48, 49], enable LLMs to decode images through massive image-text data directly. These methods require enormous training resources, and their auto-regressive nature leads to undesirable latency. Recent studies [50–52] strive to align with latent diffusion models [22] to streamline image generation. They typically require designing text embeddings and additional optimization to achieve the desired generation effect. This joint training can compromise the performance of VLMs in text generation. Mini-Gemini distinguishes itself by adopting a text-data-driven approach to enable the model to generate high-quality images. We leverage a mere 13K pure text data to activate the LLM’s ability as a high-quality re-captioner [53] without undermining the fundamental performance of VLMs.
Mini-Gemini
Overall Framework
Dual Vision Encoder
LR Vision Encoder:CLIP-pretrained ViT,得到特征维度$N\times C$
HR Vision Encoder:LAION-pretrained ConvNeXt(也是采用对比学习),得到特征维度$N\times M^2 \times C$
Patch Info Mining
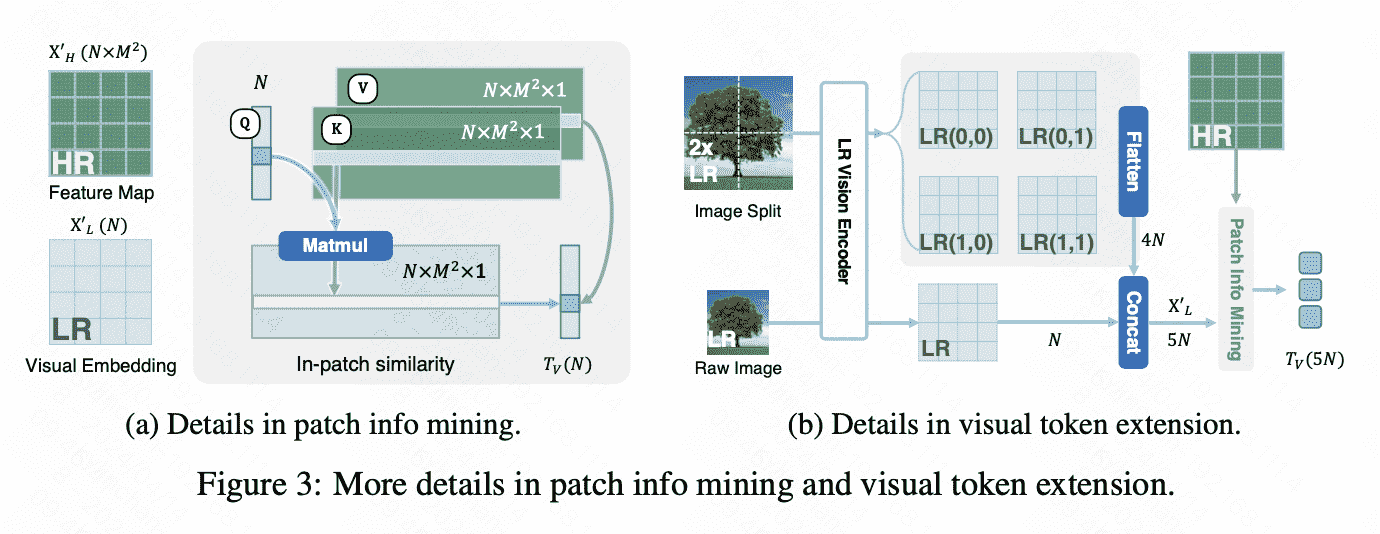 \(T_V=\operatorname{MLP}\left(Q+\operatorname{Softmax}\left(\phi(Q) \times \phi(K)^T\right) \times \phi(V)\right)\)
$\phi$是一个线性层,把通道C压缩到1
\(T_V=\operatorname{MLP}\left(Q+\operatorname{Softmax}\left(\phi(Q) \times \phi(K)^T\right) \times \phi(V)\right)\)
$\phi$是一个线性层,把通道C压缩到1
Token Extension
对LR进行双线性插值,之后拓展query;并且由于convnext对良好性质,可以上采样HR以适应Patch Info Mining。
Train
Image Generation
本质上是训练模型拓展SD提升文本的能力,其中一个训练任务的数据来源:(a) Simple instruction re-caption: we adopt 8K descriptive image captions from LAION-GPT-4V [60] and let GPT-4 inversely infer the corresponding user’s short input and the target caption in the Stable Diffusion (SD) domain.