[TOC]
CVPR 2024
Abstract
以前MLLM的问题:can only take in a limited number of frames for short video understanding
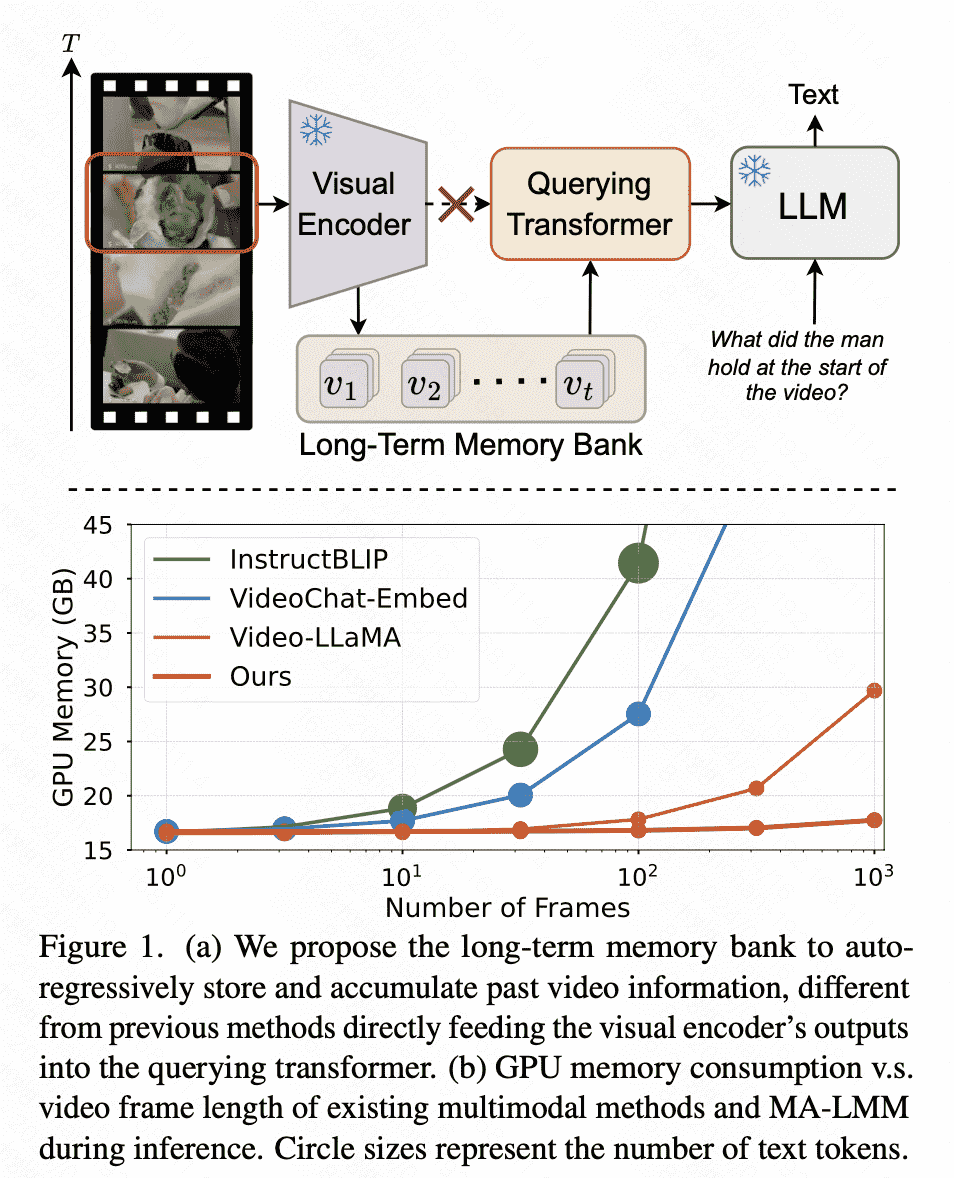
motivation:Instead of trying to process more frames simultaneously like most existing work, we propose to process videos in an online manner and store past video information in a memory bank.
意味着是串行的进行memory处理
Intro
Research Timeline
- 最早期研究直接把每一帧的query embedding插入到prompt中,但是收到最长文本、GPU显存限制(LLaVA 256 tokens,Blip2 32 tokens)
- 平均池化:Video- ChatGPT,但是缺少temporal modeling。
- Video-LLaMA:employs an extra video querying transformer (Q-Former) to obtain video-level representation,但是设计过于复杂,且不能支持online提取。
MALLM Structure
- 与以前相似的components:
a visual encoder to extract visual features,
a querying transformer to align the visual and text embedding spaces,
a large language model
-
创新:一个online、sequential frame memory bank:an online processing approach that takes video frames sequen- tially and stores the video features in the proposed long-term memory bank.
两个优点:
- 规避maxlenth
- 不会爆GPU显存
据说还有memory compression、frame selecting相关的创新
MALLM
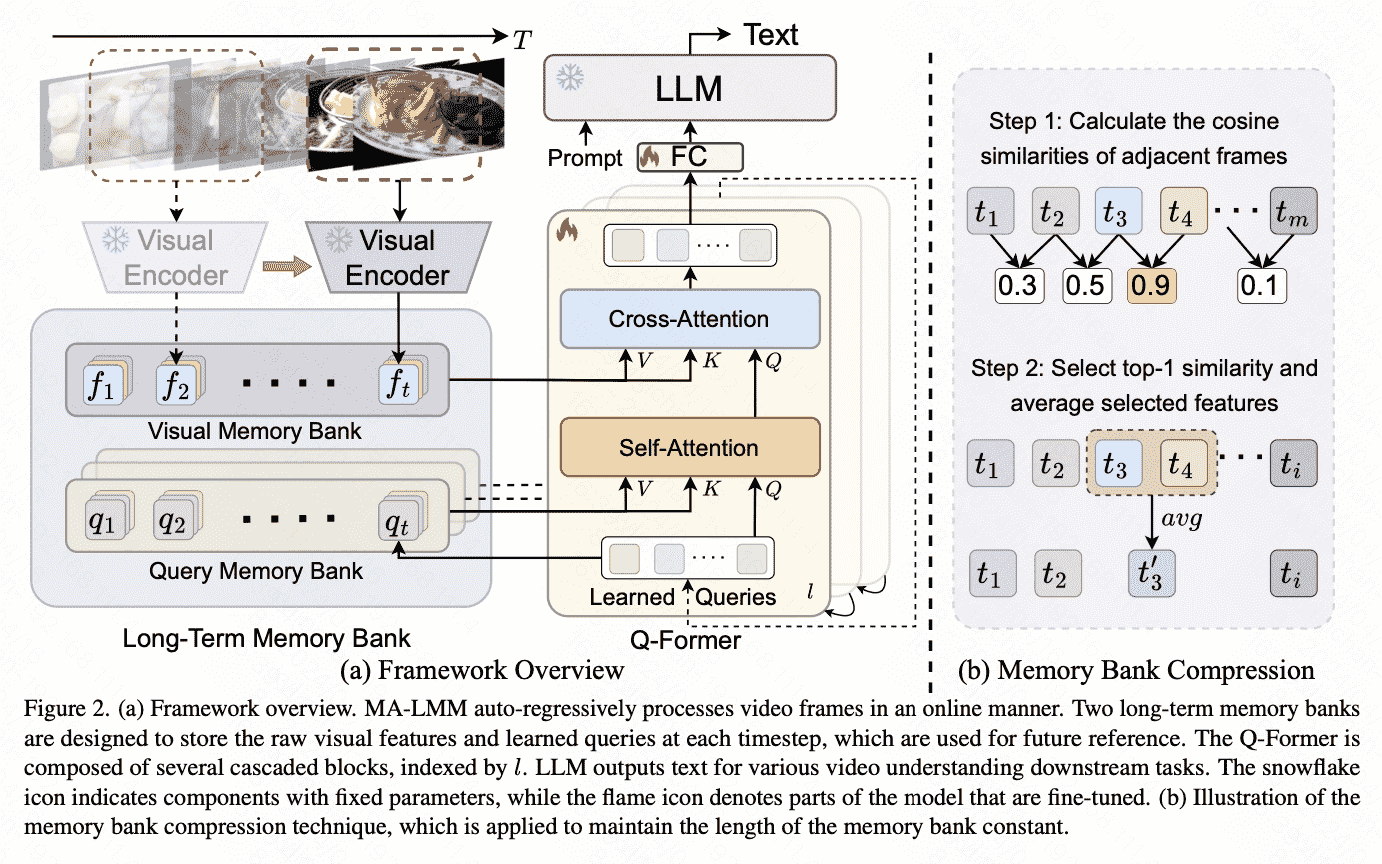
Visual Feature Extraction
对每一frame过 ViT 生成 vision feature序列,之后加上PE (positional embedding) 作为时序特征: \(V=\left[v_1, v_2, . ., v_T\right], v_t \in \mathbb{R}^{P \times C}\)
\[f_t=v_t+P E(t), f_t \in \mathbb{R}^{P \times C} .\]Long-term Temporal Modeling
Q-former 有多个block,使用32个learnable tokens(和blip2保持一致),主要包含两个attention:
- (1) cross-attention layer, which interacts with the raw visual embedding ex- tracted from the frozen visual encoder
- (2) self-attention layer, which models interactions within the input queries
1)Visual Memory Bank
visual features $F_t=$ Concat $\left[f_1, f_2, . ., f_t\right], F_t \in \mathbb{R}^{t P \times C}$ Given the input query $z_t$, the visual memory bank acts as the key and value as: \(Q=z_t W_Q, K=F_t W_K, V=F_t W_V .\)
Then we apply the cross-attention operation as: \(O=\operatorname{Attn}(Q, K, V)=\operatorname{Softmax}\left(\frac{Q K^T}{\sqrt{C}}\right) V\) 注意所有的Q-former blocks共享一个视觉bank
2)Query Memory Bank
storing queries of each timestep to cross attention, represented as $Z_t=\operatorname{Concat}\left[z_1, z_2, . ., z_t\right], Z_t \in$ $\mathbb{R}^{t N \times C}$: \(Q=z_t W_Q, K=Z_t W_K, V=Z_t W_V .\) 每个Q-former blocks独享一个query bank
3)Memory Bank Compression
计算相似度,合并相似feature项
for visual memory bank containing a list of $\left[f_1, f_2, . ., f_M\right], f_t \in$ $\mathbb{R}^{P \times C}$, when a new frame feature $f_{M+1}$ comes in, we need to compress the memory bank by reducing the length by 1. At each spatial location $i$, we first calculate the cosine similarity between all the temporally adjacent tokens as \(s_t^i=\cos \left(f_t^i, f_{t+1}^i\right), t \in[1, M], i \in[1, P] .\)
Then we select the highest similarity across time, which can be interpreted as the most temporally redundant features: \(k=\operatorname{argmax}_t\left(s_t^i\right) .\)
Next, we simply average the selected token features at all the spatial locations to reduce the memory bank length by 1 : \(\hat{f}_k^i=\left(f_k^i+f_{k+1}^i\right) / 2\)
Text Decoding
注意MALLM的LLM部分是始终frozen的,training 时候就用文本的cross entropy监督: \(\mathcal{L}=-\frac{1}{S} \sum_{i=1}^S \log P\left(w_i \mid w_{<i}, V\right)\) in which V represents the input video, and w_i is the i-th ground-truth text token.
Exp
- 主要在三个维度上评测:
Long-term Video Understanding
Video Question Answering
Video Captioning
Online Action Prediction
- 真正提供这些评测的是一系列数据集
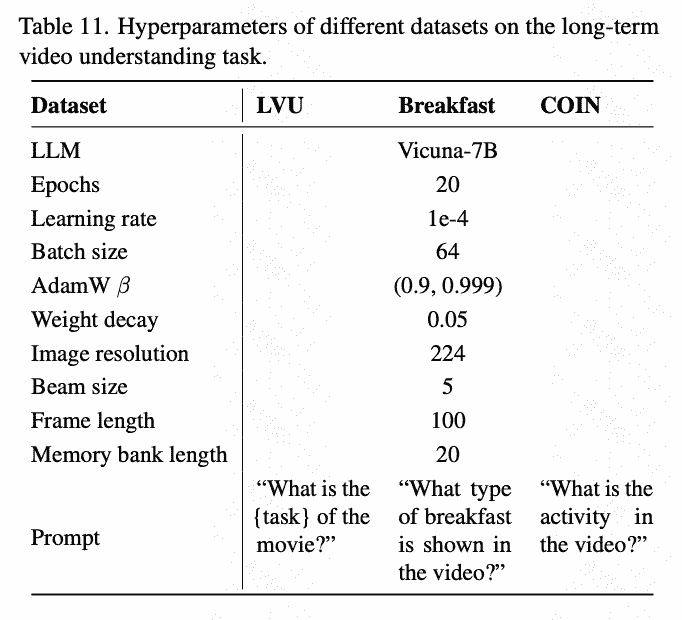
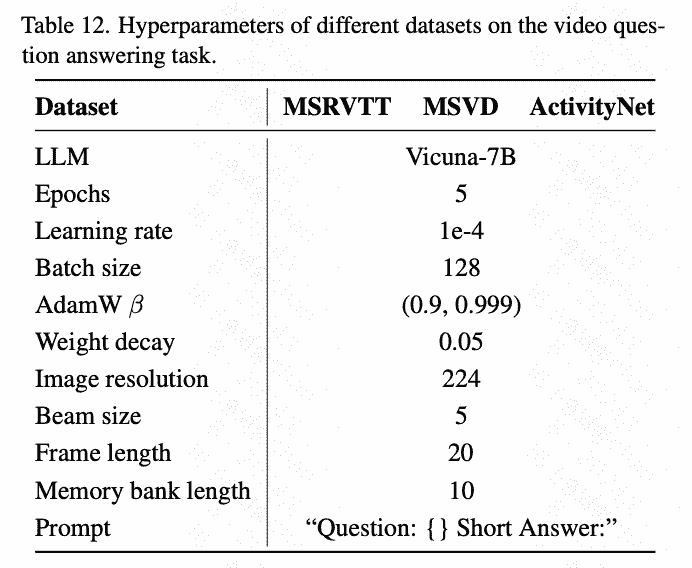
Training Detail
不分training阶段,在三个tasks上训练:
Limitation
- online的处理方法耗时长,可能的solution:hierarchical method,分段处理,再建模段间关系
- 替换image-based visual encoder => video or clip-based encoder