[TOC]
Abstract
现有的幻觉解决方法:特殊数据训练、外部知识库矫正(eg. Agent)
Opera 是一种 decoding 方法,只涉及解码几乎就是free lunch
Insight:MLLMs tend to generate new tokens by focusing on a few summary tokens, but not all the previous tokens. Such partial over- trust inclination results in the neglecting of image tokens and describes the image content with hallucination.
(MLLM解码时候注意力矩阵偏向于使用部分tokens进行解码,而对视觉部分的忽视就很可能造成幻觉)
solution(惩罚、回滚、重选):OPERA introduces a penalty term on the model logits during the beam-search decoding to mitigate the over-trust issue, along with a rollback strategy that retrospects the presence of summary tokens in the previously generated tokens, and re-allocate the token selection if necessary.
Intro
一个发现:聚合模式的token(attention是全局、柱状的)之后容易出现幻觉,并且这类token本身实际意义不足(如标点符号),但是却会对后面的生成产生很大影响。
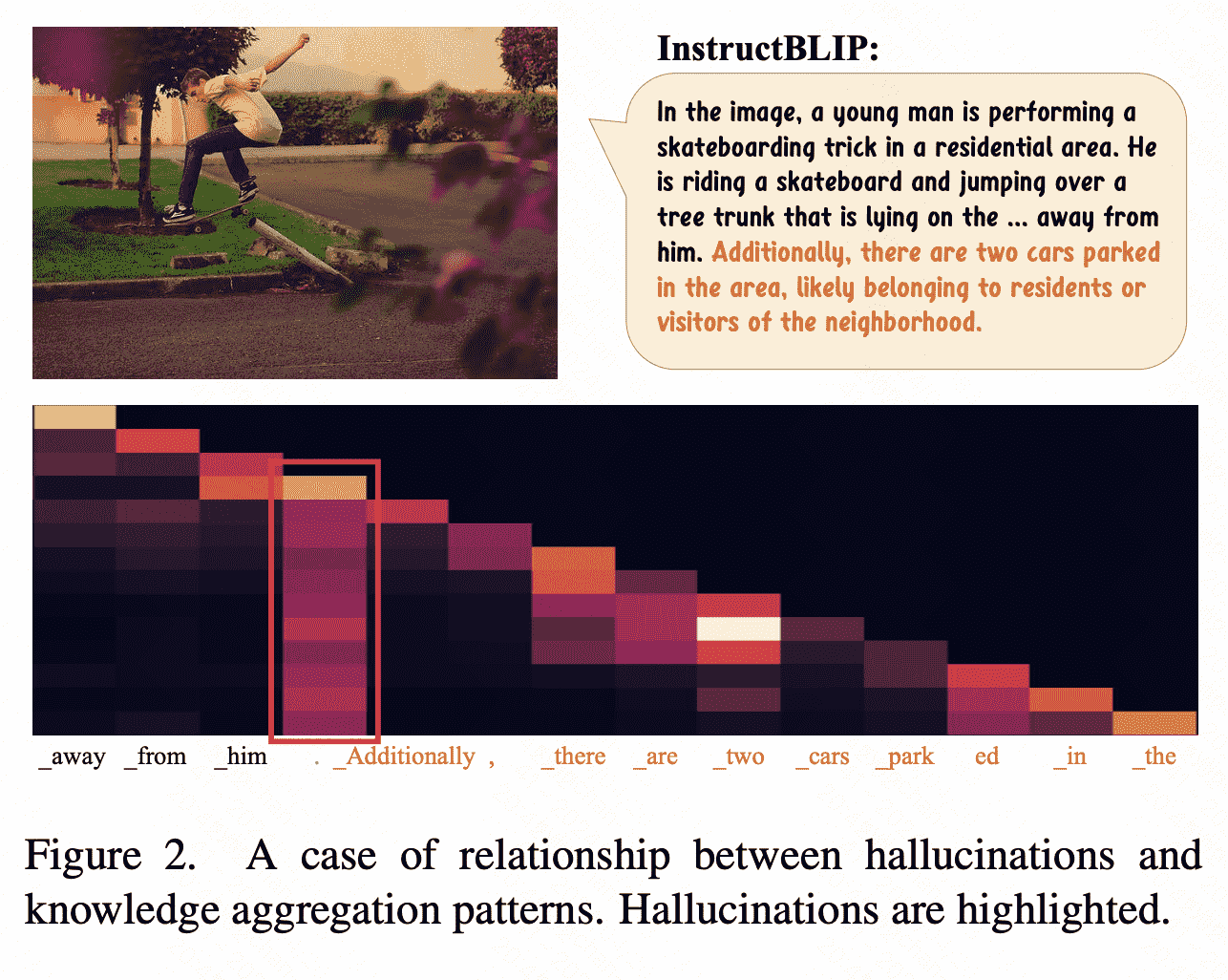
(1)Aggregation pattern’ seems to be the nature of LLM:本文假设这样的token是summary token,类比‘anchor token’ 1 observation in the NLP area,用于总结上文,引导之后的生成。
(2)Aggregation pattern’ leads to hallucination of current MLLMs:现有的MLLM的vision tokens大多放在文本前,随着文本长度增长,以及summary token之间的信息传递,视觉信息会迅速衰减(因为一个summary token很难总结所有视觉信息),即:经过的summary token越多,幻觉越强。
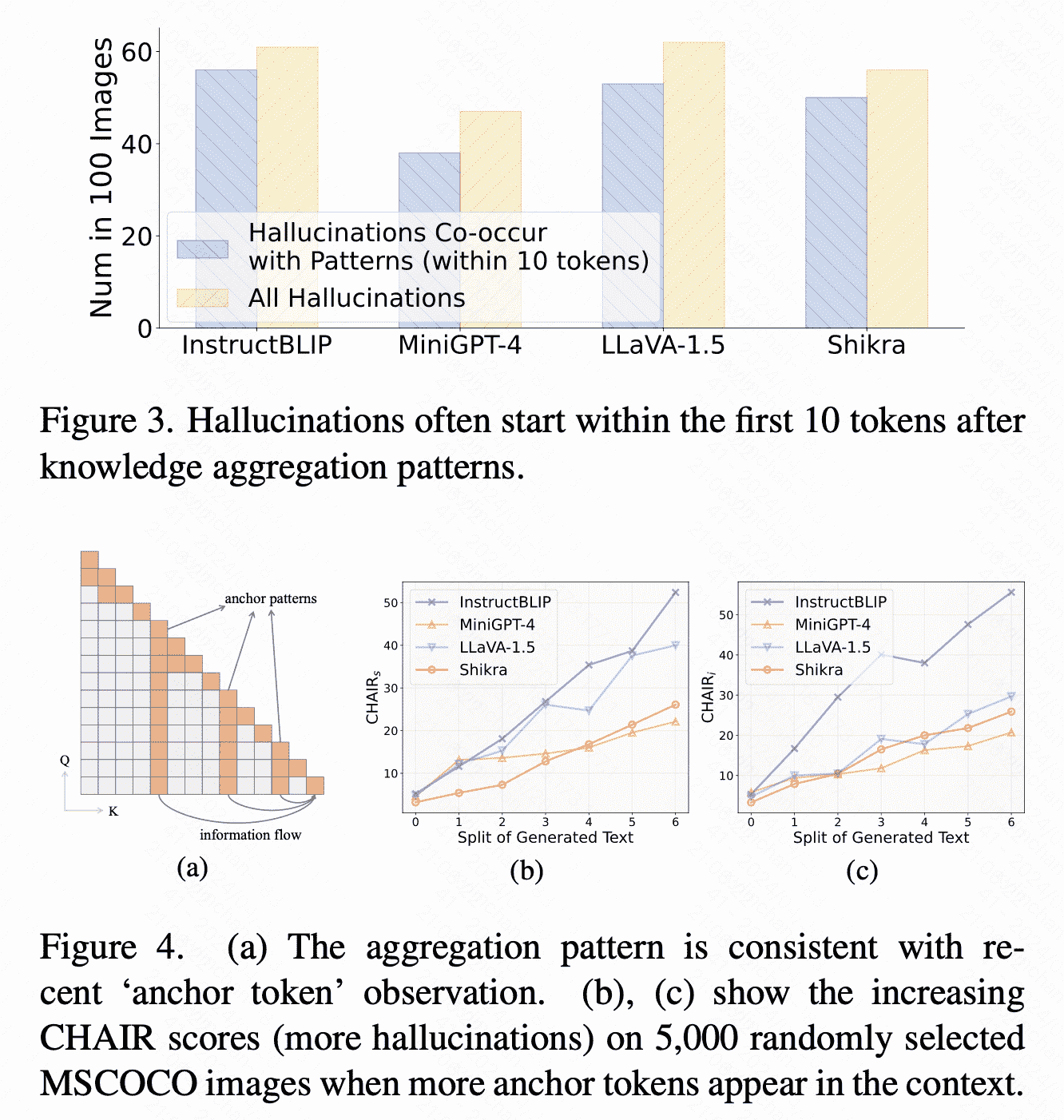
Method:
1)通过对beam search增加惩罚项:The over-trust penalty introduces a weighted score for the candidate selection step in the Beam Search, so that the candidate with an over-trust pattern will have lower priority to be selected.
2)增加解码回滚机制,因为观测到knowledge aggregation pattern存在滞后性。
Relative Work
DoLa 2 decoding is a recently proposed decoding method that aims to mitigate the hallucinations in MLLMs, which contrasts the logits of mature layer and pre-mature layers and rescale the increments as the output.
Method
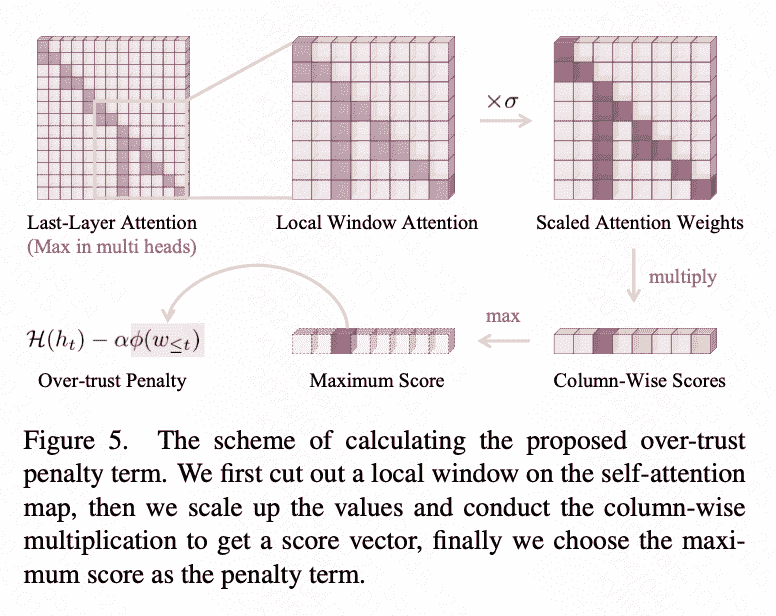
Over-Trust Logit Penalty
首先有attention feature map: \(\mathbf{W}_{t-1}^k=\left\{\mathbf{w}^i\right\}_{i=t-k}^{t-1}, \quad \text { s.t. } \mathbf{w}^i=\left\{\omega_{i, j}\right\}_{j=t-k}^i\) 之后过滤上三角并且乘上一个放大(scaling up,防止attention过小)的系数: \(\mathbf{W}_{t-1}^k \triangleq\left\{\mathbf{w}^i\right\}_{i=t-k}^{t-1}, \quad \text { s.t. } \mathbf{w}^i=\left\{\sigma \omega_{i, j}\right\}_{j=t-k}^{t-1},\) where $\left{\omega_{i, j}\right}_{j=i+1}^{t-1}$ are zeros and $\sigma$ is a configurable scaling factor.
Penalty 系数的计算: \(\phi\left(\omega_{<t}\right)=\prod_{i=c}^{t-1} \sigma \omega_{i, c}, \quad \text { s.t. } c=\underset{t-k \leq j \leq t-1}{\arg \max } \prod_{i=j}^{t-1} \sigma \omega_{i, j}\) 利用Penalty做next token prediction: \(p\left(x_t \mid x_{<t}\right)=\operatorname{Softmax}\left[\mathcal{H}\left(h_t\right)-\alpha \phi\left(w_{\leq t}\right)\right]_{x_t} \text {, } \quad \text { s.t. } x_t \in \mathcal{Y},\) 其中 $\mathcal{H}$ 是 vocabulary head.
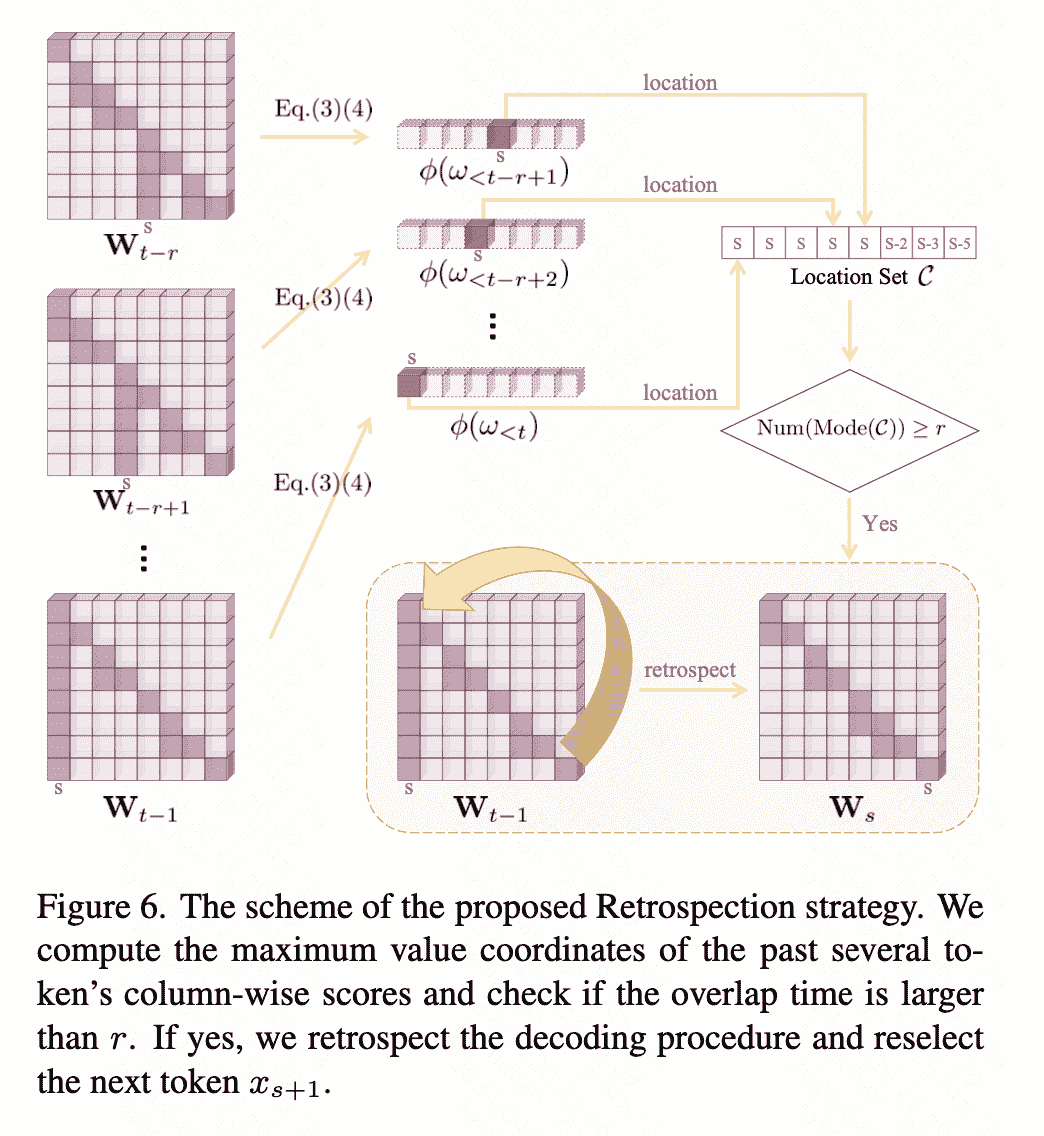
Retrospection-Allocation Strategy
有一种情况是所有candidate都存在penalty和幻觉:there still exists a few cases that all of the candidates get penal- ized and the hallucination already occurred,因此我们需要回退。
回退的思想就是看连续r个最大pattern位置是不是同一个,超过阈值就会退到这个summary token处,并且在next token prediction中排除原来的分支:
pattern位置候选集: \(\mathcal{C}=\left\{c \mid c=\underset{t-k \leq j \leq z}{\arg \max } \prod_{i=j}^z \sigma \omega_{i, j}, z \in[t-l, t-1]\right\}\) 位置判断函数(overlap): \(N_{\text {overlap }}=\sum_{c \in \mathcal{C}} \mathbb{1}_{c=s}, \quad \text { s.t. } s=\operatorname{Mode}(\mathcal{C}) \text {, }\) 如果$N_{overlap} \ge r$,回退到$s = Mode(C)$,并且在下一个token选择上选择 \(\mathcal{Y} /\left\{x_{s+1}\right\}\).
EXP
Metrics
CHAIR: 计算幻觉的比例(sentence层面和image层面)
POPE: 随机sampling问题“Is There a <object> in the image?”,用于VQA.
Eliminating Repetition
作者发现repetition会伴随周期性的knowledge aggregation patterns,这样就可以用本文的rollback去解决。
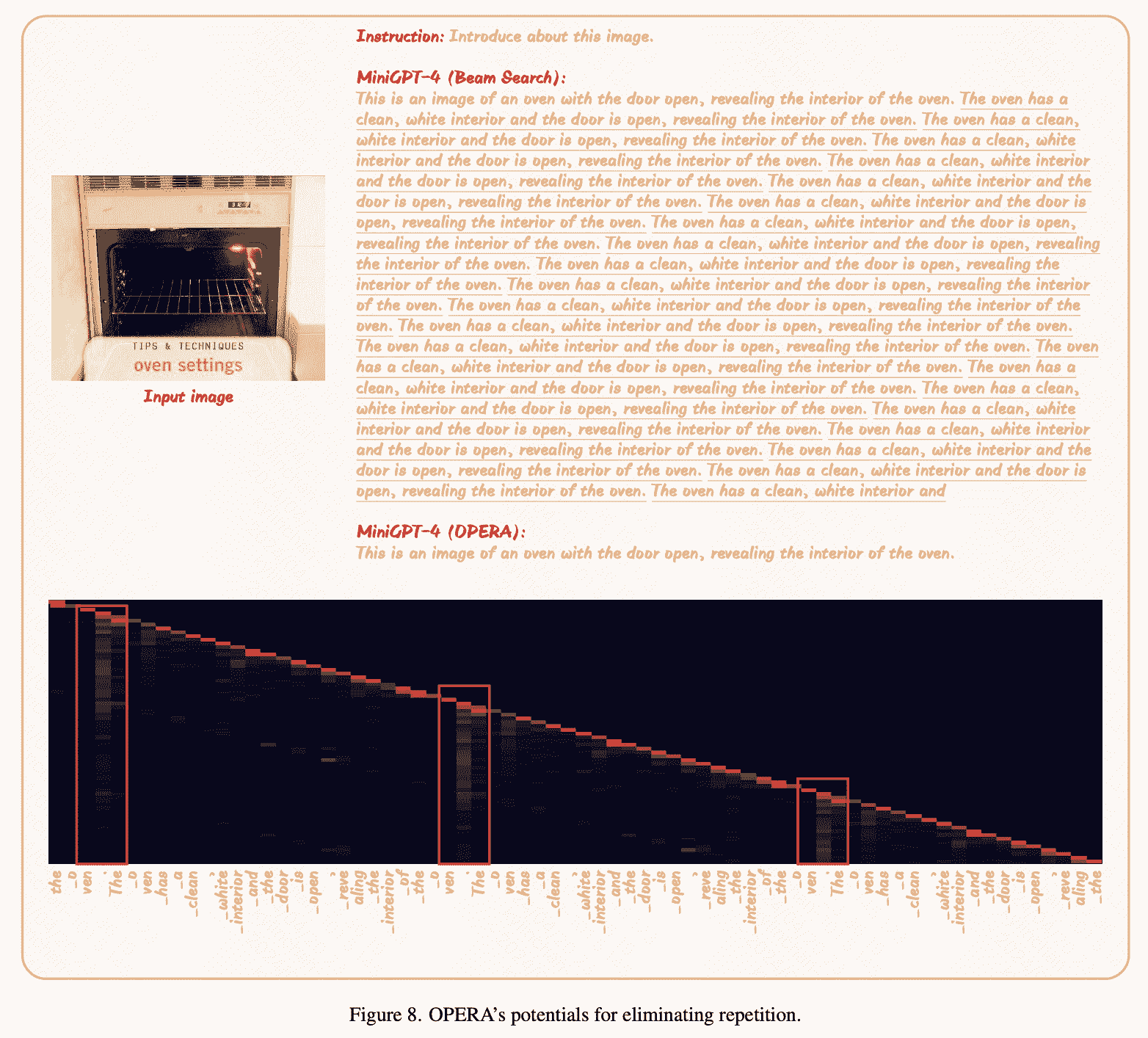
Limitation
1)在处理幻觉的多样性上存在不足,因为作者认为很多case的失败是在于pretrain时候的问题,以及MLLM视觉上的不足。
2)在处理短序列幻觉不足,因为这个工作的metrics存在滞后性。
Reference
-
Label words are anchors: An information flow perspective for understanding in- context learning. https://arxiv.org/abs/2305.14160 ↩
-
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James Glass, and Pengcheng He. Dola: Decoding by con- trasting layers improves factuality in large language models. arXiv preprint arXiv:2309.03883, 2023. 4, 6 ↩