[TOC]
看了下网络的代码分析,大多集中在推理端代码分析,而忽略了blip2qformer的训练代码,因此来分析一下:
Inference(or stage-2)
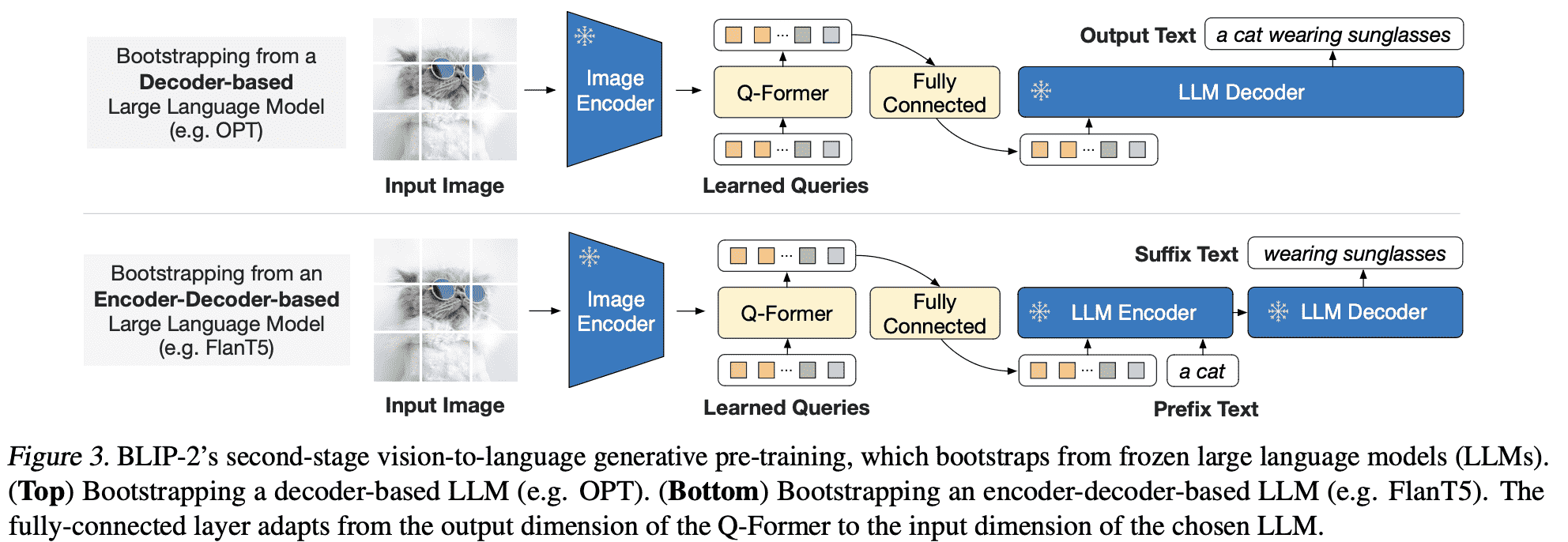
网络上分析的代码多是推理端的,blip2在做推理的时候,只有图像一侧的block起作用,相对来说流程上是比较简单的,即过N个Blip2QFormerLayer输出的learnable tokens作为图像特征,过mlp之后直接作为大模型输入的前缀embedding,代码及关键注释如下1:
class Blip2QFormerLayer(nn.Module):
def __init__(self, config, layer_idx):
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.attention = Blip2QFormerAttention(config)
self.layer_idx = layer_idx
if layer_idx % config.cross_attention_frequency == 0: #用来控制cross attention每间隔几个层出现一次
self.crossattention = Blip2QFormerAttention(config, is_cross_attention=True) #是否为cross attention就是一个boolean型变量决定
self.has_cross_attention = True
else:
self.has_cross_attention = False
self.intermediate_query = Blip2QFormerIntermediate(config)
self.output_query = Blip2QFormerOutput(config)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
query_length=0,
):
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
#第一个self-attention
self_attention_outputs = self.attention(
hidden_states,
attention_mask,
head_mask,
output_attentions=output_attentions,
past_key_value=self_attn_past_key_value,
)
attention_output = self_attention_outputs[0]
outputs = self_attention_outputs[1:-1]
present_key_value = self_attention_outputs[-1]
if query_length > 0:
query_attention_output = attention_output[:, :query_length, :]
if self.has_cross_attention:
#cross-attention,必须满足有query且self.has_cross_attention
if encoder_hidden_states is None:
raise ValueError("encoder_hidden_states must be given for cross-attention layers")
cross_attention_outputs = self.crossattention(
query_attention_output,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
output_attentions=output_attentions,
)
query_attention_output = cross_attention_outputs[0]
# add cross attentions if we output attention weights
outputs = outputs + cross_attention_outputs[1:-1]
layer_output = apply_chunking_to_forward(
self.feed_forward_chunk_query,
self.chunk_size_feed_forward,
self.seq_len_dim,
query_attention_output,
)
if attention_output.shape[1] > query_length:
layer_output_text = apply_chunking_to_forward(
self.feed_forward_chunk,
self.chunk_size_feed_forward,
self.seq_len_dim,
attention_output[:, query_length:, :],
)
layer_output = torch.cat([layer_output, layer_output_text], dim=1)
else:
layer_output = apply_chunking_to_forward(
self.feed_forward_chunk,
self.chunk_size_feed_forward,
self.seq_len_dim,
attention_output,
)
outputs = (layer_output,) + outputs
outputs = outputs + (present_key_value,)
return outputs
def feed_forward_chunk(self, attention_output):
intermediate_output = self.intermediate(attention_output)
layer_output = self.output(intermediate_output, attention_output)
return layer_output
def feed_forward_chunk_query(self, attention_output):
intermediate_output = self.intermediate_query(attention_output)
layer_output = self.output_query(intermediate_output, attention_output)
return layer_output
在官方实现的LAVIS中也有这一个Qformerblocks2:
class BertLayer(nn.Module):
def __init__(self, config, layer_num):
super().__init__()
self.config = config
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.attention = BertAttention(config)
self.layer_num = layer_num
if (
self.config.add_cross_attention
and layer_num % self.config.cross_attention_freq == 0
):
self.crossattention = BertAttention(
config, is_cross_attention=self.config.add_cross_attention
)
self.has_cross_attention = True
else:
self.has_cross_attention = False
self.intermediate = BertIntermediate(config)
self.output = BertOutput(config)
self.intermediate_query = BertIntermediate(config)
self.output_query = BertOutput(config)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
query_length=0,
):
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = (
past_key_value[:2] if past_key_value is not None else None
)
self_attention_outputs = self.attention(
hidden_states,
attention_mask,
head_mask,
output_attentions=output_attentions,
past_key_value=self_attn_past_key_value,
)
attention_output = self_attention_outputs[0]
outputs = self_attention_outputs[1:-1]
present_key_value = self_attention_outputs[-1]
if query_length > 0:
query_attention_output = attention_output[:, :query_length, :]
if self.has_cross_attention:
assert (
encoder_hidden_states is not None
), "encoder_hidden_states must be given for cross-attention layers"
cross_attention_outputs = self.crossattention(
query_attention_output,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
output_attentions=output_attentions,
)
query_attention_output = cross_attention_outputs[0]
outputs = (
outputs + cross_attention_outputs[1:-1]
) # add cross attentions if we output attention weights
layer_output = apply_chunking_to_forward(
self.feed_forward_chunk_query,
self.chunk_size_feed_forward,
self.seq_len_dim,
query_attention_output,
)
if attention_output.shape[1] > query_length:
layer_output_text = apply_chunking_to_forward(
self.feed_forward_chunk,
self.chunk_size_feed_forward,
self.seq_len_dim,
attention_output[:, query_length:, :],
)
layer_output = torch.cat([layer_output, layer_output_text], dim=1)
else:
layer_output = apply_chunking_to_forward(
self.feed_forward_chunk,
self.chunk_size_feed_forward,
self.seq_len_dim,
attention_output,
)
outputs = (layer_output,) + outputs
outputs = outputs + (present_key_value,)
return outputs
def feed_forward_chunk(self, attention_output):
intermediate_output = self.intermediate(attention_output)
layer_output = self.output(intermediate_output, attention_output)
return layer_output
def feed_forward_chunk_query(self, attention_output):
intermediate_output = self.intermediate_query(attention_output)
layer_output = self.output_query(intermediate_output, attention_output)
return layer_output
Q:为什么Qformer连接到LLM需要线性层?
论文图片上的注脚原文:The fully-connected layer adapts from the output dimension of the Q-Former to the input dimension of the chosen LLM.
但是事实上我觉得这个MLP是起到模态对齐和融合作用的,毕竟qformer提取出的learnable和stage-2的文本信息可能存在分布上的差异。
Q:为什么stage-2要放开Qformer的训练?
我看到这个问题很多博主是笼统的说“只训练MLP”,其实Qformer是一起训练的,一是参考图片上没有forzen符号;二是可以看blip2opt的代码3,是没有frozen qformer的:
@registry.register_model("blip2_opt")
class Blip2OPT(Blip2Base):
"""
BLIP2 OPT model.
Supported model types:
- pretrained_opt2.7b: pretrained model with OPT2.7b
- pretrained_opt6.7b: pretrained model with OPT6.7b
- caption_coco_opt2.7b: fintuned image captioning model with OPT2.7b
- caption_coco_opt6.7b: fintuned image captioning model with OPT6.7b
Usage:
>>> from lavis.models import load_model
>>> model = load_model("blip2_opt", "caption_coco_opt2.7b")
"""
PRETRAINED_MODEL_CONFIG_DICT = {
"pretrain_opt2.7b": "configs/models/blip2/blip2_pretrain_opt2.7b.yaml",
"pretrain_opt6.7b": "configs/models/blip2/blip2_pretrain_opt6.7b.yaml",
"caption_coco_opt2.7b": "configs/models/blip2/blip2_caption_opt2.7b.yaml",
"caption_coco_opt6.7b": "configs/models/blip2/blip2_caption_opt6.7b.yaml",
}
def __init__(
self,
vit_model="eva_clip_g",
img_size=224,
drop_path_rate=0,
use_grad_checkpoint=False,
vit_precision="fp16",
freeze_vit=True,
num_query_token=32,
opt_model="facebook/opt-2.7b",
prompt="",
max_txt_len=32,
apply_lemmatizer=False,
):
"""
apply_lemmatizer: when set to True, postprocess predict_answers() result with lemmas.
"""
super().__init__()
transformers_version = version.parse(transformers.__version__)
assert transformers_version >= version.parse("4.27"), "BLIP-2 OPT requires transformers>=4.27"
self.tokenizer = self.init_tokenizer()
self.visual_encoder, self.ln_vision = self.init_vision_encoder(
vit_model, img_size, drop_path_rate, use_grad_checkpoint, vit_precision
)
if freeze_vit:
for name, param in self.visual_encoder.named_parameters():
param.requires_grad = False
self.visual_encoder = self.visual_encoder.eval()
self.visual_encoder.train = disabled_train
logging.info("freeze vision encoder")
self.Qformer, self.query_tokens = self.init_Qformer(
num_query_token, self.visual_encoder.num_features
)
self.Qformer.cls = None
self.Qformer.bert.embeddings.word_embeddings = None
self.Qformer.bert.embeddings.position_embeddings = None
for layer in self.Qformer.bert.encoder.layer:
# 这里是去除文本bert的FFN
layer.output = None
layer.intermediate = None
self.opt_tokenizer = AutoTokenizer.from_pretrained(opt_model, use_fast=False)
self.opt_model = OPTForCausalLM.from_pretrained(
opt_model, torch_dtype=torch.float16
)
for name, param in self.opt_model.named_parameters():
param.requires_grad = False
self.eos_token_id = self.opt_tokenizer(
"\n", add_special_tokens=False
).input_ids[0]
self.opt_proj = nn.Linear(
self.Qformer.config.hidden_size, self.opt_model.config.hidden_size
)
self.max_txt_len = max_txt_len
self.prompt = prompt
prompt_tokens = self.opt_tokenizer(self.prompt, return_tensors="pt")
self.prompt_length = prompt_tokens.attention_mask.sum(1)
self._apply_lemmatizer = apply_lemmatizer
self._lemmatizer = None
至于为什么要放开,我的理解是弥合qformer对齐数据和stage-2的文本数据的分布差异,并且放开qformer会增加灵活性。
Train(stage-1)
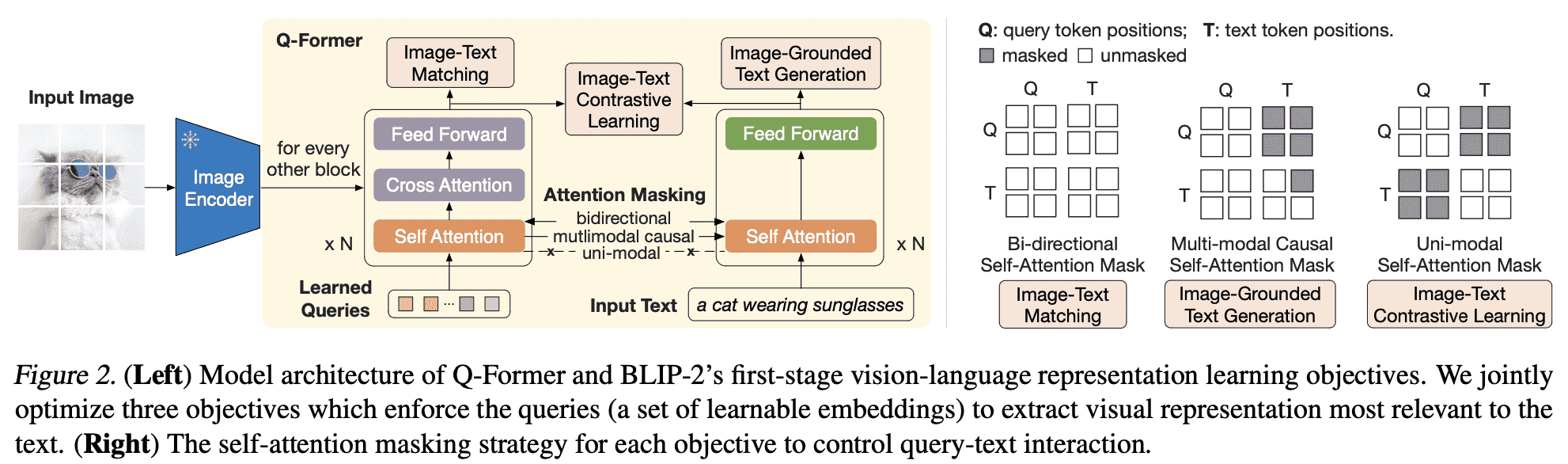
Qformer的训练(stage-1)会比推理端(or stage-2)要复杂,因为涉及到三个训练任务,我们逐步以QA的形式讲解:
Q:三个训练任务是怎么安排的?
这里的三个任务是并列的,没有依赖关系,也没有在ITM上采取hard negtive策略(而是对每一个正样本随机采样一个负样本),最后的loss是三个任务的loss简单加和。
class Blip2Qformer(Blip2Base):
...
def forward(self, samples):
image = samples["image"]
text = samples["text_input"]
image_embeds = self.ln_vision(self.visual_encoder(image))
image_atts = torch.ones(image_embeds.size()[:-1], dtype=torch.long).to(
image.device
)
query_tokens = self.query_tokens.expand(image_embeds.shape[0], -1, -1)
query_output = self.Qformer.bert(
query_embeds=query_tokens,
encoder_hidden_states=image_embeds,
encoder_attention_mask=image_atts,
use_cache=True,
return_dict=True,
)
image_feats = F.normalize(
self.vision_proj(query_output.last_hidden_state), dim=-1
)
text_tokens = self.tokenizer(
text,
padding="max_length",
truncation=True,
max_length=self.max_txt_len,
return_tensors="pt",
).to(image.device)
text_output = self.Qformer.bert(
text_tokens.input_ids,
attention_mask=text_tokens.attention_mask,
return_dict=True,
)
text_feat = F.normalize(
self.text_proj(text_output.last_hidden_state[:, 0, :]), dim=-1
)
###============== Image-text Contrastive ===================###
image_feats_all = concat_all_gather(
image_feats
) # [batch_size*num_gpu, num_query_tokens, embed_dim]
text_feat_all = concat_all_gather(text_feat) # [batch_size*num_gpu, embed_dim]
sim_q2t = torch.matmul(
image_feats.unsqueeze(1), text_feat_all.unsqueeze(-1)
).squeeze()
# [batch_size, batch_size*num_gpu, num_query_tokens]
# image-text similarity: aggregate across all query tokens
sim_i2t, _ = sim_q2t.max(-1)
sim_i2t = sim_i2t / self.temp
# text-query similarity: [batch_size, batch_size*num_gpu, num_query_tokens]
sim_t2q = torch.matmul(
text_feat.unsqueeze(1).unsqueeze(1), image_feats_all.permute(0, 2, 1)
).squeeze()
# text-image similarity: aggregate across all query tokens
sim_t2i, _ = sim_t2q.max(-1)
sim_t2i = sim_t2i / self.temp # [batch_size, batch_size*num_gpu]
rank = dist.get_rank()
bs = image.size(0)
targets = torch.linspace(rank * bs, rank * bs + bs - 1, bs, dtype=int).to(
image.device
)
if "image_id" in samples.keys(): #coco retrieval finetuning
image_ids = samples["image_id"].view(-1,1)
image_ids_all = concat_all_gather(image_ids)
pos_idx = torch.eq(image_ids, image_ids_all.t()).float()
sim_targets = pos_idx / pos_idx.sum(1,keepdim=True)
sim_targets = 0.9 * sim_targets + 0.1 * torch.ones_like(sim_targets) / sim_targets.size(1)
loss_t2i = -torch.sum(F.log_softmax(sim_t2i, dim=1)*sim_targets,dim=1).mean()
loss_i2t = -torch.sum(F.log_softmax(sim_i2t, dim=1)*sim_targets,dim=1).mean()
loss_itc = (loss_t2i+loss_i2t)/2
else:
loss_itc = (
F.cross_entropy(sim_i2t, targets, label_smoothing=0.1)
+ F.cross_entropy(sim_t2i, targets, label_smoothing=0.1)
) / 2
###============== Image-text Matching ===================###
text_input_ids_world = concat_all_gather(text_tokens.input_ids)
text_attention_mask_world = concat_all_gather(text_tokens.attention_mask)
image_embeds_world = all_gather_with_grad(image_embeds)
with torch.no_grad():
if "image_id" in samples.keys():
mask = torch.eq(image_ids, image_ids_all.t())
sim_t2i.masked_fill_(mask, -10000)
sim_i2t.masked_fill_(mask, -10000)
else:
sim_t2i[:, rank * bs : rank * bs + bs].fill_diagonal_(-10000)
sim_i2t[:, rank * bs : rank * bs + bs].fill_diagonal_(-10000)
weights_t2i = F.softmax(sim_t2i, dim=1)
weights_i2t = F.softmax(sim_i2t, dim=1)
# select a negative image for each text
image_embeds_neg = []
for b in range(bs):
neg_idx = torch.multinomial(weights_t2i[b], 1).item()
image_embeds_neg.append(image_embeds_world[neg_idx])
image_embeds_neg = torch.stack(image_embeds_neg, dim=0)
# select a negative text for each image
text_ids_neg = []
text_atts_neg = []
for b in range(bs):
neg_idx = torch.multinomial(weights_i2t[b], 1).item()
text_ids_neg.append(text_input_ids_world[neg_idx])
text_atts_neg.append(text_attention_mask_world[neg_idx])
text_ids_neg = torch.stack(text_ids_neg, dim=0)
text_atts_neg = torch.stack(text_atts_neg, dim=0)
text_ids_all = torch.cat(
[text_tokens.input_ids, text_tokens.input_ids, text_ids_neg], dim=0
) # pos, pos, neg
text_atts_all = torch.cat(
[text_tokens.attention_mask, text_tokens.attention_mask, text_atts_neg],
dim=0,
)
query_tokens_itm = self.query_tokens.expand(text_ids_all.shape[0], -1, -1)
query_atts_itm = torch.ones(query_tokens_itm.size()[:-1], dtype=torch.long).to(
image.device
)
attention_mask_all = torch.cat([query_atts_itm, text_atts_all], dim=1)
image_embeds_all = torch.cat(
[image_embeds, image_embeds_neg, image_embeds], dim=0
) # pos, neg, pos
image_atts_all = torch.ones(image_embeds_all.size()[:-1], dtype=torch.long).to(
image.device
)
output_itm = self.Qformer.bert(
text_ids_all,
query_embeds=query_tokens_itm,
attention_mask=attention_mask_all,
encoder_hidden_states=image_embeds_all,
encoder_attention_mask=image_atts_all,
return_dict=True,
)
vl_embeddings = output_itm.last_hidden_state[:, : query_tokens_itm.size(1), :]
vl_output = self.itm_head(vl_embeddings)
logits = vl_output.mean(dim=1)
itm_labels = torch.cat(
[torch.ones(bs, dtype=torch.long), torch.zeros(2 * bs, dtype=torch.long)],
dim=0,
).to(image.device)
loss_itm = F.cross_entropy(logits, itm_labels)
##================= Image Captioning ========================##
decoder_input_ids = text_tokens.input_ids.clone()
decoder_input_ids[:, 0] = self.tokenizer.bos_token_id
labels = decoder_input_ids.masked_fill(
decoder_input_ids == self.tokenizer.pad_token_id, -100
)
query_atts = torch.ones(query_tokens.size()[:-1], dtype=torch.long).to(
image.device
)
attention_mask = torch.cat([query_atts, text_tokens.attention_mask], dim=1)
lm_output = self.Qformer(
decoder_input_ids,
attention_mask=attention_mask,
past_key_values=query_output.past_key_values,
return_dict=True,
labels=labels,
)
loss_lm = lm_output.loss
return BlipOutput(
loss=loss_itc + loss_itm + loss_lm,
loss_itc=loss_itc,
loss_itm=loss_itm,
loss_lm=loss_lm,
)
Q:在代码上的Qformer是怎么实现的?共享Self-att是怎么实现的?
Qformer是一个特殊修改后的bert模型4:
class BertLMHeadModel(BertPreTrainedModel):
_keys_to_ignore_on_load_unexpected = [r"pooler"]
_keys_to_ignore_on_load_missing = [r"position_ids", r"predictions.decoder.bias"]
def __init__(self, config):
super().__init__(config)
self.bert = BertModel(config, add_pooling_layer=False)
self.cls = BertOnlyMLMHead(config)
self.init_weights()
......
这个bert模型特殊的地方在于有一个cross attention层,以及两个FFN;
Q:Qformer内部特征的维度是怎么对齐的?
全部hidden_dim设为vision的dim5,从而实现统一。
......
def init_Qformer(cls, num_query_token, vision_width, cross_attention_freq=2):
encoder_config = BertConfig.from_pretrained("bert-base-uncased")
encoder_config.encoder_width = vision_width
# insert cross-attention layer every other block
encoder_config.add_cross_attention = True
encoder_config.cross_attention_freq = cross_attention_freq
encoder_config.query_length = num_query_token
Qformer = BertLMHeadModel.from_pretrained(
"bert-base-uncased", config=encoder_config
)
......
Reference
-
https://github.com/huggingface/transformers/blob/main/src/transformers/models/blip_2/modeling_blip_2.py ↩
-
https://github.com/salesforce/LAVIS/blob/main/lavis/models/blip2_models/Qformer.py#L378 ↩
-
https://github.com/salesforce/LAVIS/blob/main/lavis/models/blip2_models/blip2_opt.py ↩
-
https://github.com/salesforce/LAVIS/blob/main/lavis/models/blip2_models/Qformer.py#L968 ↩
-
https://github.com/salesforce/LAVIS/blob/main/lavis/models/blip2_models/blip2.py ↩